 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Apr 19, 2024



Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Mystique: Accurate and Scalable Production AI Benchmarks Generation
Dec 16, 2022



Building and maintaining large AI fleets to efficiently support the fast-growing DL workloads is an active research topic for modern cloud infrastructure providers. Generating accurate benchmarks plays an essential role in the design and evaluation of rapidly evoloving software and hardware solutions in this area. Two fundamental challenges to make this process scalable are (i) workload representativeness and (ii) the ability to quickly incorporate changes to the fleet into the benchmarks. To overcome these issues, we propose Mystique, an accurate and scalable framework for production AI benchmark generation. It leverages the PyTorch execution graph (EG), a new feature that captures the runtime information of AI models at the granularity of operators, in a graph format, together with their metadata. By sourcing EG traces from the fleet, we can build AI benchmarks that are portable and representative. Mystique is scalable, with its lightweight data collection, in terms of runtime overhead and user instrumentation efforts. It is also adaptive, as the expressiveness and composability of EG format allows flexible user control over benchmark creation. We evaluate our methodology on several production AI workloads, and show that benchmarks generated with Mystique closely resemble original AI models, both in execution time and system-level metrics. We also showcase the portability of the generated benchmarks across platforms, and demonstrate several use cases enabled by the fine-grained composability of the execution graph.
Building a Performance Model for Deep Learning Recommendation Model Training on GPUs
Jan 19, 2022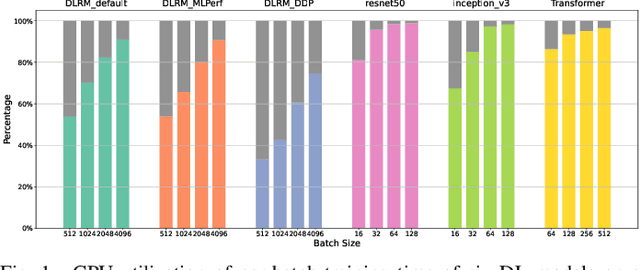
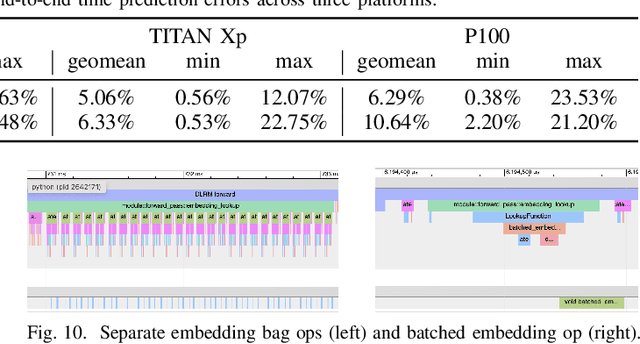

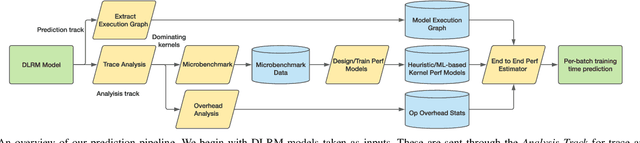
We devise a performance model for GPU training of Deep Learning Recommendation Models (DLRM), whose GPU utilization is low compared to other well-optimized CV and NLP models. We show that both the device active time (the sum of kernel runtimes) and the device idle time are important components of the overall device time. We therefore tackle them separately by (1) flexibly adopting heuristic-based and ML-based kernel performance models for operators that dominate the device active time, and (2) categorizing operator overheads into five types to determine quantitatively their contribution to the device active time. Combining these two parts, we propose a critical-path-based algorithm to predict the per-batch training time of DLRM by traversing its execution graph. We achieve less than 10% geometric mean average error (GMAE) in all kernel performance modeling, and 5.23% and 7.96% geomean errors for GPU active time and overall end-to-end per-batch training time prediction, respectively. We show that our general performance model not only achieves low prediction error on DLRM, which has highly customized configurations and is dominated by multiple factors, but also yields comparable accuracy on other compute-bound ML models targeted by most previous methods. Using this performance model and graph-level data and task dependency analyses, we show our system can provide more general model-system co-design than previous methods.