 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
DNA Family: Boosting Weight-Sharing NAS with Block-Wise Supervisions
Mar 02, 2024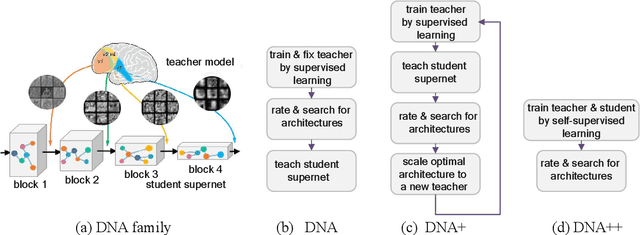
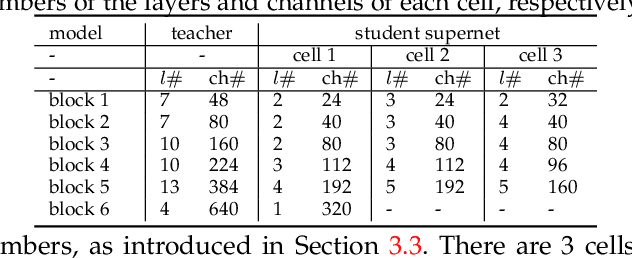
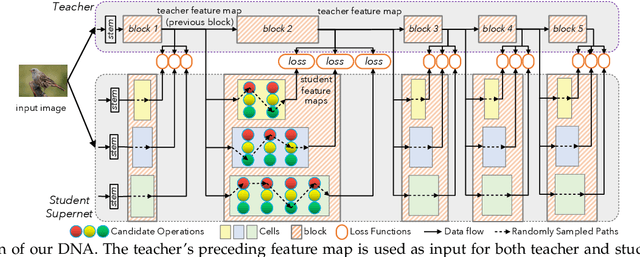
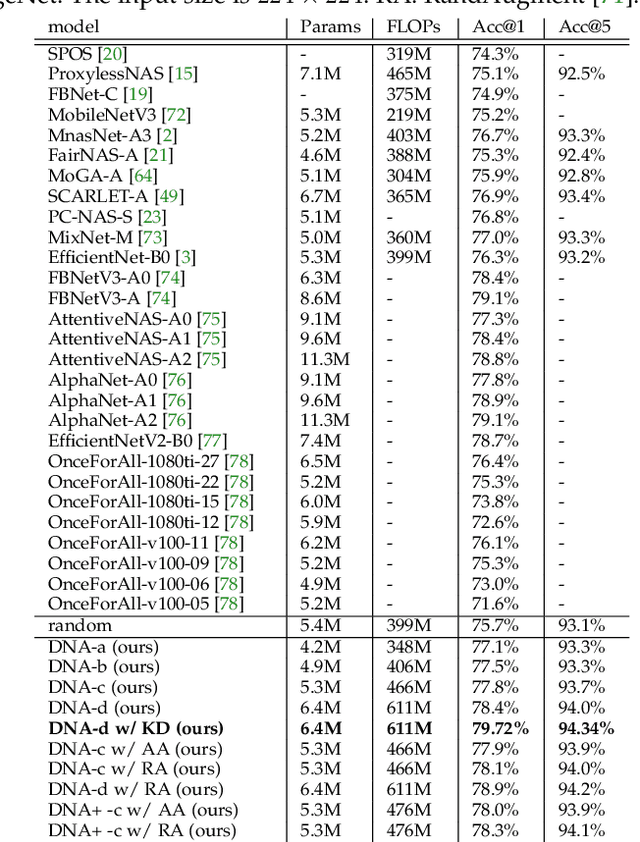
Neural Architecture Search (NAS), aiming at automatically designing neural architectures by machines, has been considered a key step toward automatic machine learning. One notable NAS branch is the weight-sharing NAS, which significantly improves search efficiency and allows NAS algorithms to run on ordinary computers. Despite receiving high expectations, this category of methods suffers from low search effectiveness. By employing a generalization boundedness tool, we demonstrate that the devil behind this drawback is the untrustworthy architecture rating with the oversized search space of the possible architectures. Addressing this problem, we modularize a large search space into blocks with small search spaces and develop a family of models with the distilling neural architecture (DNA) techniques. These proposed models, namely a DNA family, are capable of resolving multiple dilemmas of the weight-sharing NAS, such as scalability, efficiency, and multi-modal compatibility. Our proposed DNA models can rate all architecture candidates, as opposed to previous works that can only access a subsearch space using heuristic algorithms. Moreover, under a certain computational complexity constraint, our method can seek architectures with different depths and widths. Extensive experimental evaluations show that our models achieve state-of-the-art top-1 accuracy of 78.9% and 83.6% on ImageNet for a mobile convolutional network and a small vision transformer, respectively. Additionally, we provide in-depth empirical analysis and insights into neural architecture ratings. Codes available: \url{https://github.com/changlin31/DNA}.
NeRF-VPT: Learning Novel View Representations with Neural Radiance Fields via View Prompt Tuning
Mar 02, 2024
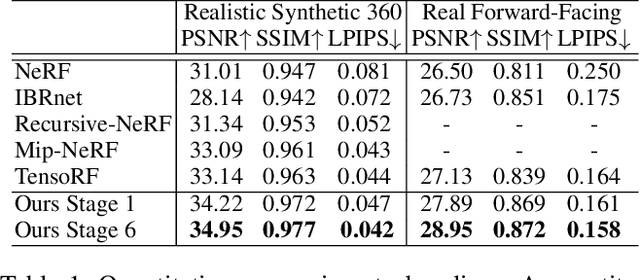

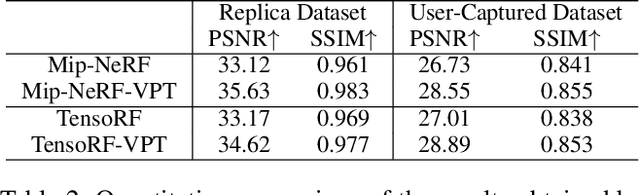
Neural Radiance Fields (NeRF) have garnered remarkable success in novel view synthesis. Nonetheless, the task of generating high-quality images for novel views persists as a critical challenge. While the existing efforts have exhibited commendable progress, capturing intricate details, enhancing textures, and achieving superior Peak Signal-to-Noise Ratio (PSNR) metrics warrant further focused attention and advancement. In this work, we propose NeRF-VPT, an innovative method for novel view synthesis to address these challenges. Our proposed NeRF-VPT employs a cascading view prompt tuning paradigm, wherein RGB information gained from preceding rendering outcomes serves as instructive visual prompts for subsequent rendering stages, with the aspiration that the prior knowledge embedded in the prompts can facilitate the gradual enhancement of rendered image quality. NeRF-VPT only requires sampling RGB data from previous stage renderings as priors at each training stage, without relying on extra guidance or complex techniques. Thus, our NeRF-VPT is plug-and-play and can be readily integrated into existing methods. By conducting comparative analyses of our NeRF-VPT against several NeRF-based approaches on demanding real-scene benchmarks, such as Realistic Synthetic 360, Real Forward-Facing, Replica dataset, and a user-captured dataset, we substantiate that our NeRF-VPT significantly elevates baseline performance and proficiently generates more high-quality novel view images than all the compared state-of-the-art methods. Furthermore, the cascading learning of NeRF-VPT introduces adaptability to scenarios with sparse inputs, resulting in a significant enhancement of accuracy for sparse-view novel view synthesis. The source code and dataset are available at \url{https://github.com/Freedomcls/NeRF-VPT}.
PredNAS: A Universal and Sample Efficient Neural Architecture Search Framework
Oct 26, 2022In this paper, we present a general and effective framework for Neural Architecture Search (NAS), named PredNAS. The motivation is that given a differentiable performance estimation function, we can directly optimize the architecture towards higher performance by simple gradient ascent. Specifically, we adopt a neural predictor as the performance predictor. Surprisingly, PredNAS can achieve state-of-the-art performances on NAS benchmarks with only a few training samples (less than 100). To validate the universality of our method, we also apply our method on large-scale tasks and compare our method with RegNet on ImageNet and YOLOX on MSCOCO. The results demonstrate that our PredNAS can explore novel architectures with competitive performances under specific computational complexity constraints.
Blockwisely Supervised Neural Architecture Search with Knowledge Distillation
Nov 29, 2019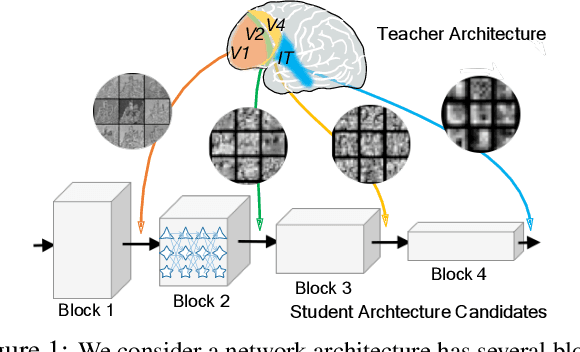
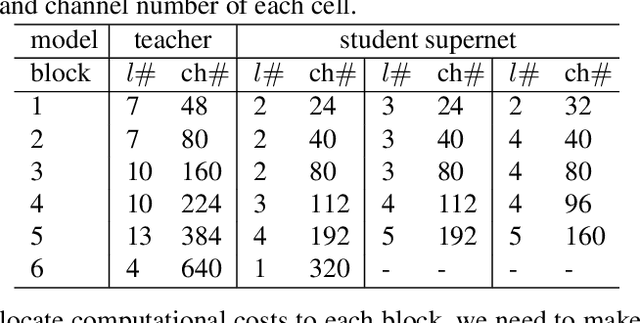
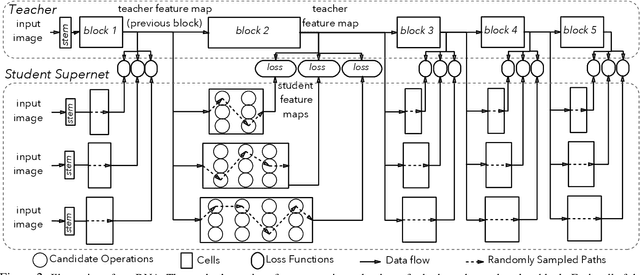
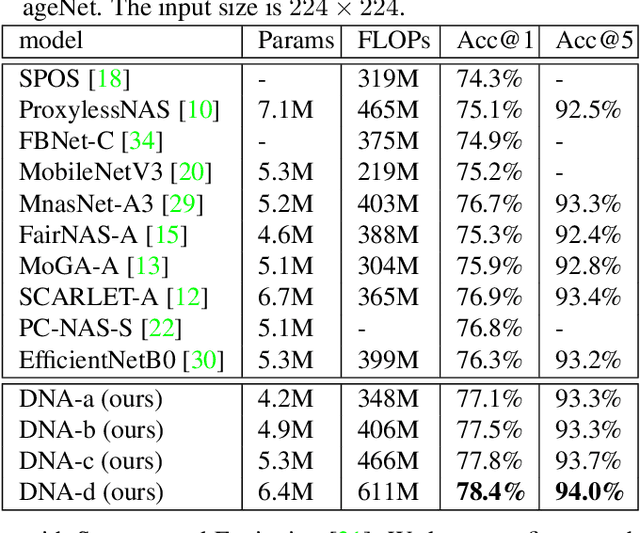
Neural Architecture Search (NAS), aiming at automatically designing network architectures by machines, is hoped and expected to bring about a new revolution in machine learning. Despite these high expectation, the effectiveness and efficiency of existing NAS solutions are unclear, with some recent works going so far as to suggest that many existing NAS solutions are no better than random architecture selection. The inefficiency of NAS solutions may be attributed to inaccurate architecture evaluation. Specifically, to speed up NAS, recent works have proposed under-training different candidate architectures in a large search space concurrently by using shared network parameters; however, this has resulted in incorrect architecture ratings and furthered the ineffectiveness of NAS. In this work, we propose to modularize the large search space of NAS into blocks to ensure that the potential candidate architectures are fully trained; this reduces the representation shift caused by the shared parameters and leads to the correct rating of the candidates. Thanks to the block-wise search, we can also evaluate all of the candidate architectures within a block. Moreover, we find that the knowledge of a network model lies not only in the network parameters but also in the network architecture. Therefore, we propose to distill the neural architecture (DNA) knowledge from a teacher model as the supervision to guide our block-wise architecture search, which significantly improves the effectiveness of NAS. Remarkably, the capacity of our searched architecture has exceeded the teacher model, demonstrating the practicability and scalability of our method. Finally, our method achieves a state-of-the-art 78.4\% top-1 accuracy on ImageNet in a mobile setting, which is about a 2.1\% gain over EfficientNet-B0. All of our searched models along with the evaluation code are available online.