 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossFuse: Learning Infrared and Visible Image Fusion by Cross-Sensor Top-K Vision Alignment and Beyond
Feb 20, 2025Infrared and visible image fusion (IVIF) is increasingly applied in critical fields such as video surveillance and autonomous driving systems. Significant progress has been made in deep learning-based fusion methods. However, these models frequently encounter out-of-distribution (OOD) scenes in real-world applications, which severely impact their performance and reliability. Therefore, addressing the challenge of OOD data is crucial for the safe deployment of these models in open-world environments. Unlike existing research, our focus is on the challenges posed by OOD data in real-world applications and on enhancing the robustness and generalization of models. In this paper, we propose an infrared-visible fusion framework based on Multi-View Augmentation. For external data augmentation, Top-k Selective Vision Alignment is employed to mitigate distribution shifts between datasets by performing RGB-wise transformations on visible images. This strategy effectively introduces augmented samples, enhancing the adaptability of the model to complex real-world scenarios. Additionally, for internal data augmentation, self-supervised learning is established using Weak-Aggressive Augmentation. This enables the model to learn more robust and general feature representations during the fusion process, thereby improving robustness and generalization. Extensive experiments demonstrate that the proposed method exhibits superior performance and robustness across various conditions and environments. Our approach significantly enhances the reliability and stability of IVIF tasks in practical applications.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020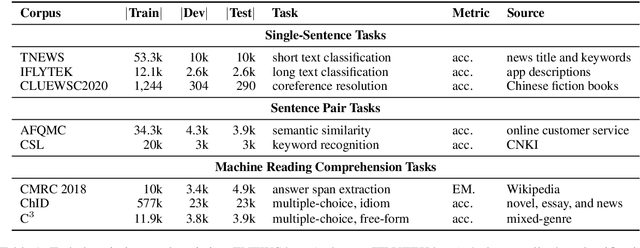
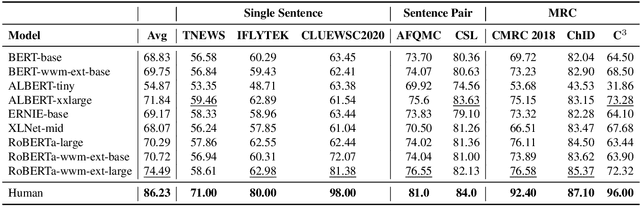
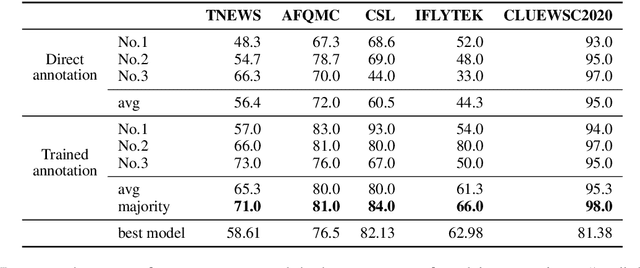
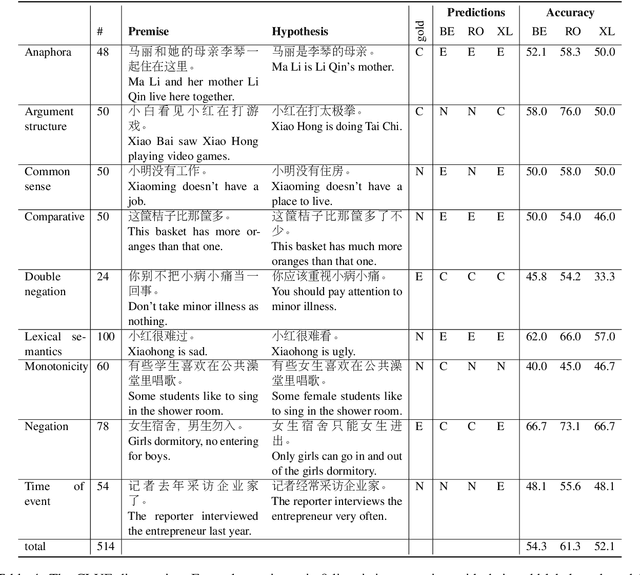
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.
CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
Jan 20, 2020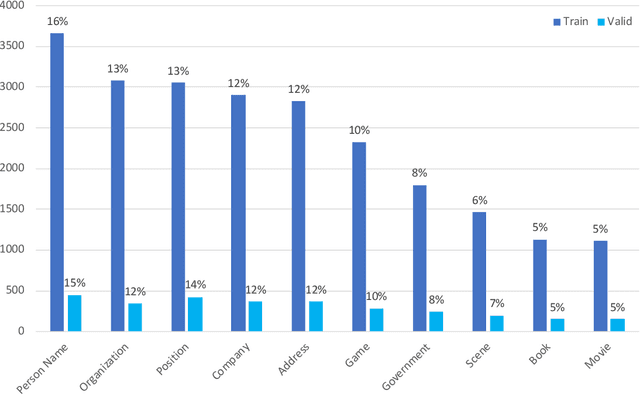

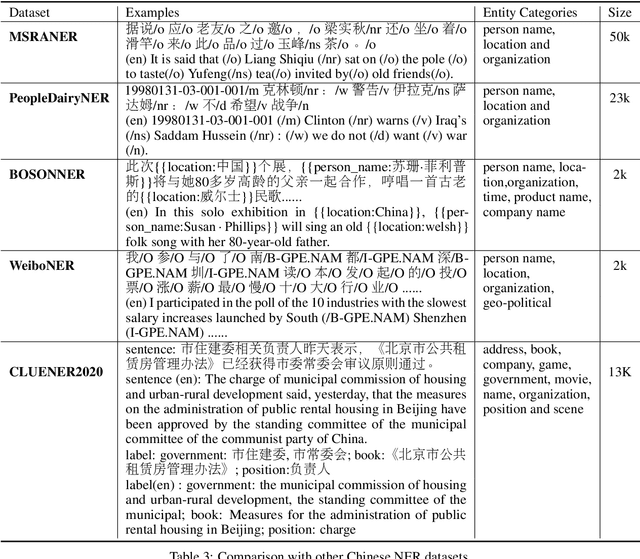
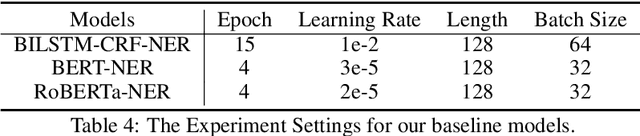
In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for named entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization, and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labeling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines, and leader-board.