 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Class Textual-Inversion Secretly Yields a Semantic-Agnostic Classifier
Paper and Code

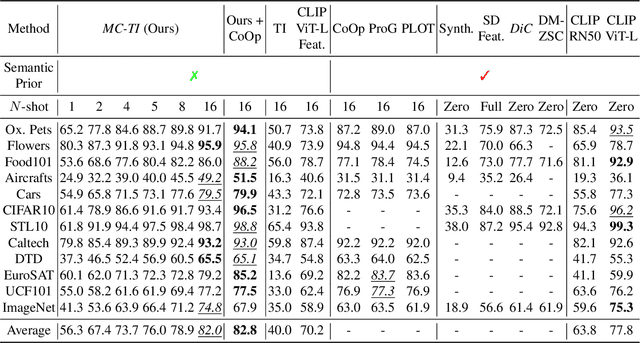
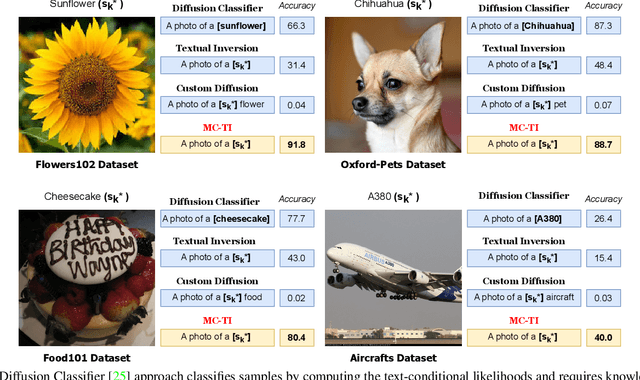
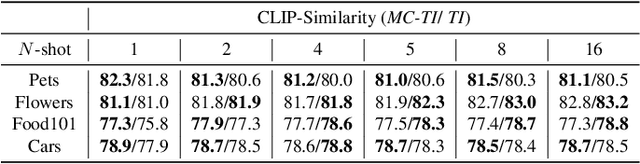
With the advent of large pre-trained vision-language models such as CLIP, prompt learning methods aim to enhance the transferability of the CLIP model. They learn the prompt given few samples from the downstream task given the specific class names as prior knowledge, which we term as semantic-aware classification. However, in many realistic scenarios, we only have access to few samples and knowledge of the class names (e.g., when considering instances of classes). This challenging scenario represents the semantic-agnostic discriminative case. Text-to-Image (T2I) personalization methods aim to adapt T2I models to unseen concepts by learning new tokens and endowing these tokens with the capability of generating the learned concepts. These methods do not require knowledge of class names as a semantic-aware prior. Therefore, in this paper, we first explore Textual Inversion and reveal that the new concept tokens possess both generation and classification capabilities by regarding each category as a single concept. However, learning classifiers from single-concept textual inversion is limited since the learned tokens are suboptimal for the discriminative tasks. To mitigate this issue, we propose Multi-Class textual inversion, which includes a discriminative regularization term for the token updating process. Using this technique, our method MC-TI achieves stronger Semantic-Agnostic Classification while preserving the generation capability of these modifier tokens given only few samples per category. In the experiments, we extensively evaluate MC-TI on 12 datasets covering various scenarios, which demonstrates that MC-TI achieves superior results in terms of both classification and generation outcomes.