 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFVO: Learning Darkness-free Visible and Infrared Image Disentanglement and Fusion All at Once
May 07, 2025Visible and infrared image fusion is one of the most crucial tasks in the field of image fusion, aiming to generate fused images with clear structural information and high-quality texture features for high-level vision tasks. However, when faced with severe illumination degradation in visible images, the fusion results of existing image fusion methods often exhibit blurry and dim visual effects, posing major challenges for autonomous driving. To this end, a Darkness-Free network is proposed to handle Visible and infrared image disentanglement and fusion all at Once (DFVO), which employs a cascaded multi-task approach to replace the traditional two-stage cascaded training (enhancement and fusion), addressing the issue of information entropy loss caused by hierarchical data transmission. Specifically, we construct a latent-common feature extractor (LCFE) to obtain latent features for the cascaded tasks strategy. Firstly, a details-extraction module (DEM) is devised to acquire high-frequency semantic information. Secondly, we design a hyper cross-attention module (HCAM) to extract low-frequency information and preserve texture features from source images. Finally, a relevant loss function is designed to guide the holistic network learning, thereby achieving better image fusion. Extensive experiments demonstrate that our proposed approach outperforms state-of-the-art alternatives in terms of qualitative and quantitative evaluations. Particularly, DFVO can generate clearer, more informative, and more evenly illuminated fusion results in the dark environments, achieving best performance on the LLVIP dataset with 63.258 dB PSNR and 0.724 CC, providing more effective information for high-level vision tasks. Our code is publicly accessible at https://github.com/DaVin-Qi530/DFVO.
CrossFuse: Learning Infrared and Visible Image Fusion by Cross-Sensor Top-K Vision Alignment and Beyond
Feb 20, 2025Infrared and visible image fusion (IVIF) is increasingly applied in critical fields such as video surveillance and autonomous driving systems. Significant progress has been made in deep learning-based fusion methods. However, these models frequently encounter out-of-distribution (OOD) scenes in real-world applications, which severely impact their performance and reliability. Therefore, addressing the challenge of OOD data is crucial for the safe deployment of these models in open-world environments. Unlike existing research, our focus is on the challenges posed by OOD data in real-world applications and on enhancing the robustness and generalization of models. In this paper, we propose an infrared-visible fusion framework based on Multi-View Augmentation. For external data augmentation, Top-k Selective Vision Alignment is employed to mitigate distribution shifts between datasets by performing RGB-wise transformations on visible images. This strategy effectively introduces augmented samples, enhancing the adaptability of the model to complex real-world scenarios. Additionally, for internal data augmentation, self-supervised learning is established using Weak-Aggressive Augmentation. This enables the model to learn more robust and general feature representations during the fusion process, thereby improving robustness and generalization. Extensive experiments demonstrate that the proposed method exhibits superior performance and robustness across various conditions and environments. Our approach significantly enhances the reliability and stability of IVIF tasks in practical applications.
Diff-Mosaic: Augmenting Realistic Representations in Infrared Small Target Detection via Diffusion Prior
Jun 02, 2024Recently, researchers have proposed various deep learning methods to accurately detect infrared targets with the characteristics of indistinct shape and texture. Due to the limited variety of infrared datasets, training deep learning models with good generalization poses a challenge. To augment the infrared dataset, researchers employ data augmentation techniques, which often involve generating new images by combining images from different datasets. However, these methods are lacking in two respects. In terms of realism, the images generated by mixup-based methods lack realism and are difficult to effectively simulate complex real-world scenarios. In terms of diversity, compared with real-world scenes, borrowing knowledge from another dataset inherently has a limited diversity. Currently, the diffusion model stands out as an innovative generative approach. Large-scale trained diffusion models have a strong generative prior that enables real-world modeling of images to generate diverse and realistic images. In this paper, we propose Diff-Mosaic, a data augmentation method based on the diffusion model. This model effectively alleviates the challenge of diversity and realism of data augmentation methods via diffusion prior. Specifically, our method consists of two stages. Firstly, we introduce an enhancement network called Pixel-Prior, which generates highly coordinated and realistic Mosaic images by harmonizing pixels. In the second stage, we propose an image enhancement strategy named Diff-Prior. This strategy utilizes diffusion priors to model images in the real-world scene, further enhancing the diversity and realism of the images. Extensive experiments have demonstrated that our approach significantly improves the performance of the detection network. The code is available at https://github.com/YupeiLin2388/Diff-Mosaic
IDF-CR: Iterative Diffusion Process for Divide-and-Conquer Cloud Removal in Remote-sensing Images
Mar 18, 2024



Deep learning technologies have demonstrated their effectiveness in removing cloud cover from optical remote-sensing images. Convolutional Neural Networks (CNNs) exert dominance in the cloud removal tasks. However, constrained by the inherent limitations of convolutional operations, CNNs can address only a modest fraction of cloud occlusion. In recent years, diffusion models have achieved state-of-the-art (SOTA) proficiency in image generation and reconstruction due to their formidable generative capabilities. Inspired by the rapid development of diffusion models, we first present an iterative diffusion process for cloud removal (IDF-CR), which exhibits a strong generative capabilities to achieve component divide-and-conquer cloud removal. IDF-CR consists of a pixel space cloud removal module (Pixel-CR) and a latent space iterative noise diffusion network (IND). Specifically, IDF-CR is divided into two-stage models that address pixel space and latent space. The two-stage model facilitates a strategic transition from preliminary cloud reduction to meticulous detail refinement. In the pixel space stage, Pixel-CR initiates the processing of cloudy images, yielding a suboptimal cloud removal prior to providing the diffusion model with prior cloud removal knowledge. In the latent space stage, the diffusion model transforms low-quality cloud removal into high-quality clean output. We refine the Stable Diffusion by implementing ControlNet. In addition, an unsupervised iterative noise refinement (INR) module is introduced for diffusion model to optimize the distribution of the predicted noise, thereby enhancing advanced detail recovery. Our model performs best with other SOTA methods, including image reconstruction and optical remote-sensing cloud removal on the optical remote-sensing datasets.
SIRST-5K: Exploring Massive Negatives Synthesis with Self-supervised Learning for Robust Infrared Small Target Detection
Mar 08, 2024



Single-frame infrared small target (SIRST) detection aims to recognize small targets from clutter backgrounds. Recently, convolutional neural networks have achieved significant advantages in general object detection. With the development of Transformer, the scale of SIRST models is constantly increasing. Due to the limited training samples, performance has not been improved accordingly. The quality, quantity, and diversity of the infrared dataset are critical to the detection of small targets. To highlight this issue, we propose a negative sample augmentation method in this paper. Specifically, a negative augmentation approach is proposed to generate massive negatives for self-supervised learning. Firstly, we perform a sequential noise modeling technology to generate realistic infrared data. Secondly, we fuse the extracted noise with the original data to facilitate diversity and fidelity in the generated data. Lastly, we proposed a negative augmentation strategy to enrich diversity as well as maintain semantic invariance. The proposed algorithm produces a synthetic SIRST-5K dataset, which contains massive pseudo-data and corresponding labels. With a rich diversity of infrared small target data, our algorithm significantly improves the model performance and convergence speed. Compared with other state-of-the-art (SOTA) methods, our method achieves outstanding performance in terms of probability of detection (Pd), false-alarm rate (Fa), and intersection over union (IoU).
DNA Family: Boosting Weight-Sharing NAS with Block-Wise Supervisions
Mar 02, 2024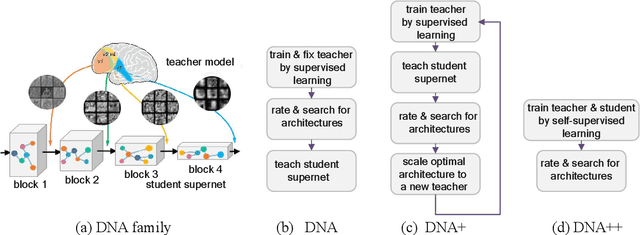
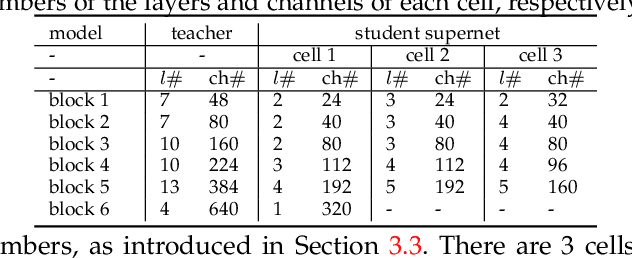
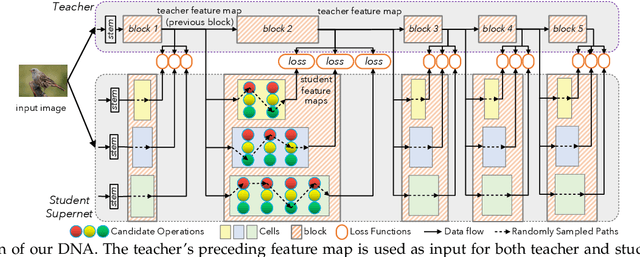
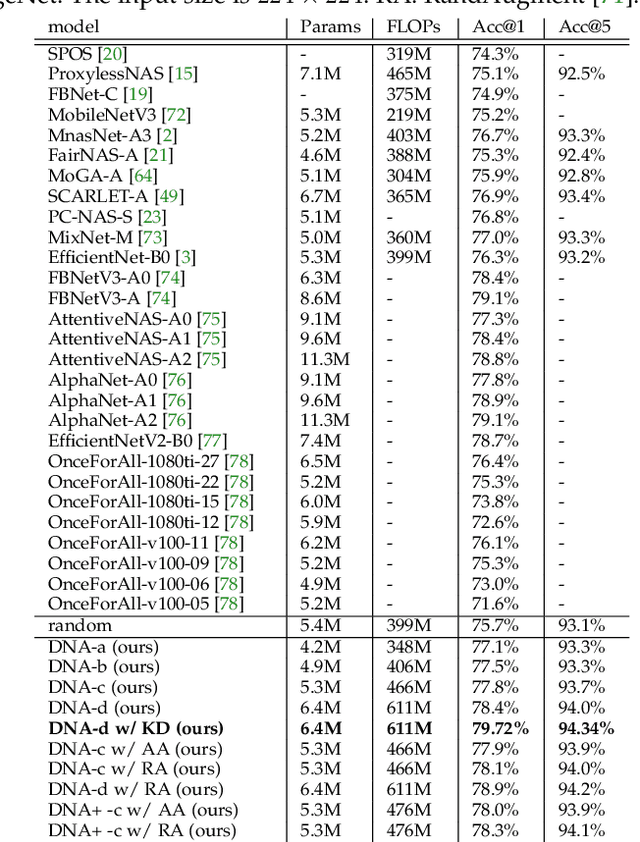
Neural Architecture Search (NAS), aiming at automatically designing neural architectures by machines, has been considered a key step toward automatic machine learning. One notable NAS branch is the weight-sharing NAS, which significantly improves search efficiency and allows NAS algorithms to run on ordinary computers. Despite receiving high expectations, this category of methods suffers from low search effectiveness. By employing a generalization boundedness tool, we demonstrate that the devil behind this drawback is the untrustworthy architecture rating with the oversized search space of the possible architectures. Addressing this problem, we modularize a large search space into blocks with small search spaces and develop a family of models with the distilling neural architecture (DNA) techniques. These proposed models, namely a DNA family, are capable of resolving multiple dilemmas of the weight-sharing NAS, such as scalability, efficiency, and multi-modal compatibility. Our proposed DNA models can rate all architecture candidates, as opposed to previous works that can only access a subsearch space using heuristic algorithms. Moreover, under a certain computational complexity constraint, our method can seek architectures with different depths and widths. Extensive experimental evaluations show that our models achieve state-of-the-art top-1 accuracy of 78.9% and 83.6% on ImageNet for a mobile convolutional network and a small vision transformer, respectively. Additionally, we provide in-depth empirical analysis and insights into neural architecture ratings. Codes available: \url{https://github.com/changlin31/DNA}.
NiteDR: Nighttime Image De-Raining with Cross-View Sensor Cooperative Learning for Dynamic Driving Scenes
Feb 28, 2024In real-world environments, outdoor imaging systems are often affected by disturbances such as rain degradation. Especially, in nighttime driving scenes, insufficient and uneven lighting shrouds the scenes in darkness, resulting degradation of both the image quality and visibility. Particularly, in the field of autonomous driving, the visual perception ability of RGB sensors experiences a sharp decline in such harsh scenarios. Additionally, driving assistance systems suffer from reduced capabilities in capturing and discerning the surrounding environment, posing a threat to driving safety. Single-view information captured by single-modal sensors cannot comprehensively depict the entire scene. To address these challenges, we developed an image de-raining framework tailored for rainy nighttime driving scenes. It aims to remove rain artifacts, enrich scene representation, and restore useful information. Specifically, we introduce cooperative learning between visible and infrared images captured by different sensors. By cross-view fusion of these multi-source data, the scene within the images gains richer texture details and enhanced contrast. We constructed an information cleaning module called CleanNet as the first stage of our framework. Moreover, we designed an information fusion module called FusionNet as the second stage to fuse the clean visible images with infrared images. Using this stage-by-stage learning strategy, we obtain de-rained fusion images with higher quality and better visual perception. Extensive experiments demonstrate the effectiveness of our proposed Cross-View Cooperative Learning (CVCL) in adverse driving scenarios in low-light rainy environments. The proposed approach addresses the gap in the utilization of existing rain removal algorithms in specific low-light conditions.
MirrorDiffusion: Stabilizing Diffusion Process in Zero-shot Image Translation by Prompts Redescription and Beyond
Jan 06, 2024Recently, text-to-image diffusion models become a new paradigm in image processing fields, including content generation, image restoration and image-to-image translation. Given a target prompt, Denoising Diffusion Probabilistic Models (DDPM) are able to generate realistic yet eligible images. With this appealing property, the image translation task has the potential to be free from target image samples for supervision. By using a target text prompt for domain adaption, the diffusion model is able to implement zero-shot image-to-image translation advantageously. However, the sampling and inversion processes of DDPM are stochastic, and thus the inversion process often fail to reconstruct the input content. Specifically, the displacement effect will gradually accumulated during the diffusion and inversion processes, which led to the reconstructed results deviating from the source domain. To make reconstruction explicit, we propose a prompt redescription strategy to realize a mirror effect between the source and reconstructed image in the diffusion model (MirrorDiffusion). More specifically, a prompt redescription mechanism is investigated to align the text prompts with latent code at each time step of the Denoising Diffusion Implicit Models (DDIM) inversion to pursue a structure-preserving reconstruction. With the revised DDIM inversion, MirrorDiffusion is able to realize accurate zero-shot image translation by editing optimized text prompts and latent code. Extensive experiments demonstrate that MirrorDiffusion achieves superior performance over the state-of-the-art methods on zero-shot image translation benchmarks by clear margins and practical model stability.
NegVSR: Augmenting Negatives for Generalized Noise Modeling in Real-World Video Super-Resolution
May 24, 2023The capability of video super-resolution (VSR) to synthesize high-resolution (HR) video from ideal datasets has been demonstrated in many works. However, applying the VSR model to real-world video with unknown and complex degradation remains a challenging task. First, existing degradation metrics in most VSR methods are not able to effectively simulate real-world noise and blur. On the contrary, simple combinations of classical degradation are used for real-world noise modeling, which led to the VSR model often being violated by out-of-distribution noise. Second, many SR models focus on noise simulation and transfer. Nevertheless, the sampled noise is monotonous and limited. To address the aforementioned problems, we propose a Negatives augmentation strategy for generalized noise modeling in Video Super-Resolution (NegVSR) task. Specifically, we first propose sequential noise generation toward real-world data to extract practical noise sequences. Then, the degeneration domain is widely expanded by negative augmentation to build up various yet challenging real-world noise sets. We further propose the augmented negative guidance loss to learn robust features among augmented negatives effectively. Extensive experiments on real-world datasets (e.g., VideoLQ and FLIR) show that our method outperforms state-of-the-art methods with clear margins, especially in visual quality.
Open-World Pose Transfer via Sequential Test-Time Adaption
Mar 20, 2023



Pose transfer aims to transfer a given person into a specified posture, has recently attracted considerable attention. A typical pose transfer framework usually employs representative datasets to train a discriminative model, which is often violated by out-of-distribution (OOD) instances. Recently, test-time adaption (TTA) offers a feasible solution for OOD data by using a pre-trained model that learns essential features with self-supervision. However, those methods implicitly make an assumption that all test distributions have a unified signal that can be learned directly. In open-world conditions, the pose transfer task raises various independent signals: OOD appearance and skeleton, which need to be extracted and distributed in speciality. To address this point, we develop a SEquential Test-time Adaption (SETA). In the test-time phrase, SETA extracts and distributes external appearance texture by augmenting OOD data for self-supervised training. To make non-Euclidean similarity among different postures explicit, SETA uses the image representations derived from a person re-identification (Re-ID) model for similarity computation. By addressing implicit posture representation in the test-time sequentially, SETA greatly improves the generalization performance of current pose transfer models. In our experiment, we first show that pose transfer can be applied to open-world applications, including Tiktok reenactment and celebrity motion synthesis.