 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Resolution Generalization of Diffusion Transformers with Randomized Positional Encodings
Mar 24, 2025Resolution generalization in image generation tasks enables the production of higher-resolution images with lower training resolution overhead. However, a significant challenge in resolution generalization, particularly in the widely used Diffusion Transformers, lies in the mismatch between the positional encodings encountered during testing and those used during training. While existing methods have employed techniques such as interpolation, extrapolation, or their combinations, none have fully resolved this issue. In this paper, we propose a novel two-dimensional randomized positional encodings (RPE-2D) framework that focuses on learning positional order of image patches instead of the specific distances between them, enabling seamless high- and low-resolution image generation without requiring high- and low-resolution image training. Specifically, RPE-2D independently selects positions over a broader range along both the horizontal and vertical axes, ensuring that all position encodings are trained during the inference phase, thus improving resolution generalization. Additionally, we propose a random data augmentation technique to enhance the modeling of position order. To address the issue of image cropping caused by the augmentation, we introduce corresponding micro-conditioning to enable the model to perceive the specific cropping patterns. On the ImageNet dataset, our proposed RPE-2D achieves state-of-the-art resolution generalization performance, outperforming existing competitive methods when trained at a resolution of $256 \times 256$ and inferred at $384 \times 384$ and $512 \times 512$, as well as when scaling from $512 \times 512$ to $768 \times 768$ and $1024 \times 1024$. And it also exhibits outstanding capabilities in low-resolution image generation, multi-stage training acceleration and multi-resolution inheritance.
DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
Mar 18, 2025Diffusion models have demonstrated remarkable success in various image generation tasks, but their performance is often limited by the uniform processing of inputs across varying conditions and noise levels. To address this limitation, we propose a novel approach that leverages the inherent heterogeneity of the diffusion process. Our method, DiffMoE, introduces a batch-level global token pool that enables experts to access global token distributions during training, promoting specialized expert behavior. To unleash the full potential of the diffusion process, DiffMoE incorporates a capacity predictor that dynamically allocates computational resources based on noise levels and sample complexity. Through comprehensive evaluation, DiffMoE achieves state-of-the-art performance among diffusion models on ImageNet benchmark, substantially outperforming both dense architectures with 3x activated parameters and existing MoE approaches while maintaining 1x activated parameters. The effectiveness of our approach extends beyond class-conditional generation to more challenging tasks such as text-to-image generation, demonstrating its broad applicability across different diffusion model applications. Project Page: https://shiml20.github.io/DiffMoE/
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
Towards Precise Scaling Laws for Video Diffusion Transformers
Nov 25, 2024



Achieving optimal performance of video diffusion transformers within given data and compute budget is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size, two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by 40.1% compared to conventional scaling methods, within a compute budget of 1e10 TFlops. Furthermore, we establish a more generalized and precise relationship among validation loss, any model size, and compute budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
Koala-36M: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content
Oct 10, 2024As visual generation technologies continue to advance, the scale of video datasets has expanded rapidly, and the quality of these datasets is critical to the performance of video generation models. We argue that temporal splitting, detailed captions, and video quality filtering are three key factors that determine dataset quality. However, existing datasets exhibit various limitations in these areas. To address these challenges, we introduce Koala-36M, a large-scale, high-quality video dataset featuring accurate temporal splitting, detailed captions, and superior video quality. The core of our approach lies in improving the consistency between fine-grained conditions and video content. Specifically, we employ a linear classifier on probability distributions to enhance the accuracy of transition detection, ensuring better temporal consistency. We then provide structured captions for the splitted videos, with an average length of 200 words, to improve text-video alignment. Additionally, we develop a Video Training Suitability Score (VTSS) that integrates multiple sub-metrics, allowing us to filter high-quality videos from the original corpus. Finally, we incorporate several metrics into the training process of the generation model, further refining the fine-grained conditions. Our experiments demonstrate the effectiveness of our data processing pipeline and the quality of the proposed Koala-36M dataset. Our dataset and code will be released at https://koala36m.github.io/.
VRMM: A Volumetric Relightable Morphable Head Model
Feb 06, 2024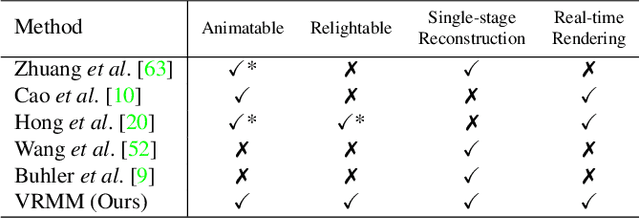
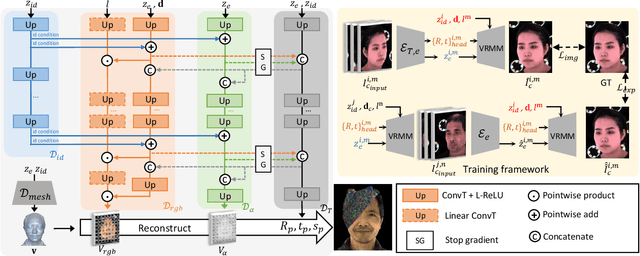
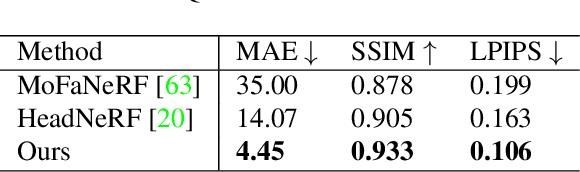

In this paper, we introduce the Volumetric Relightable Morphable Model (VRMM), a novel volumetric and parametric facial prior for 3D face modeling. While recent volumetric prior models offer improvements over traditional methods like 3D Morphable Models (3DMMs), they face challenges in model learning and personalized reconstructions. Our VRMM overcomes these by employing a novel training framework that efficiently disentangles and encodes latent spaces of identity, expression, and lighting into low-dimensional representations. This framework, designed with self-supervised learning, significantly reduces the constraints for training data, making it more feasible in practice. The learned VRMM offers relighting capabilities and encompasses a comprehensive range of expressions. We demonstrate the versatility and effectiveness of VRMM through various applications like avatar generation, facial reconstruction, and animation. Additionally, we address the common issue of overfitting in generative volumetric models with a novel prior-preserving personalization framework based on VRMM. Such an approach enables accurate 3D face reconstruction from even a single portrait input. Our experiments showcase the potential of VRMM to significantly enhance the field of 3D face modeling.
I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models
Dec 27, 2023



In the rapidly evolving domain of digital content generation, the focus has shifted from text-to-image (T2I) models to more advanced video diffusion models, notably text-to-video (T2V) and image-to-video (I2V). This paper addresses the intricate challenge posed by I2V: converting static images into dynamic, lifelike video sequences while preserving the original image fidelity. Traditional methods typically involve integrating entire images into diffusion processes or using pretrained encoders for cross attention. However, these approaches often necessitate altering the fundamental weights of T2I models, thereby restricting their reusability. We introduce a novel solution, namely I2V-Adapter, designed to overcome such limitations. Our approach preserves the structural integrity of T2I models and their inherent motion modules. The I2V-Adapter operates by processing noised video frames in parallel with the input image, utilizing a lightweight adapter module. This module acts as a bridge, efficiently linking the input to the model's self-attention mechanism, thus maintaining spatial details without requiring structural changes to the T2I model. Moreover, I2V-Adapter requires only a fraction of the parameters of conventional models and ensures compatibility with existing community-driven T2I models and controlling tools. Our experimental results demonstrate I2V-Adapter's capability to produce high-quality video outputs. This performance, coupled with its versatility and reduced need for trainable parameters, represents a substantial advancement in the field of AI-driven video generation, particularly for creative applications.
ImFace++: A Sophisticated Nonlinear 3D Morphable Face Model with Implicit Neural Representations
Dec 07, 2023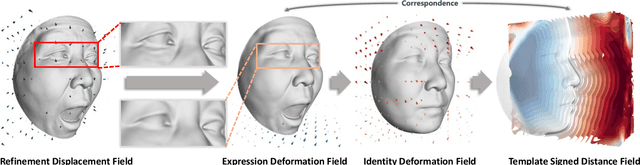
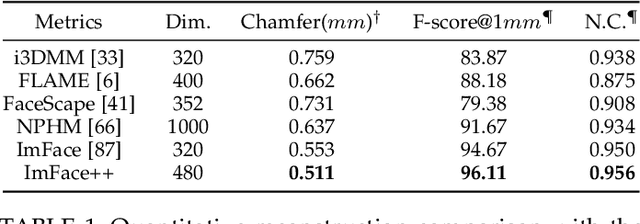
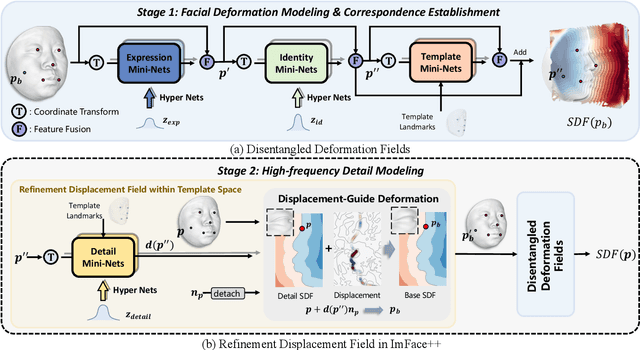
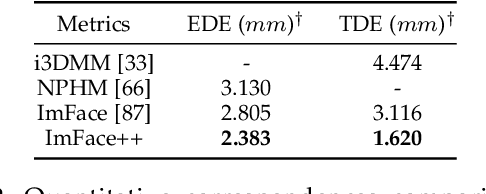
Accurate representations of 3D faces are of paramount importance in various computer vision and graphics applications. However, the challenges persist due to the limitations imposed by data discretization and model linearity, which hinder the precise capture of identity and expression clues in current studies. This paper presents a novel 3D morphable face model, named ImFace++, to learn a sophisticated and continuous space with implicit neural representations. ImFace++ first constructs two explicitly disentangled deformation fields to model complex shapes associated with identities and expressions, respectively, which simultaneously facilitate the automatic learning of correspondences across diverse facial shapes. To capture more sophisticated facial details, a refinement displacement field within the template space is further incorporated, enabling a fine-grained learning of individual-specific facial details. Furthermore, a Neural Blend-Field is designed to reinforce the representation capabilities through adaptive blending of an array of local fields. In addition to ImFace++, we have devised an improved learning strategy to extend expression embeddings, allowing for a broader range of expression variations. Comprehensive qualitative and quantitative evaluations demonstrate that ImFace++ significantly advances the state-of-the-art in terms of both face reconstruction fidelity and correspondence accuracy.
Towards Practical Capture of High-Fidelity Relightable Avatars
Sep 08, 2023



In this paper, we propose a novel framework, Tracking-free Relightable Avatar (TRAvatar), for capturing and reconstructing high-fidelity 3D avatars. Compared to previous methods, TRAvatar works in a more practical and efficient setting. Specifically, TRAvatar is trained with dynamic image sequences captured in a Light Stage under varying lighting conditions, enabling realistic relighting and real-time animation for avatars in diverse scenes. Additionally, TRAvatar allows for tracking-free avatar capture and obviates the need for accurate surface tracking under varying illumination conditions. Our contributions are two-fold: First, we propose a novel network architecture that explicitly builds on and ensures the satisfaction of the linear nature of lighting. Trained on simple group light captures, TRAvatar can predict the appearance in real-time with a single forward pass, achieving high-quality relighting effects under illuminations of arbitrary environment maps. Second, we jointly optimize the facial geometry and relightable appearance from scratch based on image sequences, where the tracking is implicitly learned. This tracking-free approach brings robustness for establishing temporal correspondences between frames under different lighting conditions. Extensive qualitative and quantitative experiments demonstrate that our framework achieves superior performance for photorealistic avatar animation and relighting.
NeuFace: Realistic 3D Neural Face Rendering from Multi-view Images
Mar 27, 2023Realistic face rendering from multi-view images is beneficial to various computer vision and graphics applications. Due to the complex spatially-varying reflectance properties and geometry characteristics of faces, however, it remains challenging to recover 3D facial representations both faithfully and efficiently in the current studies. This paper presents a novel 3D face rendering model, namely NeuFace, to learn accurate and physically-meaningful underlying 3D representations by neural rendering techniques. It naturally incorporates the neural BRDFs into physically based rendering, capturing sophisticated facial geometry and appearance clues in a collaborative manner. Specifically, we introduce an approximated BRDF integration and a simple yet new low-rank prior, which effectively lower the ambiguities and boost the performance of the facial BRDFs. Extensive experiments demonstrate the superiority of NeuFace in human face rendering, along with a decent generalization ability to common objects.