 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumos: Efficient Performance Modeling and Estimation for Large-scale LLM Training
Apr 12, 2025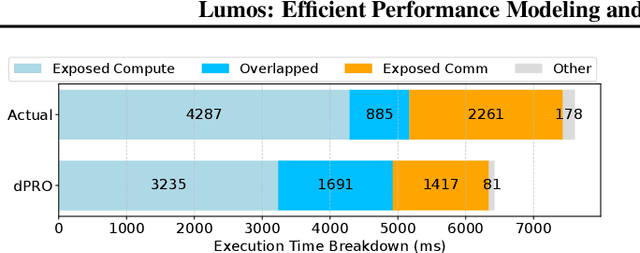
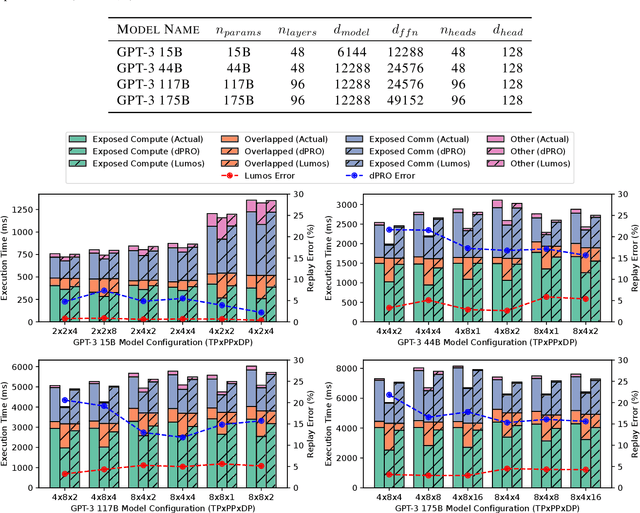
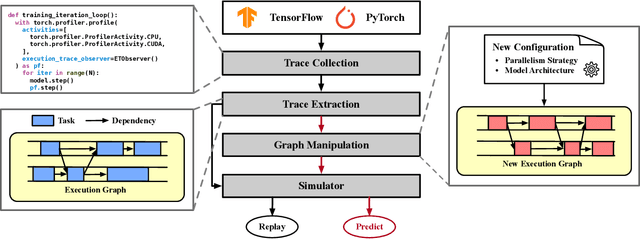
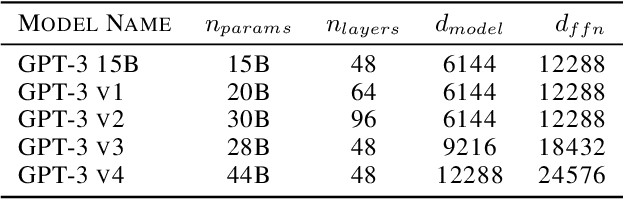
Training LLMs in distributed environments presents significant challenges due to the complexity of model execution, deployment systems, and the vast space of configurable strategies. Although various optimization techniques exist, achieving high efficiency in practice remains difficult. Accurate performance models that effectively characterize and predict a model's behavior are essential for guiding optimization efforts and system-level studies. We propose Lumos, a trace-driven performance modeling and estimation toolkit for large-scale LLM training, designed to accurately capture and predict the execution behaviors of modern LLMs. We evaluate Lumos on a production ML cluster with up to 512 NVIDIA H100 GPUs using various GPT-3 variants, demonstrating that it can replay execution time with an average error of just 3.3%, along with other runtime details, across different models and configurations. Additionally, we validate its ability to estimate performance for new setups from existing traces, facilitating efficient exploration of model and deployment configurations.
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Apr 19, 2024



Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
May 26, 2023



Benchmarking and co-design are essential for driving optimizations and innovation around ML models, ML software, and next-generation hardware. Full workload benchmarks, e.g. MLPerf, play an essential role in enabling fair comparison across different software and hardware stacks especially once systems are fully designed and deployed. However, the pace of AI innovation demands a more agile methodology to benchmark creation and usage by simulators and emulators for future system co-design. We propose Chakra, an open graph schema for standardizing workload specification capturing key operations and dependencies, also known as Execution Trace (ET). In addition, we propose a complementary set of tools/capabilities to enable collection, generation, and adoption of Chakra ETs by a wide range of simulators, emulators, and benchmarks. For instance, we use generative AI models to learn latent statistical properties across thousands of Chakra ETs and use these models to synthesize Chakra ETs. These synthetic ETs can obfuscate key proprietary information and also target future what-if scenarios. As an example, we demonstrate an end-to-end proof-of-concept that converts PyTorch ETs to Chakra ETs and uses this to drive an open-source training system simulator (ASTRA-sim). Our end-goal is to build a vibrant industry-wide ecosystem of agile benchmarks and tools to drive future AI system co-design.
Pre-train and Search: Efficient Embedding Table Sharding with Pre-trained Neural Cost Models
May 03, 2023



Sharding a large machine learning model across multiple devices to balance the costs is important in distributed training. This is challenging because partitioning is NP-hard, and estimating the costs accurately and efficiently is difficult. In this work, we explore a "pre-train, and search" paradigm for efficient sharding. The idea is to pre-train a universal and once-for-all neural network to predict the costs of all the possible shards, which serves as an efficient sharding simulator. Built upon this pre-trained cost model, we then perform an online search to identify the best sharding plans given any specific sharding task. We instantiate this idea in deep learning recommendation models (DLRMs) and propose NeuroShard for embedding table sharding. NeuroShard pre-trains neural cost models on augmented tables to cover various sharding scenarios. Then it identifies the best column-wise and table-wise sharding plans with beam search and greedy grid search, respectively. Experiments show that NeuroShard significantly and consistently outperforms the state-of-the-art on the benchmark sharding dataset, achieving up to 23.8% improvement. When deployed in an ultra-large production DLRM with multi-terabyte embedding tables, NeuroShard achieves 11.6% improvement in embedding costs over the state-of-the-art, which translates to 6.6% end-to-end training throughput improvement. To facilitate future research of the "pre-train, and search" paradigm in ML for Systems, we open-source our code at https://github.com/daochenzha/neuroshard
Mystique: Accurate and Scalable Production AI Benchmarks Generation
Dec 16, 2022



Building and maintaining large AI fleets to efficiently support the fast-growing DL workloads is an active research topic for modern cloud infrastructure providers. Generating accurate benchmarks plays an essential role in the design and evaluation of rapidly evoloving software and hardware solutions in this area. Two fundamental challenges to make this process scalable are (i) workload representativeness and (ii) the ability to quickly incorporate changes to the fleet into the benchmarks. To overcome these issues, we propose Mystique, an accurate and scalable framework for production AI benchmark generation. It leverages the PyTorch execution graph (EG), a new feature that captures the runtime information of AI models at the granularity of operators, in a graph format, together with their metadata. By sourcing EG traces from the fleet, we can build AI benchmarks that are portable and representative. Mystique is scalable, with its lightweight data collection, in terms of runtime overhead and user instrumentation efforts. It is also adaptive, as the expressiveness and composability of EG format allows flexible user control over benchmark creation. We evaluate our methodology on several production AI workloads, and show that benchmarks generated with Mystique closely resemble original AI models, both in execution time and system-level metrics. We also showcase the portability of the generated benchmarks across platforms, and demonstrate several use cases enabled by the fine-grained composability of the execution graph.
DreamShard: Generalizable Embedding Table Placement for Recommender Systems
Oct 05, 2022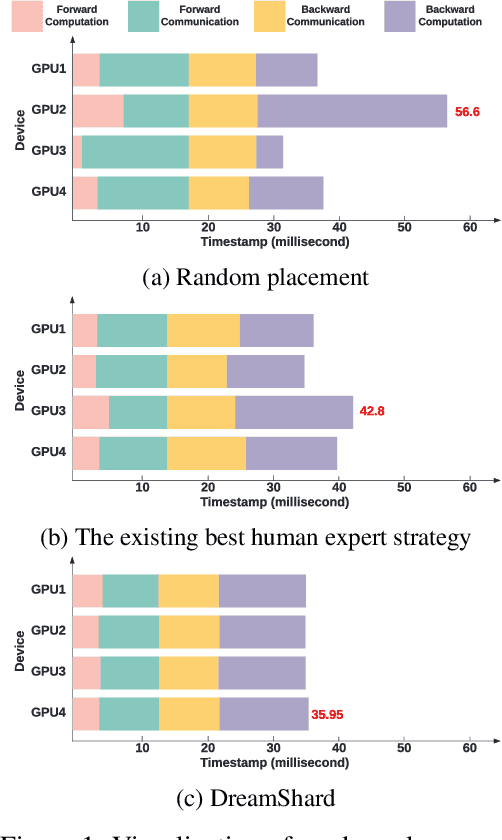
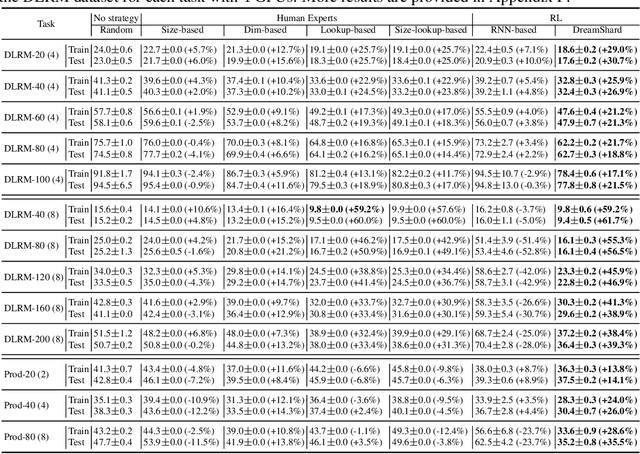
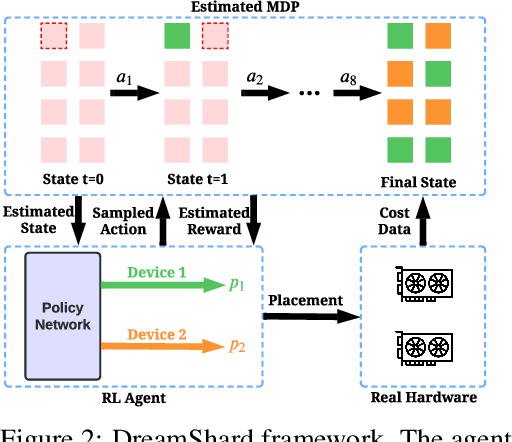
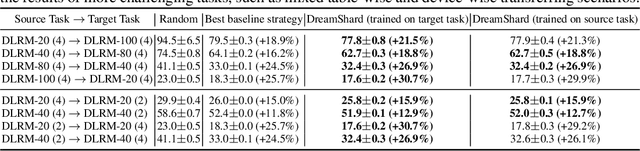
We study embedding table placement for distributed recommender systems, which aims to partition and place the tables on multiple hardware devices (e.g., GPUs) to balance the computation and communication costs. Although prior work has explored learning-based approaches for the device placement of computational graphs, embedding table placement remains to be a challenging problem because of 1) the operation fusion of embedding tables, and 2) the generalizability requirement on unseen placement tasks with different numbers of tables and/or devices. To this end, we present DreamShard, a reinforcement learning (RL) approach for embedding table placement. DreamShard achieves the reasoning of operation fusion and generalizability with 1) a cost network to directly predict the costs of the fused operation, and 2) a policy network that is efficiently trained on an estimated Markov decision process (MDP) without real GPU execution, where the states and the rewards are estimated with the cost network. Equipped with sum and max representation reductions, the two networks can directly generalize to any unseen tasks with different numbers of tables and/or devices without fine-tuning. Extensive experiments show that DreamShard substantially outperforms the existing human expert and RNN-based strategies with up to 19% speedup over the strongest baseline on large-scale synthetic tables and our production tables. The code is available at https://github.com/daochenzha/dreamshard
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022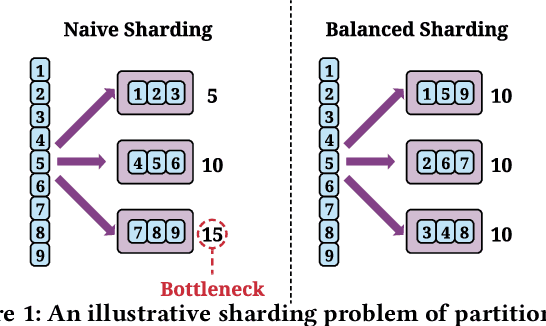
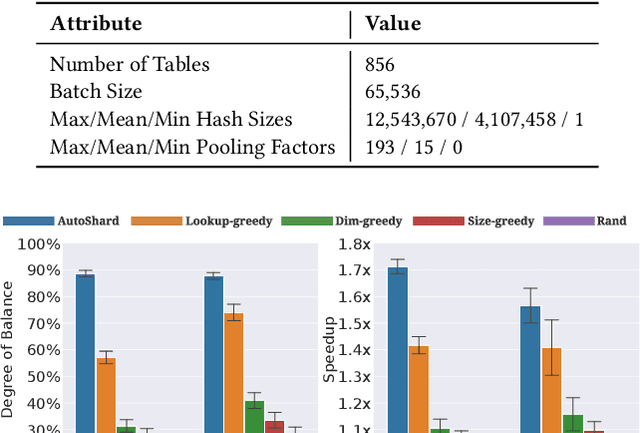

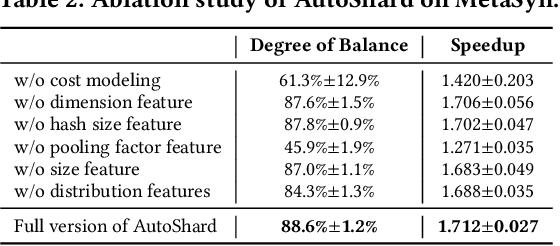
Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard
Building a Performance Model for Deep Learning Recommendation Model Training on GPUs
Jan 19, 2022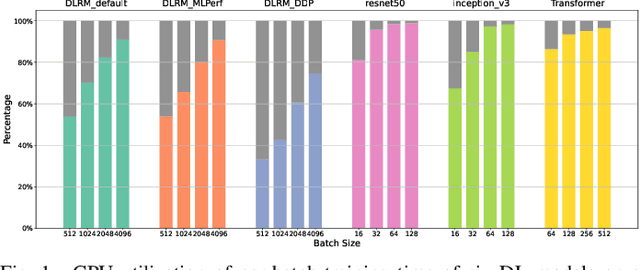
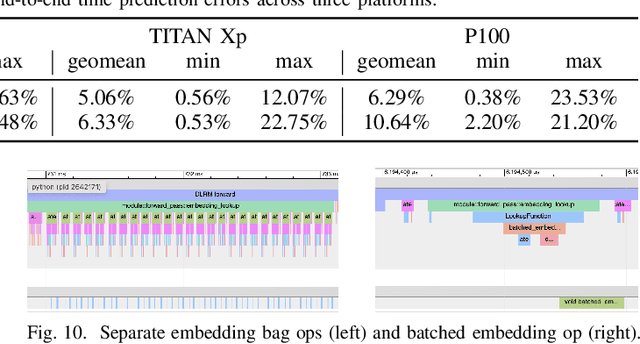

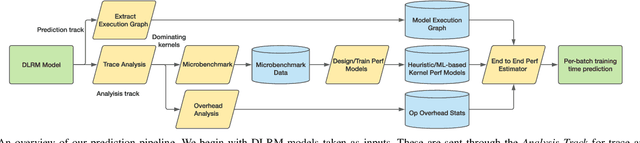
We devise a performance model for GPU training of Deep Learning Recommendation Models (DLRM), whose GPU utilization is low compared to other well-optimized CV and NLP models. We show that both the device active time (the sum of kernel runtimes) and the device idle time are important components of the overall device time. We therefore tackle them separately by (1) flexibly adopting heuristic-based and ML-based kernel performance models for operators that dominate the device active time, and (2) categorizing operator overheads into five types to determine quantitatively their contribution to the device active time. Combining these two parts, we propose a critical-path-based algorithm to predict the per-batch training time of DLRM by traversing its execution graph. We achieve less than 10% geometric mean average error (GMAE) in all kernel performance modeling, and 5.23% and 7.96% geomean errors for GPU active time and overall end-to-end per-batch training time prediction, respectively. We show that our general performance model not only achieves low prediction error on DLRM, which has highly customized configurations and is dominated by multiple factors, but also yields comparable accuracy on other compute-bound ML models targeted by most previous methods. Using this performance model and graph-level data and task dependency analyses, we show our system can provide more general model-system co-design than previous methods.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021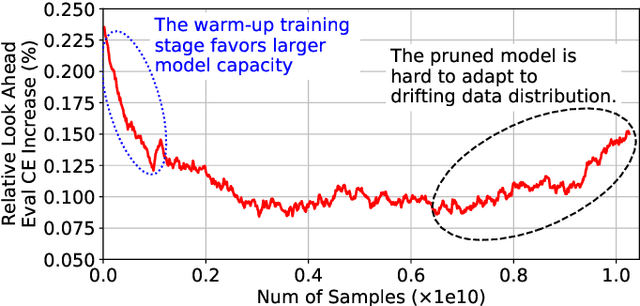
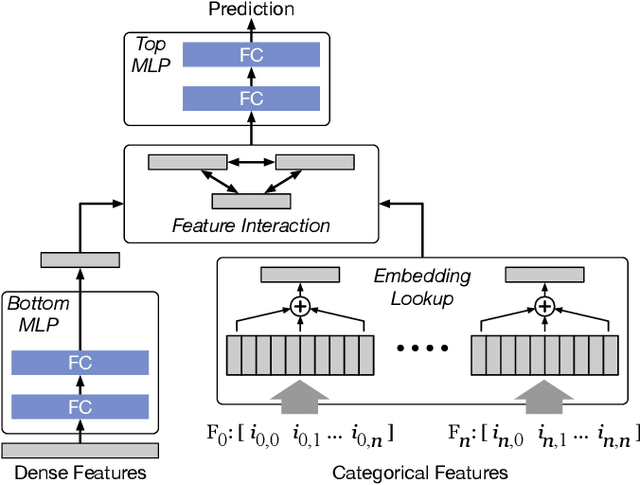
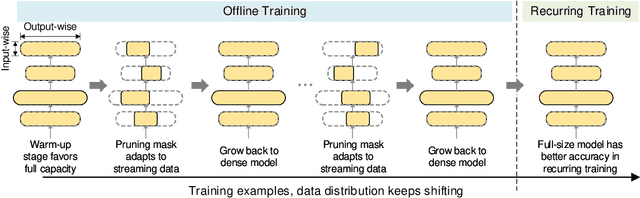
Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.