 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentPilot: Scene-Aware Vision-and-Language Navigation by Dreaming Ahead with Latent Visual Reasoning
Mar 31, 2026Existing vision-and-language navigation (VLN) models primarily reason over past and current visual observations, while largely ignoring the future visual dynamics induced by actions. As a result, they often lack an effective understanding of the causal relationship between actions and how the visual world changes, limiting robust decision-making. Humans, in contrast, can imagine the near future by leveraging action-dynamics causality, which improves both environmental understanding and navigation choices. Inspired by this capability, we propose LatentPilot, a new paradigm that exploits future observations during training as a valuable data source to learn action-conditioned visual dynamics, while requiring no access to future frames at inference. Concretely, we propose a flywheel-style training mechanism that iteratively collects on-policy trajectories and retrains the model to better match the agent's behavior distribution, with an expert takeover triggered when the agent deviates excessively. LatentPilot further learns visual latent tokens without explicit supervision; these latent tokens attend globally in a continuous latent space and are carried across steps, serving as both the current output and the next input, thereby enabling the agent to dream ahead and reason about how actions will affect subsequent observations. Experiments on R2R-CE, RxR-CE, and R2R-PE benchmarks achieve new SOTA results, and real-robot tests across diverse environments demonstrate LatentPilot's superior understanding of environment-action dynamics in scene. Project page:https://abdd.top/latentpilot/
GeoSense: Internalizing Geometric Necessity Perception for Multimodal Reasoning
Mar 11, 2026Advancing towards artificial superintelligence requires rich and intelligent perceptual capabilities. A critical frontier in this pursuit is overcoming the limited spatial understanding of Multimodal Large Language Models (MLLMs), where geometry information is essential. Existing methods often address this by rigidly injecting geometric signals into every input, while ignoring their necessity and adding computation overhead. Contrary to this paradigm, our framework endows the model with an awareness of perceptual insufficiency, empowering it to autonomously engage geometric features in reasoning when 2D cues are deemed insufficient. To achieve this, we first introduce an independent geometry input channel to the model architecture and conduct alignment training, enabling the effective utilization of geometric features. Subsequently, to endow the model with perceptual awareness, we curate a dedicated spatial-aware supervised fine-tuning dataset. This serves to activate the model's latent internal cues, empowering it to autonomously determine the necessity of geometric information. Experiments across multiple spatial reasoning benchmarks validate this approach, demonstrating significant spatial gains without compromising 2D visual reasoning capabilities, offering a path toward more robust, efficient and self-aware multi-modal intelligence.
DisCa: Accelerating Video Diffusion Transformers with Distillation-Compatible Learnable Feature Caching
Feb 05, 2026While diffusion models have achieved great success in the field of video generation, this progress is accompanied by a rapidly escalating computational burden. Among the existing acceleration methods, Feature Caching is popular due to its training-free property and considerable speedup performance, but it inevitably faces semantic and detail drop with further compression. Another widely adopted method, training-aware step-distillation, though successful in image generation, also faces drastic degradation in video generation with a few steps. Furthermore, the quality loss becomes more severe when simply applying training-free feature caching to the step-distilled models, due to the sparser sampling steps. This paper novelly introduces a distillation-compatible learnable feature caching mechanism for the first time. We employ a lightweight learnable neural predictor instead of traditional training-free heuristics for diffusion models, enabling a more accurate capture of the high-dimensional feature evolution process. Furthermore, we explore the challenges of highly compressed distillation on large-scale video models and propose a conservative Restricted MeanFlow approach to achieve more stable and lossless distillation. By undertaking these initiatives, we further push the acceleration boundaries to $11.8\times$ while preserving generation quality. Extensive experiments demonstrate the effectiveness of our method. The code is in the supplementary materials and will be publicly available.
Do VLMs Perceive or Recall? Probing Visual Perception vs. Memory with Classic Visual Illusions
Jan 29, 2026Large Vision-Language Models (VLMs) often answer classic visual illusions "correctly" on original images, yet persist with the same responses when illusion factors are inverted, even though the visual change is obvious to humans. This raises a fundamental question: do VLMs perceive visual changes or merely recall memorized patterns? While several studies have noted this phenomenon, the underlying causes remain unclear. To move from observations to systematic understanding, this paper introduces VI-Probe, a controllable visual-illusion framework with graded perturbations and matched visual controls (without illusion inducer) that disentangles visually grounded perception from language-driven recall. Unlike prior work that focuses on averaged accuracy, we measure stability and sensitivity using Polarity-Flip Consistency, Template Fixation Index, and an illusion multiplier normalized against matched controls. Experiments across different families reveal that response persistence arises from heterogeneous causes rather than a single mechanism. For instance, GPT-5 exhibits memory override, Claude-Opus-4.1 shows perception-memory competition, while Qwen variants suggest visual-processing limits. Our findings challenge single-cause views and motivate probing-based evaluation that measures both knowledge and sensitivity to controlled visual change. Data and code are available at https://sites.google.com/view/vi-probe/.
CoNav: Collaborative Cross-Modal Reasoning for Embodied Navigation
May 22, 2025Embodied navigation demands comprehensive scene understanding and precise spatial reasoning. While image-text models excel at interpreting pixel-level color and lighting cues, 3D-text models capture volumetric structure and spatial relationships. However, unified fusion approaches that jointly fuse 2D images, 3D point clouds, and textual instructions face challenges in limited availability of triple-modality data and difficulty resolving conflicting beliefs among modalities. In this work, we introduce CoNav, a collaborative cross-modal reasoning framework where a pretrained 3D-text model explicitly guides an image-text navigation agent by providing structured spatial-semantic knowledge to resolve ambiguities during navigation. Specifically, we introduce Cross-Modal Belief Alignment, which operationalizes this cross-modal guidance by simply sharing textual hypotheses from the 3D-text model to the navigation agent. Through lightweight fine-tuning on a small 2D-3D-text corpus, the navigation agent learns to integrate visual cues with spatial-semantic knowledge derived from the 3D-text model, enabling effective reasoning in embodied navigation. CoNav achieves significant improvements on four standard embodied navigation benchmarks (R2R, CVDN, REVERIE, SOON) and two spatial reasoning benchmarks (ScanQA, SQA3D). Moreover, under close navigation Success Rate, CoNav often generates shorter paths compared to other methods (as measured by SPL), showcasing the potential and challenges of fusing data from different modalities in embodied navigation. Project Page: https://oceanhao.github.io/CoNav/
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
DiffuTraj: A Stochastic Vessel Trajectory Prediction Approach via Guided Diffusion Process
Oct 12, 2024Maritime vessel maneuvers, characterized by their inherent complexity and indeterminacy, requires vessel trajectory prediction system capable of modeling the multi-modality nature of future motion states. Conventional stochastic trajectory prediction methods utilize latent variables to represent the multi-modality of vessel motion, however, tends to overlook the complexity and dynamics inherent in maritime behavior. In contrast, we explicitly simulate the transition of vessel motion from uncertainty towards a state of certainty, effectively handling future indeterminacy in dynamic scenes. In this paper, we present a novel framework (\textit{DiffuTraj}) to conceptualize the trajectory prediction task as a guided reverse process of motion pattern uncertainty diffusion, in which we progressively remove uncertainty from maritime regions to delineate the intended trajectory. Specifically, we encode the previous states of the target vessel, vessel-vessel interactions, and the environment context as guiding factors for trajectory generation. Subsequently, we devise a transformer-based conditional denoiser to capture spatio-temporal dependencies, enabling the generation of trajectories better aligned for particular maritime environment. Comprehensive experiments on vessel trajectory prediction benchmarks demonstrate the superiority of our method.
Ada-adapter:Fast Few-shot Style Personlization of Diffusion Model with Pre-trained Image Encoder
Jul 08, 2024



Fine-tuning advanced diffusion models for high-quality image stylization usually requires large training datasets and substantial computational resources, hindering their practical applicability. We propose Ada-Adapter, a novel framework for few-shot style personalization of diffusion models. Ada-Adapter leverages off-the-shelf diffusion models and pre-trained image feature encoders to learn a compact style representation from a limited set of source images. Our method enables efficient zero-shot style transfer utilizing a single reference image. Furthermore, with a small number of source images (three to five are sufficient) and a few minutes of fine-tuning, our method can capture intricate style details and conceptual characteristics, generating high-fidelity stylized images that align well with the provided text prompts. We demonstrate the effectiveness of our approach on various artistic styles, including flat art, 3D rendering, and logo design. Our experimental results show that Ada-Adapter outperforms existing zero-shot and few-shot stylization methods in terms of output quality, diversity, and training efficiency.
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Apr 10, 2024



Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at \url{https://github.com/mulns/PerVFI}
DNA Family: Boosting Weight-Sharing NAS with Block-Wise Supervisions
Mar 02, 2024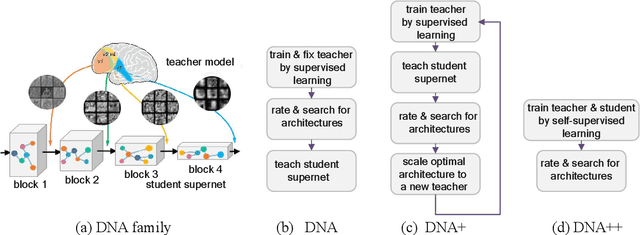
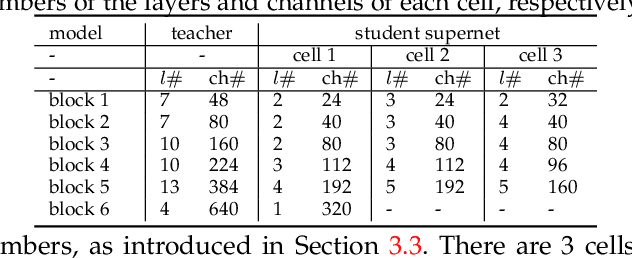
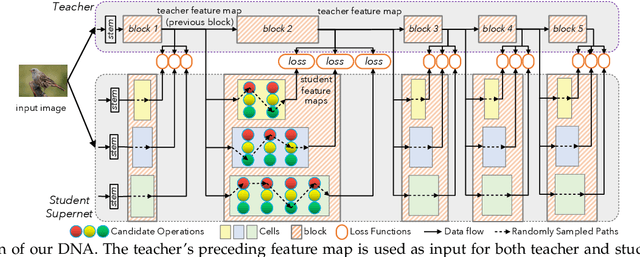
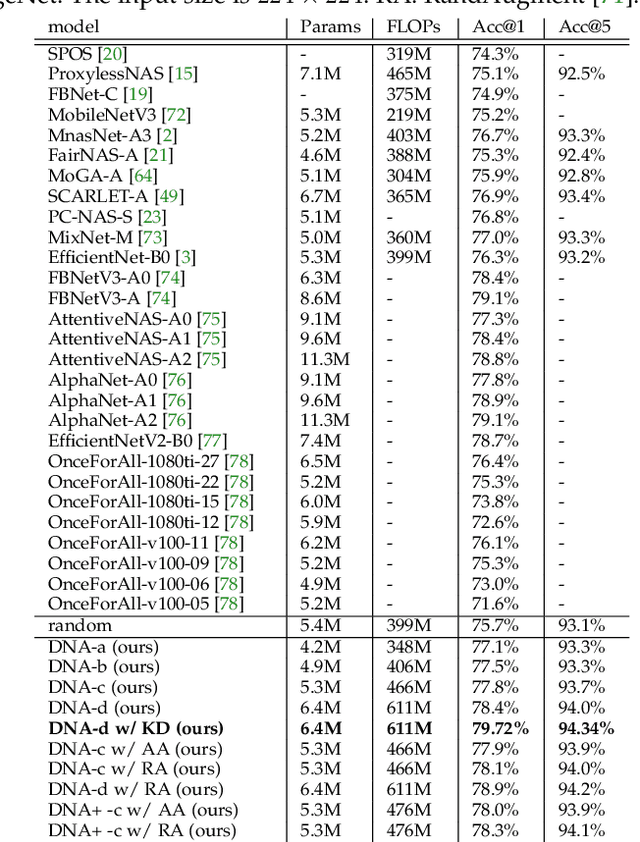
Neural Architecture Search (NAS), aiming at automatically designing neural architectures by machines, has been considered a key step toward automatic machine learning. One notable NAS branch is the weight-sharing NAS, which significantly improves search efficiency and allows NAS algorithms to run on ordinary computers. Despite receiving high expectations, this category of methods suffers from low search effectiveness. By employing a generalization boundedness tool, we demonstrate that the devil behind this drawback is the untrustworthy architecture rating with the oversized search space of the possible architectures. Addressing this problem, we modularize a large search space into blocks with small search spaces and develop a family of models with the distilling neural architecture (DNA) techniques. These proposed models, namely a DNA family, are capable of resolving multiple dilemmas of the weight-sharing NAS, such as scalability, efficiency, and multi-modal compatibility. Our proposed DNA models can rate all architecture candidates, as opposed to previous works that can only access a subsearch space using heuristic algorithms. Moreover, under a certain computational complexity constraint, our method can seek architectures with different depths and widths. Extensive experimental evaluations show that our models achieve state-of-the-art top-1 accuracy of 78.9% and 83.6% on ImageNet for a mobile convolutional network and a small vision transformer, respectively. Additionally, we provide in-depth empirical analysis and insights into neural architecture ratings. Codes available: \url{https://github.com/changlin31/DNA}.