 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUDDY: BUdget-Driven DYnamic Depth Routing for Adaptive Large Language Model Inference
Jun 08, 2026Large language models (LLMs) incur high inference cost due to their depth and parameter scale. Depth pruning can reduce latency by skipping redundant Transformer blocks, but existing methods (i) provide limited control under user-specific compute budgets and (ii) typically fix the routing path, failing to adapt as the context grows during decoding. We propose Buddy, a budget-driven dynamic depth routing framework. Buddy uses a lightweight Decision Module to score intermediate layers conditioned on the input and deterministically executes the top-k layers to satisfy a given budget. To support decode-time adaptation, Buddy reuses the first-layer KV cache as a low-overhead global context source and pools it together with the newest token representation before each routing decision. When no explicit budget is provided, an optional Budget Predictor estimates an input-dependent compute level to balance quality and efficiency. Experiments on Llama-family and Qwen models show that Buddy is competitive with strong static pruning baselines and often improves the accuracy-compute trade-off, while uniquely supporting strict budget control, decode-time rerouting, and multiple budgets within a single trained model.
KernelSkill: A Multi-Agent Framework for GPU Kernel Optimization
Mar 10, 2026Improving GPU kernel efficiency is crucial for advancing AI systems. Recent work has explored leveraging large language models (LLMs) for GPU kernel generation and optimization. However, existing LLM-based kernel optimization pipelines typically rely on opaque, implicitly learned heuristics within the LLMs to determine optimization strategies. This leads to inefficient trial-and-error and weakly interpretable optimizations. Our key insight is to replace implicit heuristics with expert optimization skills that are knowledge-driven and aware of task trajectories. Specifically, we present KernelSkill, a multi-agent framework with a dual-level memory architecture. KernelSkill operates by coordinating agents with long-term memory of reusable expert skills and short-term memory to prevent repetitive backtracking. On KernelBench Levels 1-3, KernelSkill achieves a 100% success rate and average speedups of 5.44x, 2.82x, and 1.92x over Torch Eager on Levels 1, 2, and 3, respectively, outperforming prior baselines. Code is available at https://github.com/0satan0/KernelMem/.
Obscure but Effective: Classical Chinese Jailbreak Prompt Optimization via Bio-Inspired Search
Feb 26, 2026As Large Language Models (LLMs) are increasingly used, their security risks have drawn increasing attention. Existing research reveals that LLMs are highly susceptible to jailbreak attacks, with effectiveness varying across language contexts. This paper investigates the role of classical Chinese in jailbreak attacks. Owing to its conciseness and obscurity, classical Chinese can partially bypass existing safety constraints, exposing notable vulnerabilities in LLMs. Based on this observation, this paper proposes a framework, CC-BOS, for the automatic generation of classical Chinese adversarial prompts based on multi-dimensional fruit fly optimization, facilitating efficient and automated jailbreak attacks in black-box settings. Prompts are encoded into eight policy dimensions-covering role, behavior, mechanism, metaphor, expression, knowledge, trigger pattern and context; and iteratively refined via smell search, visual search, and cauchy mutation. This design enables efficient exploration of the search space, thereby enhancing the effectiveness of black-box jailbreak attacks. To enhance readability and evaluation accuracy, we further design a classical Chinese to English translation module. Extensive experiments demonstrate that effectiveness of the proposed CC-BOS, consistently outperforming state-of-the-art jailbreak attack methods.
Sharpness-aware Dynamic Anchor Selection for Generalized Category Discovery
Dec 15, 2025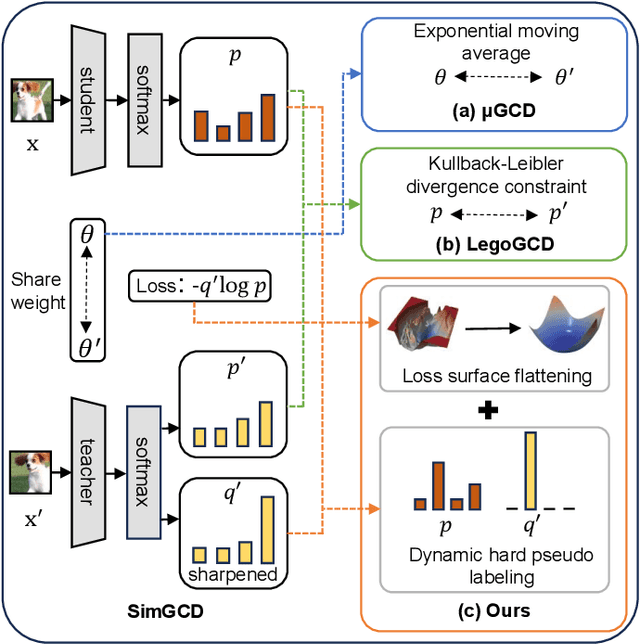
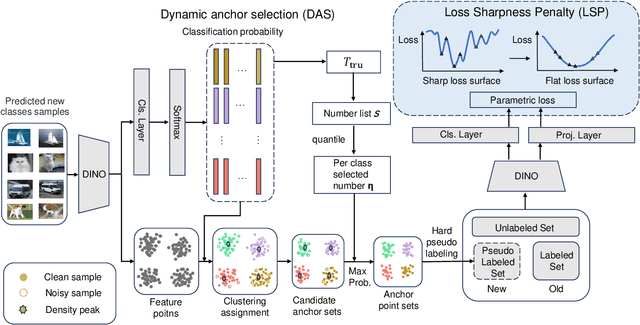
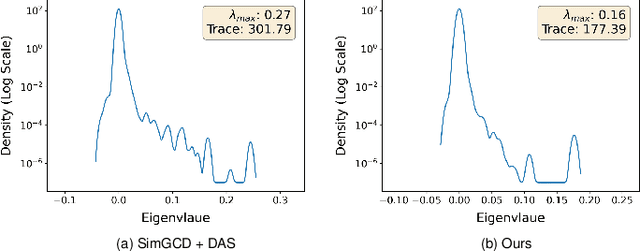
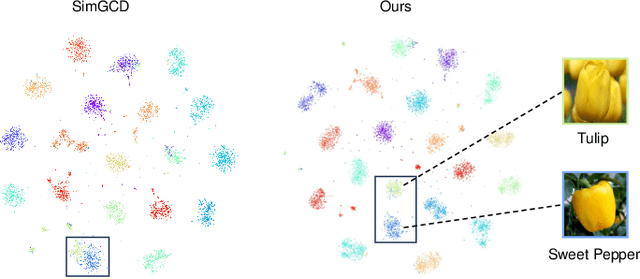
Generalized category discovery (GCD) is an important and challenging task in open-world learning. Specifically, given some labeled data of known classes, GCD aims to cluster unlabeled data that contain both known and unknown classes. Current GCD methods based on parametric classification adopt the DINO-like pseudo-labeling strategy, where the sharpened probability output of one view is used as supervision information for the other view. However, large pre-trained models have a preference for some specific visual patterns, resulting in encoding spurious correlation for unlabeled data and generating noisy pseudo-labels. To address this issue, we propose a novel method, which contains two modules: Loss Sharpness Penalty (LSP) and Dynamic Anchor Selection (DAS). LSP enhances the robustness of model parameters to small perturbations by minimizing the worst-case loss sharpness of the model, which suppressing the encoding of trivial features, thereby reducing overfitting of noise samples and improving the quality of pseudo-labels. Meanwhile, DAS selects representative samples for the unknown classes based on KNN density and class probability during the model training and assigns hard pseudo-labels to them, which not only alleviates the confidence difference between known and unknown classes but also enables the model to quickly learn more accurate feature distribution for the unknown classes, thus further improving the clustering accuracy. Extensive experiments demonstrate that the proposed method can effectively mitigate the noise of pseudo-labels, and achieve state-of-the-art results on multiple GCD benchmarks.
SRNN: Spatiotemporal Relational Neural Network for Intuitive Physics Understanding
Nov 19, 2025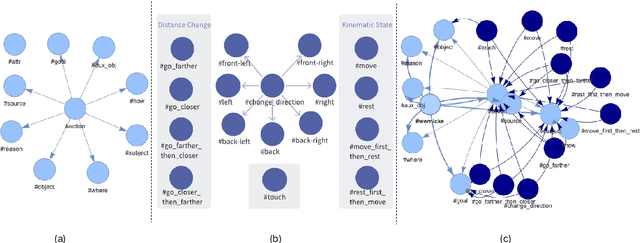
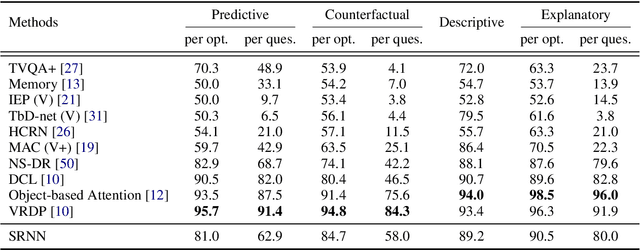
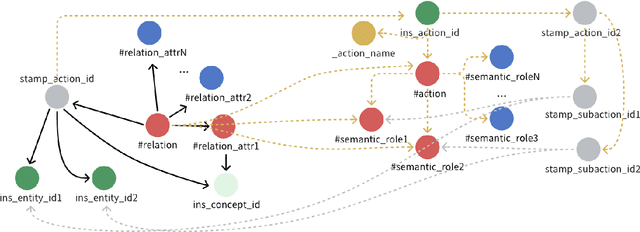
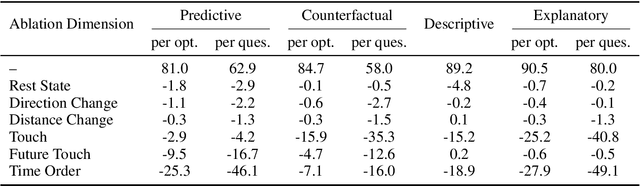
Human prowess in intuitive physics remains unmatched by machines. To bridge this gap, we argue for a fundamental shift towards brain-inspired computational principles. This paper introduces the Spatiotemporal Relational Neural Network (SRNN), a model that establishes a unified neural representation for object attributes, relations, and timeline, with computations governed by a Hebbian ``Fire Together, Wire Together'' mechanism across dedicated \textit{What} and \textit{How} pathways. This unified representation is directly used to generate structured linguistic descriptions of the visual scene, bridging perception and language within a shared neural substrate. On the CLEVRER benchmark, SRNN achieves competitive performance, thereby confirming its capability to represent essential spatiotemporal relations from the visual stream. Cognitive ablation analysis further reveals a benchmark bias, outlining a path for a more holistic evaluation. Finally, the white-box nature of SRNN enables precise pinpointing of error root causes. Our work provides a proof-of-concept that confirms the viability of translating key principles of biological intelligence into engineered systems for intuitive physics understanding in constrained environments.
Not All Parameters Matter: Masking Diffusion Models for Enhancing Generation Ability
May 06, 2025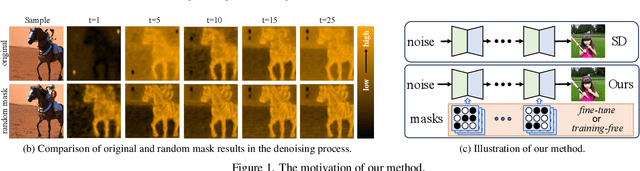
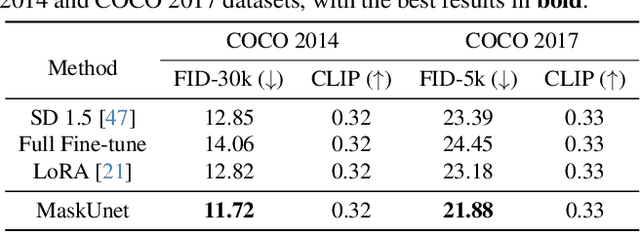
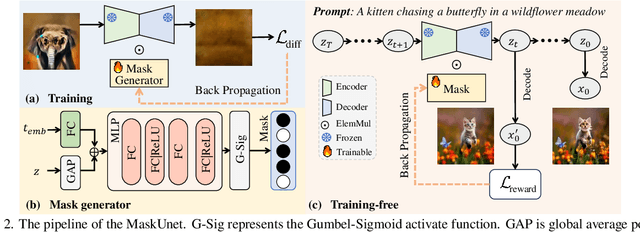
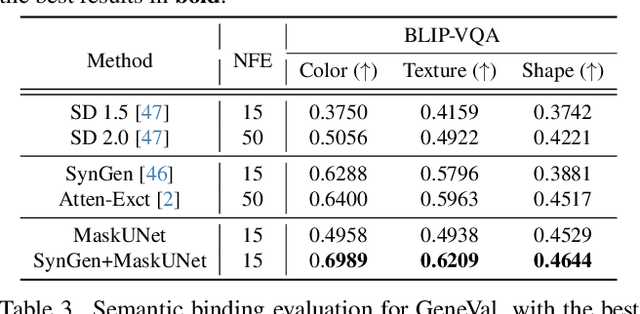
The diffusion models, in early stages focus on constructing basic image structures, while the refined details, including local features and textures, are generated in later stages. Thus the same network layers are forced to learn both structural and textural information simultaneously, significantly differing from the traditional deep learning architectures (e.g., ResNet or GANs) which captures or generates the image semantic information at different layers. This difference inspires us to explore the time-wise diffusion models. We initially investigate the key contributions of the U-Net parameters to the denoising process and identify that properly zeroing out certain parameters (including large parameters) contributes to denoising, substantially improving the generation quality on the fly. Capitalizing on this discovery, we propose a simple yet effective method-termed ``MaskUNet''- that enhances generation quality with negligible parameter numbers. Our method fully leverages timestep- and sample-dependent effective U-Net parameters. To optimize MaskUNet, we offer two fine-tuning strategies: a training-based approach and a training-free approach, including tailored networks and optimization functions. In zero-shot inference on the COCO dataset, MaskUNet achieves the best FID score and further demonstrates its effectiveness in downstream task evaluations. Project page: https://gudaochangsheng.github.io/MaskUnet-Page/
KAC: Kolmogorov-Arnold Classifier for Continual Learning
Mar 27, 2025



Continual learning requires models to train continuously across consecutive tasks without forgetting. Most existing methods utilize linear classifiers, which struggle to maintain a stable classification space while learning new tasks. Inspired by the success of Kolmogorov-Arnold Networks (KAN) in preserving learning stability during simple continual regression tasks, we set out to explore their potential in more complex continual learning scenarios. In this paper, we introduce the Kolmogorov-Arnold Classifier (KAC), a novel classifier developed for continual learning based on the KAN structure. We delve into the impact of KAN's spline functions and introduce Radial Basis Functions (RBF) for improved compatibility with continual learning. We replace linear classifiers with KAC in several recent approaches and conduct experiments across various continual learning benchmarks, all of which demonstrate performance improvements, highlighting the effectiveness and robustness of KAC in continual learning. The code is available at https://github.com/Ethanhuhuhu/KAC.
Restoring Forgotten Knowledge in Non-Exemplar Class Incremental Learning through Test-Time Semantic Evolution
Mar 21, 2025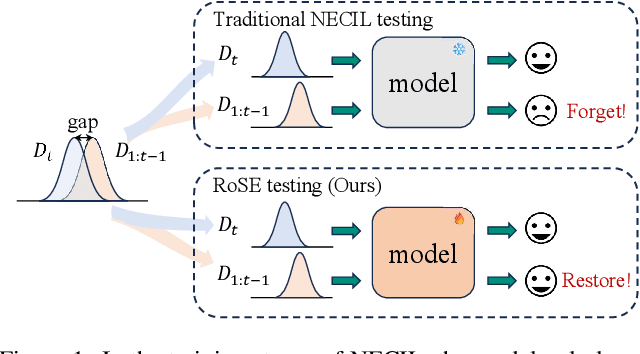
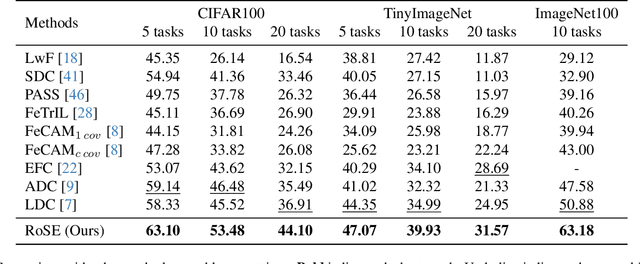
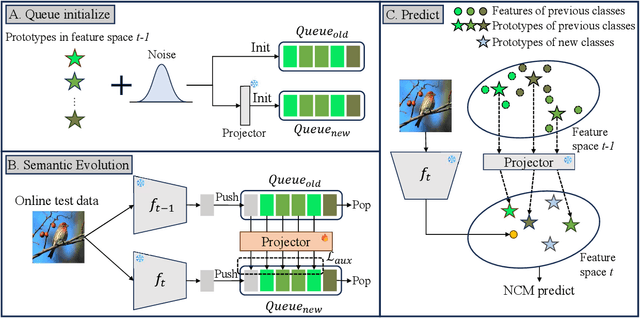
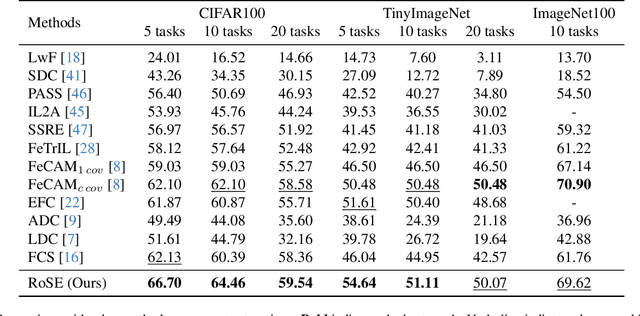
Continual learning aims to accumulate knowledge over a data stream while mitigating catastrophic forgetting. In Non-exemplar Class Incremental Learning (NECIL), forgetting arises during incremental optimization because old classes are inaccessible, hindering the retention of prior knowledge. To solve this, previous methods struggle in achieving the stability-plasticity balance in the training stages. However, we note that the testing stage is rarely considered among them, but is promising to be a solution to forgetting. Therefore, we propose RoSE, which is a simple yet effective method that \textbf{R}est\textbf{o}res forgotten knowledge through test-time \textbf{S}emantic \textbf{E}volution. Specifically designed for minimizing forgetting, RoSE is a test-time semantic drift compensation framework that enables more accurate drift estimation in a self-supervised manner. Moreover, to avoid incomplete optimization during online testing, we derive an analytical solution as an alternative to gradient descent. We evaluate RoSE on CIFAR-100, TinyImageNet, and ImageNet100 datasets, under both cold-start and warm-start settings. Our method consistently outperforms most state-of-the-art (SOTA) methods across various scenarios, validating the potential and feasibility of test-time evolution in NECIL.
Learning Part Knowledge to Facilitate Category Understanding for Fine-Grained Generalized Category Discovery
Mar 21, 2025Generalized Category Discovery (GCD) aims to classify unlabeled data containing both seen and novel categories. Although existing methods perform well on generic datasets, they struggle in fine-grained scenarios. We attribute this difficulty to their reliance on contrastive learning over global image features to automatically capture discriminative cues, which fails to capture the subtle local differences essential for distinguishing fine-grained categories. Therefore, in this paper, we propose incorporating part knowledge to address fine-grained GCD, which introduces two key challenges: the absence of annotations for novel classes complicates the extraction of the part features, and global contrastive learning prioritizes holistic feature invariance, inadvertently suppressing discriminative local part patterns. To address these challenges, we propose PartGCD, including 1) Adaptive Part Decomposition, which automatically extracts class-specific semantic parts via Gaussian Mixture Models, and 2) Part Discrepancy Regularization, enforcing explicit separation between part features to amplify fine-grained local part distinctions. Experiments demonstrate state-of-the-art performance across multiple fine-grained benchmarks while maintaining competitiveness on generic datasets, validating the effectiveness and robustness of our approach.
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.