 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Scenario Deraining Adaptation with Unpaired Data: Superpixel Structural Priors and Multi-Stage Pseudo-Rain Synthesis
Mar 23, 2026Image deraining plays a pivotal role in low-level computer vision, serving as a prerequisite for robust outdoor surveillance and autonomous driving systems. While deep learning paradigms have achieved remarkable success in firmly aligned settings, they often suffer from severe performance degradation when generalized to unseen Out-of-Distribution (OOD) scenarios. This failure stems primarily from the significant domain discrepancy between synthetic training datasets and the complex physical dynamics of real-world rain. To address these challenges, this paper proposes a pioneering cross-scenario deraining adaptation framework. Diverging from conventional approaches, our method obviates the requirements for paired rainy observations in the target domain, leveraging exclusively rain-free background images. We design a Superpixel Generation (Sup-Gen) module to extract stable structural priors from the source domain using Simple Linear Iterative Clustering. Subsequently, a Resolution-adaptive Fusion strategy is introduced to align these source structures with target backgrounds through texture similarity, ensuring the synthesis of diverse and realistic pseudo-data. Finally, we implement a pseudo-label re-Synthesize mechanism that employs multi-stage noise generation to simulate realistic rain streaks. This framework functions as a versatile plug-and-play module capable of seamless integration into arbitrary deraining architectures. Extensive experiments on state-of-the-art models demonstrate that our approach yields remarkable PSNR gains of up to 32% to 59% in OOD domains while significantly accelerating training convergence.
Neural Clothing Tryer: Customized Virtual Try-On via Semantic Enhancement and Controlling Diffusion Model
Jan 30, 2026This work aims to address a novel Customized Virtual Try-ON (Cu-VTON) task, enabling the superimposition of a specified garment onto a model that can be customized in terms of appearance, posture, and additional attributes. Compared with traditional VTON task, it enables users to tailor digital avatars to their individual preferences, thereby enhancing the virtual fitting experience with greater flexibility and engagement. To address this task, we introduce a Neural Clothing Tryer (NCT) framework, which exploits the advanced diffusion models equipped with semantic enhancement and controlling modules to better preserve semantic characterization and textural details of the garment and meanwhile facilitating the flexible editing of the model's postures and appearances. Specifically, NCT introduces a semantic-enhanced module to take semantic descriptions of garments and utilizes a visual-language encoder to learn aligned features across modalities. The aligned features are served as condition input to the diffusion model to enhance the preservation of the garment's semantics. Then, a semantic controlling module is designed to take the garment image, tailored posture image, and semantic description as input to maintain garment details while simultaneously editing model postures, expressions, and various attributes. Extensive experiments on the open available benchmark demonstrate the superior performance of the proposed NCT framework.
SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation Model
Dec 11, 2025We propose a decoupled 3D scene generation framework called SceneMaker in this work. Due to the lack of sufficient open-set de-occlusion and pose estimation priors, existing methods struggle to simultaneously produce high-quality geometry and accurate poses under severe occlusion and open-set settings. To address these issues, we first decouple the de-occlusion model from 3D object generation, and enhance it by leveraging image datasets and collected de-occlusion datasets for much more diverse open-set occlusion patterns. Then, we propose a unified pose estimation model that integrates global and local mechanisms for both self-attention and cross-attention to improve accuracy. Besides, we construct an open-set 3D scene dataset to further extend the generalization of the pose estimation model. Comprehensive experiments demonstrate the superiority of our decoupled framework on both indoor and open-set scenes. Our codes and datasets is released at https://idea-research.github.io/SceneMaker/.
SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features
Sep 19, 2025In this paper, we present SegDINO3D, a novel Transformer encoder-decoder framework for 3D instance segmentation. As 3D training data is generally not as sufficient as 2D training images, SegDINO3D is designed to fully leverage 2D representation from a pre-trained 2D detection model, including both image-level and object-level features, for improving 3D representation. SegDINO3D takes both a point cloud and its associated 2D images as input. In the encoder stage, it first enriches each 3D point by retrieving 2D image features from its corresponding image views and then leverages a 3D encoder for 3D context fusion. In the decoder stage, it formulates 3D object queries as 3D anchor boxes and performs cross-attention from 3D queries to 2D object queries obtained from 2D images using the 2D detection model. These 2D object queries serve as a compact object-level representation of 2D images, effectively avoiding the challenge of keeping thousands of image feature maps in the memory while faithfully preserving the knowledge of the pre-trained 2D model. The introducing of 3D box queries also enables the model to modulate cross-attention using the predicted boxes for more precise querying. SegDINO3D achieves the state-of-the-art performance on the ScanNetV2 and ScanNet200 3D instance segmentation benchmarks. Notably, on the challenging ScanNet200 dataset, SegDINO3D significantly outperforms prior methods by +8.7 and +6.8 mAP on the validation and hidden test sets, respectively, demonstrating its superiority.
Imbalance in Balance: Online Concept Balancing in Generation Models
Jul 17, 2025In visual generation tasks, the responses and combinations of complex concepts often lack stability and are error-prone, which remains an under-explored area. In this paper, we attempt to explore the causal factors for poor concept responses through elaborately designed experiments. We also design a concept-wise equalization loss function (IMBA loss) to address this issue. Our proposed method is online, eliminating the need for offline dataset processing, and requires minimal code changes. In our newly proposed complex concept benchmark Inert-CompBench and two other public test sets, our method significantly enhances the concept response capability of baseline models and yields highly competitive results with only a few codes.
One-shot Face Sketch Synthesis in the Wild via Generative Diffusion Prior and Instruction Tuning
Jun 18, 2025
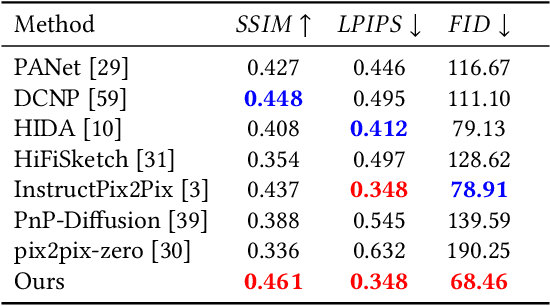


Face sketch synthesis is a technique aimed at converting face photos into sketches. Existing face sketch synthesis research mainly relies on training with numerous photo-sketch sample pairs from existing datasets. However, these large-scale discriminative learning methods will have to face problems such as data scarcity and high human labor costs. Once the training data becomes scarce, their generative performance significantly degrades. In this paper, we propose a one-shot face sketch synthesis method based on diffusion models. We optimize text instructions on a diffusion model using face photo-sketch image pairs. Then, the instructions derived through gradient-based optimization are used for inference. To simulate real-world scenarios more accurately and evaluate method effectiveness more comprehensively, we introduce a new benchmark named One-shot Face Sketch Dataset (OS-Sketch). The benchmark consists of 400 pairs of face photo-sketch images, including sketches with different styles and photos with different backgrounds, ages, sexes, expressions, illumination, etc. For a solid out-of-distribution evaluation, we select only one pair of images for training at each time, with the rest used for inference. Extensive experiments demonstrate that the proposed method can convert various photos into realistic and highly consistent sketches in a one-shot context. Compared to other methods, our approach offers greater convenience and broader applicability. The dataset will be available at: https://github.com/HanWu3125/OS-Sketch
DFVO: Learning Darkness-free Visible and Infrared Image Disentanglement and Fusion All at Once
May 07, 2025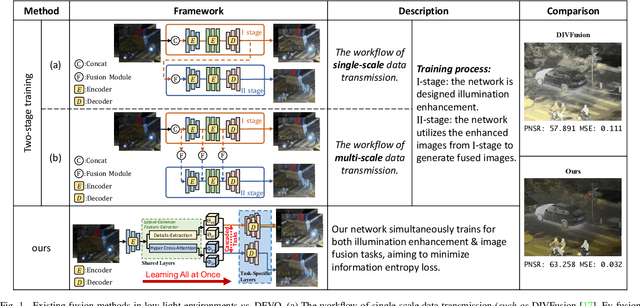
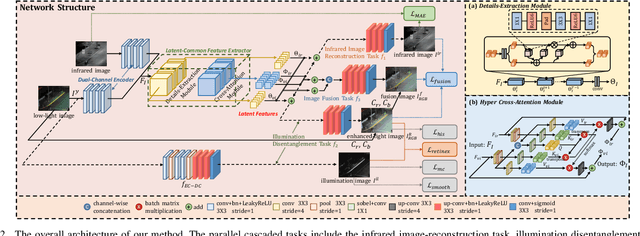


Visible and infrared image fusion is one of the most crucial tasks in the field of image fusion, aiming to generate fused images with clear structural information and high-quality texture features for high-level vision tasks. However, when faced with severe illumination degradation in visible images, the fusion results of existing image fusion methods often exhibit blurry and dim visual effects, posing major challenges for autonomous driving. To this end, a Darkness-Free network is proposed to handle Visible and infrared image disentanglement and fusion all at Once (DFVO), which employs a cascaded multi-task approach to replace the traditional two-stage cascaded training (enhancement and fusion), addressing the issue of information entropy loss caused by hierarchical data transmission. Specifically, we construct a latent-common feature extractor (LCFE) to obtain latent features for the cascaded tasks strategy. Firstly, a details-extraction module (DEM) is devised to acquire high-frequency semantic information. Secondly, we design a hyper cross-attention module (HCAM) to extract low-frequency information and preserve texture features from source images. Finally, a relevant loss function is designed to guide the holistic network learning, thereby achieving better image fusion. Extensive experiments demonstrate that our proposed approach outperforms state-of-the-art alternatives in terms of qualitative and quantitative evaluations. Particularly, DFVO can generate clearer, more informative, and more evenly illuminated fusion results in the dark environments, achieving best performance on the LLVIP dataset with 63.258 dB PSNR and 0.724 CC, providing more effective information for high-level vision tasks. Our code is publicly accessible at https://github.com/DaVin-Qi530/DFVO.
Rethinking Generalizable Infrared Small Target Detection: A Real-scene Benchmark and Cross-view Representation Learning
Apr 23, 2025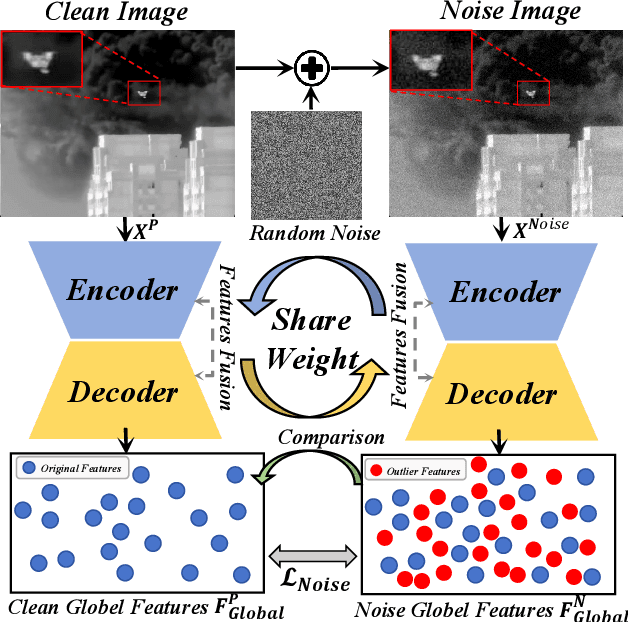
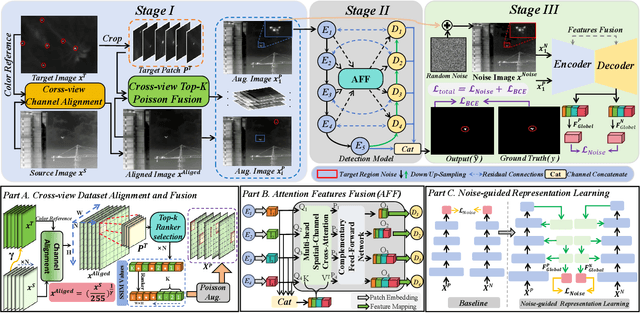
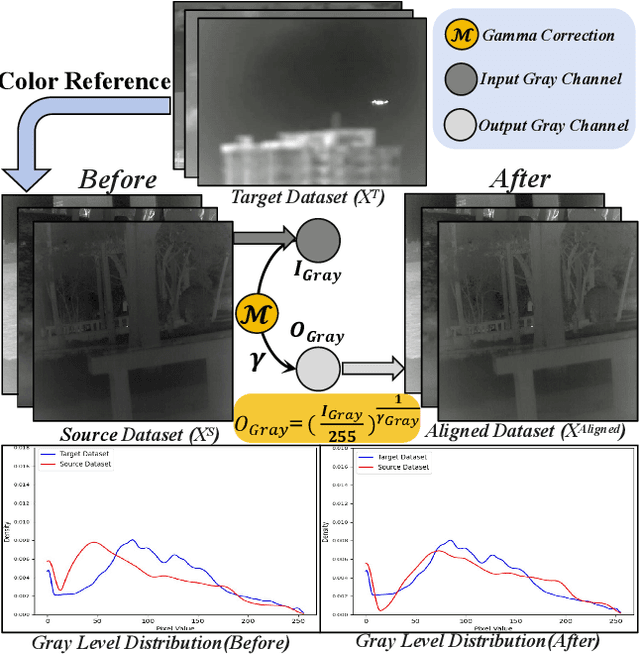
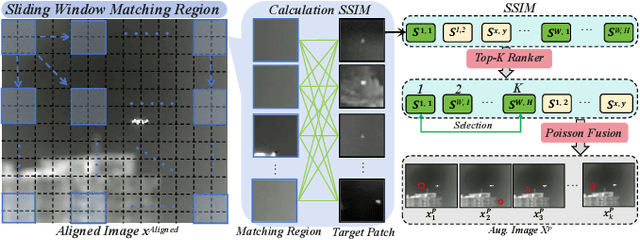
Infrared small target detection (ISTD) is highly sensitive to sensor type, observation conditions, and the intrinsic properties of the target. These factors can introduce substantial variations in the distribution of acquired infrared image data, a phenomenon known as domain shift. Such distribution discrepancies significantly hinder the generalization capability of ISTD models across diverse scenarios. To tackle this challenge, this paper introduces an ISTD framework enhanced by domain adaptation. To alleviate distribution shift between datasets and achieve cross-sample alignment, we introduce Cross-view Channel Alignment (CCA). Additionally, we propose the Cross-view Top-K Fusion strategy, which integrates target information with diverse background features, enhancing the model' s ability to extract critical data characteristics. To further mitigate the impact of noise on ISTD, we develop a Noise-guided Representation learning strategy. This approach enables the model to learn more noise-resistant feature representations, to improve its generalization capability across diverse noisy domains. Finally, we develop a dedicated infrared small target dataset, RealScene-ISTD. Compared to state-of-the-art methods, our approach demonstrates superior performance in terms of detection probability (Pd), false alarm rate (Fa), and intersection over union (IoU). The code is available at: https://github.com/luy0222/RealScene-ISTD.
Contrastive Decoupled Representation Learning and Regularization for Speech-Preserving Facial Expression Manipulation
Apr 08, 2025Speech-preserving facial expression manipulation (SPFEM) aims to modify a talking head to display a specific reference emotion while preserving the mouth animation of source spoken contents. Thus, emotion and content information existing in reference and source inputs can provide direct and accurate supervision signals for SPFEM models. However, the intrinsic intertwining of these elements during the talking process poses challenges to their effectiveness as supervisory signals. In this work, we propose to learn content and emotion priors as guidance augmented with contrastive learning to learn decoupled content and emotion representation via an innovative Contrastive Decoupled Representation Learning (CDRL) algorithm. Specifically, a Contrastive Content Representation Learning (CCRL) module is designed to learn audio feature, which primarily contains content information, as content priors to guide learning content representation from the source input. Meanwhile, a Contrastive Emotion Representation Learning (CERL) module is proposed to make use of a pre-trained visual-language model to learn emotion prior, which is then used to guide learning emotion representation from the reference input. We further introduce emotion-aware and emotion-augmented contrastive learning to train CCRL and CERL modules, respectively, ensuring learning emotion-independent content representation and content-independent emotion representation. During SPFEM model training, the decoupled content and emotion representations are used to supervise the generation process, ensuring more accurate emotion manipulation together with audio-lip synchronization. Extensive experiments and evaluations on various benchmarks show the effectiveness of the proposed algorithm.
Simulating the Real World: A Unified Survey of Multimodal Generative Models
Mar 06, 2025



Understanding and replicating the real world is a critical challenge in Artificial General Intelligence (AGI) research. To achieve this, many existing approaches, such as world models, aim to capture the fundamental principles governing the physical world, enabling more accurate simulations and meaningful interactions. However, current methods often treat different modalities, including 2D (images), videos, 3D, and 4D representations, as independent domains, overlooking their interdependencies. Additionally, these methods typically focus on isolated dimensions of reality without systematically integrating their connections. In this survey, we present a unified survey for multimodal generative models that investigate the progression of data dimensionality in real-world simulation. Specifically, this survey starts from 2D generation (appearance), then moves to video (appearance+dynamics) and 3D generation (appearance+geometry), and finally culminates in 4D generation that integrate all dimensions. To the best of our knowledge, this is the first attempt to systematically unify the study of 2D, video, 3D and 4D generation within a single framework. To guide future research, we provide a comprehensive review of datasets, evaluation metrics and future directions, and fostering insights for newcomers. This survey serves as a bridge to advance the study of multimodal generative models and real-world simulation within a unified framework.