 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolytope Volume Monitoring Problem: Formulation and Solution via Parametric Linear Program Based Control Barrier Function
Mar 16, 2025Motivated by the latest research on feasible space monitoring of multiple control barrier functions (CBFs) as well as polytopic collision avoidance, this paper studies the Polytope Volume Monitoring (PVM) problem, whose goal is to design a control law for inputs of nonlinear systems to prevent the volume of some state-dependent polytope from decreasing to zero. Recent studies have explored the idea of applying Chebyshev ball method in optimization theory to solve the case study of PVM; however, the underlying difficulties caused by nonsmoothness have not been addressed. This paper continues the study on this topic, where our main contribution is to establish the relationship between nonsmooth CBF and parametric optimization theory through directional derivatives for the first time, so as to solve PVM problems more conveniently. In detail, inspired by Chebyshev ball approach, a parametric linear program (PLP) based nonsmooth barrier function candidate is established for PVM, and then, sufficient conditions for it to be a nonsmooth CBF are proposed, based on which a quadratic program (QP) based safety filter with guaranteed feasibility is proposed to address PVM problems. Finally, a numerical simulation example is given to show the efficiency of the proposed safety filter.
Optimization-free Smooth Control Barrier Function for Polygonal Collision Avoidance
Feb 22, 2025Polygonal collision avoidance (PCA) is short for the problem of collision avoidance between two polygons (i.e., polytopes in planar) that own their dynamic equations. This problem suffers the inherent difficulty in dealing with non-smooth boundaries and recently optimization-defined metrics, such as signed distance field (SDF) and its variants, have been proposed as control barrier functions (CBFs) to tackle PCA problems. In contrast, we propose an optimization-free smooth CBF method in this paper, which is computationally efficient and proved to be nonconservative. It is achieved by three main steps: a lower bound of SDF is expressed as a nested Boolean logic composition first, then its smooth approximation is established by applying the latest log-sum-exp method, after which a specified CBF-based safety filter is proposed to address this class of problems. To illustrate its wide applications, the optimization-free smooth CBF method is extended to solve distributed collision avoidance of two underactuated nonholonomic vehicles and drive an underactuated container crane to avoid a moving obstacle respectively, for which numerical simulations are also performed.
Non-stationary BERT: Exploring Augmented IMU Data For Robust Human Activity Recognition
Sep 25, 2024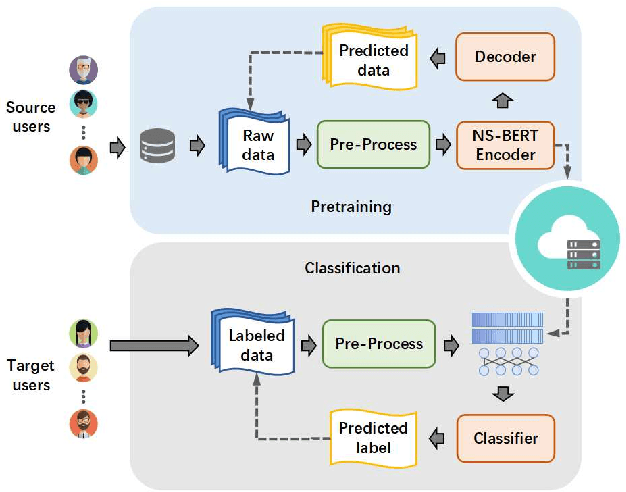
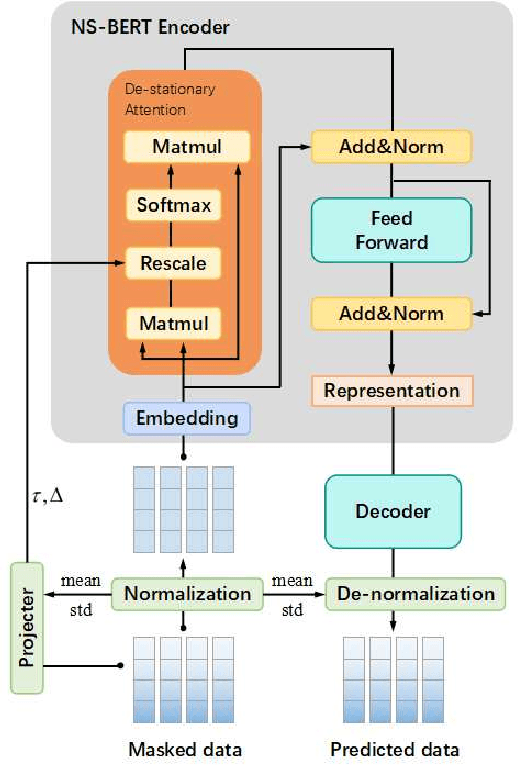
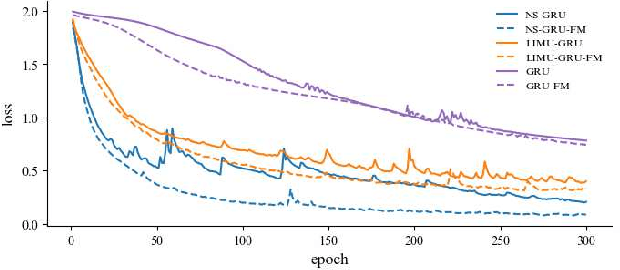

Human Activity Recognition (HAR) has gained great attention from researchers due to the popularity of mobile devices and the need to observe users' daily activity data for better human-computer interaction. In this work, we collect a human activity recognition dataset called OPPOHAR consisting of phone IMU data. To facilitate the employment of HAR system in mobile phone and to achieve user-specific activity recognition, we propose a novel light-weight network called Non-stationary BERT with a two-stage training method. We also propose a simple yet effective data augmentation method to explore the deeper relationship between the accelerator and gyroscope data from the IMU. The network achieves the state-of-the-art performance testing on various activity recognition datasets and the data augmentation method demonstrates its wide applicability.
ADFQ-ViT: Activation-Distribution-Friendly Post-Training Quantization for Vision Transformers
Jul 03, 2024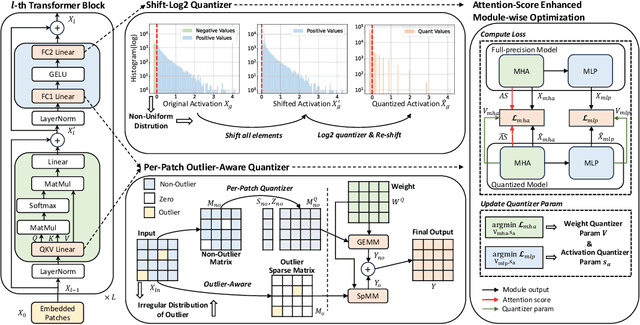
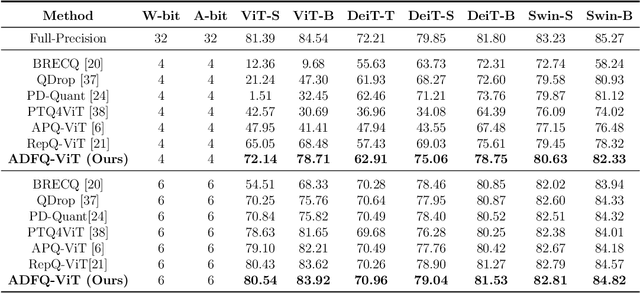
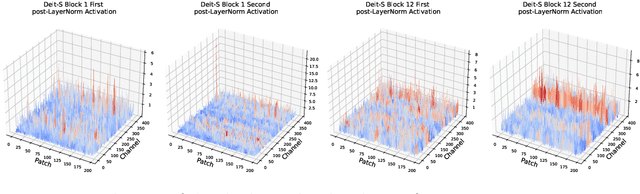
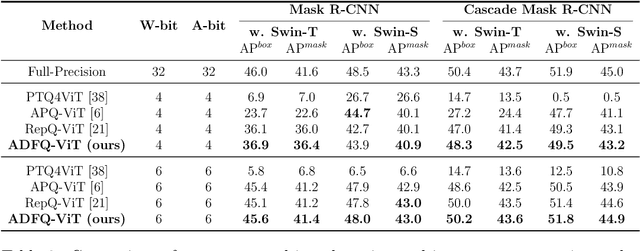
Vision Transformers (ViTs) have exhibited exceptional performance across diverse computer vision tasks, while their substantial parameter size incurs significantly increased memory and computational demands, impeding effective inference on resource-constrained devices. Quantization has emerged as a promising solution to mitigate these challenges, yet existing methods still suffer from significant accuracy loss at low-bit. We attribute this issue to the distinctive distributions of post-LayerNorm and post-GELU activations within ViTs, rendering conventional hardware-friendly quantizers ineffective, particularly in low-bit scenarios. To address this issue, we propose a novel framework called Activation-Distribution-Friendly post-training Quantization for Vision Transformers, ADFQ-ViT. Concretely, we introduce the Per-Patch Outlier-aware Quantizer to tackle irregular outliers in post-LayerNorm activations. This quantizer refines the granularity of the uniform quantizer to a per-patch level while retaining a minimal subset of values exceeding a threshold at full-precision. To handle the non-uniform distributions of post-GELU activations between positive and negative regions, we design the Shift-Log2 Quantizer, which shifts all elements to the positive region and then applies log2 quantization. Moreover, we present the Attention-score enhanced Module-wise Optimization which adjusts the parameters of each quantizer by reconstructing errors to further mitigate quantization error. Extensive experiments demonstrate ADFQ-ViT provides significant improvements over various baselines in image classification, object detection, and instance segmentation tasks at 4-bit. Specifically, when quantizing the ViT-B model to 4-bit, we achieve a 10.23% improvement in Top-1 accuracy on the ImageNet dataset.
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Apr 19, 2024



Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Dec 11, 2023



Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Exploring Post-Training Quantization of Protein Language Models
Oct 30, 2023



Recent advancements in unsupervised protein language models (ProteinLMs), like ESM-1b and ESM-2, have shown promise in different protein prediction tasks. However, these models face challenges due to their high computational demands, significant memory needs, and latency, restricting their usage on devices with limited resources. To tackle this, we explore post-training quantization (PTQ) for ProteinLMs, focusing on ESMFold, a simplified version of AlphaFold based on ESM-2 ProteinLM. Our study is the first attempt to quantize all weights and activations of ProteinLMs. We observed that the typical uniform quantization method performs poorly on ESMFold, causing a significant drop in TM-Score when using 8-bit quantization. We conducted extensive quantization experiments, uncovering unique challenges associated with ESMFold, particularly highly asymmetric activation ranges before Layer Normalization, making representation difficult using low-bit fixed-point formats. To address these challenges, we propose a new PTQ method for ProteinLMs, utilizing piecewise linear quantization for asymmetric activation values to ensure accurate approximation. We demonstrated the effectiveness of our method in protein structure prediction tasks, demonstrating that ESMFold can be accurately quantized to low-bit widths without compromising accuracy. Additionally, we applied our method to the contact prediction task, showcasing its versatility. In summary, our study introduces an innovative PTQ method for ProteinLMs, addressing specific quantization challenges and potentially leading to the development of more efficient ProteinLMs with significant implications for various protein-related applications.
NLP-based detection of systematic anomalies among the narratives of consumer complaints
Aug 22, 2023



We develop an NLP-based procedure for detecting systematic nonmeritorious consumer complaints, simply called systematic anomalies, among complaint narratives. While classification algorithms are used to detect pronounced anomalies, in the case of smaller and frequent systematic anomalies, the algorithms may falter due to a variety of reasons, including technical ones as well as natural limitations of human analysts. Therefore, as the next step after classification, we convert the complaint narratives into quantitative data, which are then analyzed using an algorithm for detecting systematic anomalies. We illustrate the entire procedure using complaint narratives from the Consumer Complaint Database of the Consumer Financial Protection Bureau.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023
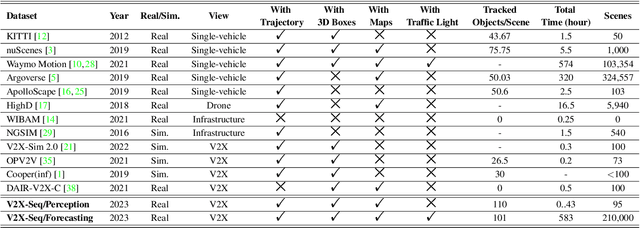
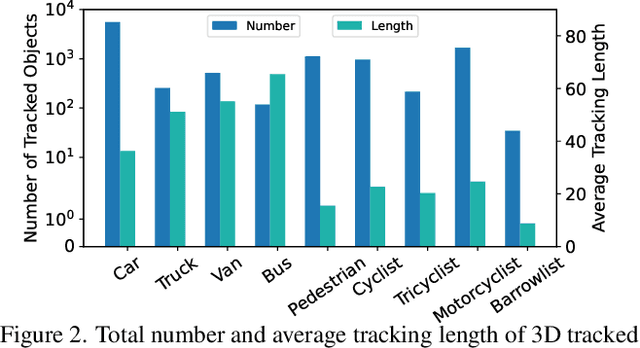
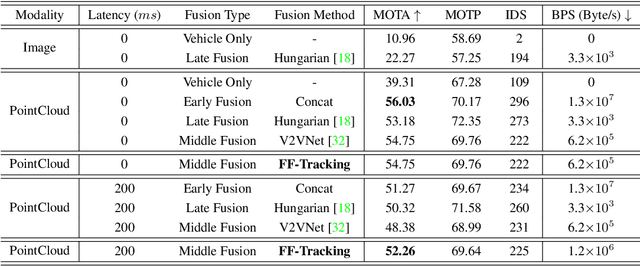
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
Deep Learning Topological Invariants of Band Insulators
Jun 09, 2018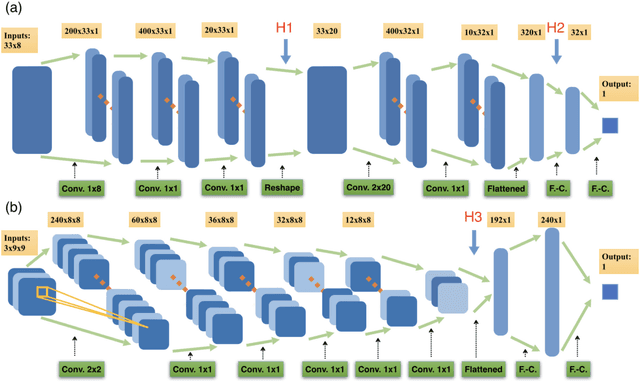
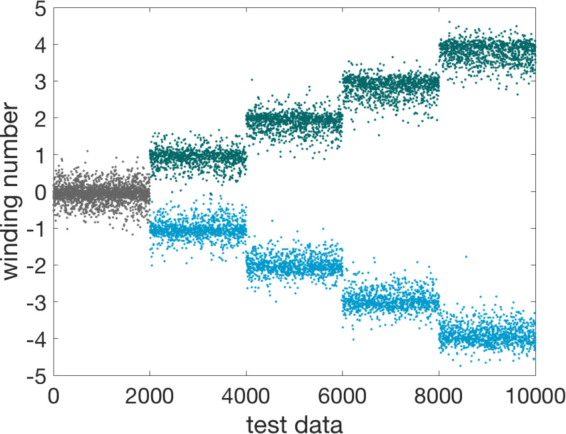
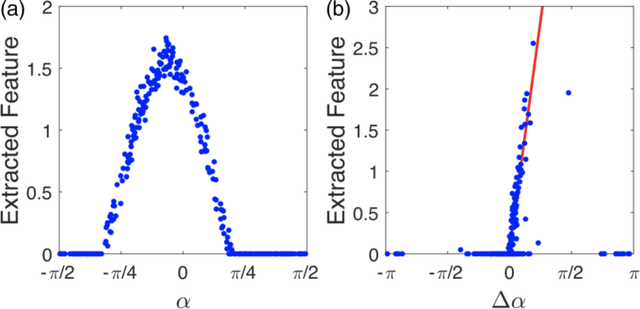
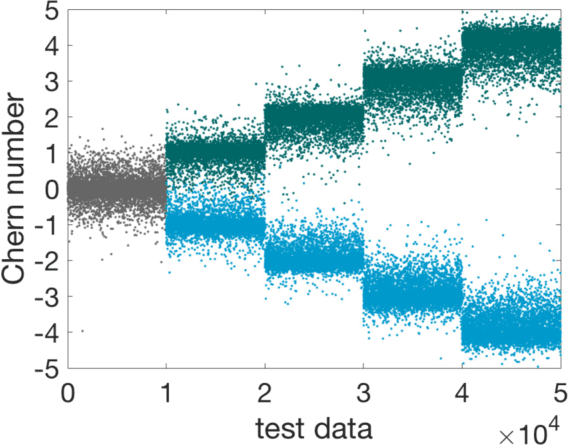
In this work we design and train deep neural networks to predict topological invariants for one-dimensional four-band insulators in AIII class whose topological invariant is the winding number, and two-dimensional two-band insulators in A class whose topological invariant is the Chern number. Given Hamiltonians in the momentum space as the input, neural networks can predict topological invariants for both classes with accuracy close to or higher than 90%, even for Hamiltonians whose invariants are beyond the training data set. Despite the complexity of the neural network, we find that the output of certain intermediate hidden layers resembles either the winding angle for models in AIII class or the solid angle (Berry curvature) for models in A class, indicating that neural networks essentially capture the mathematical formula of topological invariants. Our work demonstrates the ability of neural networks to predict topological invariants for complicated models with local Hamiltonians as the only input, and offers an example that even a deep neural network is understandable.
* 8 pages, 5 figures