 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuDD: A Multimodal Deception Detection Dataset and GSR-Guided Progressive Distillation for Non-Contact Deception Detection
Mar 27, 2026Non-contact automatic deception detection remains challenging because visual and auditory deception cues often lack stable cross-subject patterns. In contrast, galvanic skin response (GSR) provides more reliable physiological cues and has been widely used in contact-based deception detection. In this work, we leverage stable deception-related knowledge in GSR to guide representation learning in non-contact modalities through cross-modal knowledge distillation. A key obstacle, however, is the lack of a suitable dataset for this setting. To address this, we introduce MuDD, a large-scale Multimodal Deception Detection dataset containing recordings from 130 participants over 690 minutes. In addition to video, audio, and GSR, MuDD also provides Photoplethysmography, heart rate, and personality traits, supporting broader scientific studies of deception. Based on this dataset, we propose GSR-guided Progressive Distillation (GPD), a cross-modal distillation framework for mitigating the negative transfer caused by the large modality mismatch between GSR and non-contact signals. The core innovation of GPD is the integration of progressive feature-level and digit-level distillation with dynamic routing, which allows the model to adaptively determine how teacher knowledge should be transferred during training, leading to more stable cross-modal knowledge transfer. Extensive experiments and visualizations show that GPD outperforms existing methods and achieves state-of-the-art performance on both deception detection and concealed-digit identification.
LLM-Driven Reasoning for Constraint-Aware Feature Selection in Industrial Systems
Mar 26, 2026Feature selection is a crucial step in large-scale industrial machine learning systems, directly affecting model accuracy, efficiency, and maintainability. Traditional feature selection methods rely on labeled data and statistical heuristics, making them difficult to apply in production environments where labeled data are limited and multiple operational constraints must be satisfied. To address this, we propose Model Feature Agent (MoFA), a model-driven framework that performs sequential, reasoning-based feature selection using both semantic and quantitative feature information. MoFA incorporates feature definitions, importance scores, correlations, and metadata (e.g., feature groups or types) into structured prompts and selects features through interpretable, constraint-aware reasoning. We evaluate MoFA in three real-world industrial applications: (1) True Interest and Time-Worthiness Prediction, where it improves accuracy while reducing feature group complexity, (2) Value Model Enhancement, where it discovers high-order interaction terms that yield substantial engagement gains in online experiments, and (3) Notification Behavior Prediction, where it selects compact, high-value feature subsets that improve both model accuracy and inference efficiency. Together, these results demonstrate the practicality and effectiveness of LLM-based reasoning for feature selection in real production systems.
GenLie: A Global-Enhanced Lie Detection Network under Sparsity and Semantic Interference
Mar 14, 2026Video-based lie detection aims to identify deceptive behaviors from visual cues. Despite recent progress, its core challenge lies in learning sparse yet discriminative representations. Deceptive signals are typically subtle and short-lived, easily overwhelmed by redundant information, while individual and contextual variations introduce strong identity-related noise. To address this issue, we propose GenLie, a Global-Enhanced Lie Detection Network that performs local feature modeling under global supervision. Specifically, sparse and subtle deceptive cues are captured at the local level, while global supervision and optimization ensure robust and discriminative representations by suppressing identity-related noise. Experiments on three public datasets, covering both high- and low-stakes scenarios, show that GenLie consistently outperforms state-of-the-art methods. Source code is available at https://github.com/AliasDictusZ1/GenLie.
Bridging Discrete Marks and Continuous Dynamics: Dual-Path Cross-Interaction for Marked Temporal Point Processes
Mar 12, 2026Predicting irregularly spaced event sequences with discrete marks poses significant challenges due to the complex, asynchronous dependencies embedded within continuous-time data streams.Existing sequential approaches capture dependencies among event tokens but ignore the continuous evolution between events, while Neural Ordinary Differential Equation (Neural ODE) methods model smooth dynamics yet fail to account for how event types influence future timing.To overcome these limitations, we propose NEXTPP, a dual-channel framework that unifies discrete and continuous representations via Event-granular Neural Evolution with Cross-Interaction for Marked Temporal Point Processes. Specifically, NEXTPP encodes discrete event marks via a self-attention mechanism, simultaneously evolving a latent continuous-time state using a Neural ODE. These parallel streams are then fused through a crossattention module to enable explicit bidirectional interaction between continuous and discrete representations. The fused representations drive the conditional intensity function of the neural Hawkes process, while an iterative thinning sampler is employed to generate future events. Extensive evaluations on five real-world datasets demonstrate that NEXTPP consistently outperforms state-of-the-art models. The source code can be found at https://github.com/AONE-NLP/NEXTPP.
Negative-Aware Diffusion Process for Temporal Knowledge Graph Extrapolation
Feb 09, 2026Temporal Knowledge Graph (TKG) reasoning seeks to predict future missing facts from historical evidence. While diffusion models (DM) have recently gained attention for their ability to capture complex predictive distributions, two gaps remain: (i) the generative path is conditioned only on positive evidence, overlooking informative negative context, and (ii) training objectives are dominated by cross-entropy ranking, which improves candidate ordering but provides little supervision over the calibration of the denoised embedding. To bridge this gap, we introduce Negative-Aware Diffusion model for TKG Extrapolation (NADEx). Specifically, NADEx encodes subject-centric histories of entities, relations and temporal intervals into sequential embeddings. NADEx perturbs the query object in the forward process and reconstructs it in reverse with a Transformer denoiser conditioned on the temporal-relational context. We further derive a cosine-alignment regularizer derived from batch-wise negative prototypes, which tightens the decision boundary against implausible candidates. Comprehensive experiments on four public TKG benchmarks demonstrate that NADEx delivers state-of-the-art performance.
XEmoGPT: An Explainable Multimodal Emotion Recognition Framework with Cue-Level Perception and Reasoning
Feb 05, 2026Explainable Multimodal Emotion Recognition plays a crucial role in applications such as human-computer interaction and social media analytics. However, current approaches struggle with cue-level perception and reasoning due to two main challenges: 1) general-purpose modality encoders are pretrained to capture global structures and general semantics rather than fine-grained emotional cues, resulting in limited sensitivity to emotional signals; and 2) available datasets usually involve a trade-off between annotation quality and scale, which leads to insufficient supervision for emotional cues and ultimately limits cue-level reasoning. Moreover, existing evaluation metrics are inadequate for assessing cue-level reasoning performance. To address these challenges, we propose eXplainable Emotion GPT (XEmoGPT), a novel EMER framework capable of both perceiving and reasoning over emotional cues. It incorporates two specialized modules: the Video Emotional Cue Bridge (VECB) and the Audio Emotional Cue Bridge (AECB), which enhance the video and audio encoders through carefully designed tasks for fine-grained emotional cue perception. To further support cue-level reasoning, we construct a large-scale dataset, EmoCue, designed to teach XEmoGPT how to reason over multimodal emotional cues. In addition, we introduce EmoCue-360, an automated metric that extracts and matches emotional cues using semantic similarity, and release EmoCue-Eval, a benchmark of 400 expert-annotated samples covering diverse emotional scenarios. Experimental results show that XEmoGPT achieves strong performance in both emotional cue perception and reasoning.
FusionFM: All-in-One Multi-Modal Image Fusion with Flow Matching
Nov 17, 2025Current multi-modal image fusion methods typically rely on task-specific models, leading to high training costs and limited scalability. While generative methods provide a unified modeling perspective, they often suffer from slow inference due to the complex sampling trajectories from noise to image. To address this, we formulate image fusion as a direct probabilistic transport from source modalities to the fused image distribution, leveraging the flow matching paradigm to improve sampling efficiency and structural consistency. To mitigate the lack of high-quality fused images for supervision, we collect fusion results from multiple state-of-the-art models as priors, and employ a task-aware selection function to select the most reliable pseudo-labels for each task. We further introduce a Fusion Refiner module that employs a divide-and-conquer strategy to systematically identify, decompose, and enhance degraded components in selected pseudo-labels. For multi-task scenarios, we integrate elastic weight consolidation and experience replay mechanisms to preserve cross-task performance and enhance continual learning ability from both parameter stability and memory retention perspectives. Our approach achieves competitive performance across diverse fusion tasks, while significantly improving sampling efficiency and maintaining a lightweight model design. The code will be available at: https://github.com/Ist-Zhy/FusionFM.
Exploiting Inter-Session Information with Frequency-enhanced Dual-Path Networks for Sequential Recommendation
Nov 14, 2025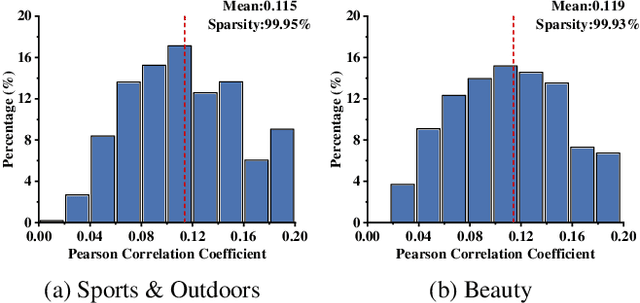
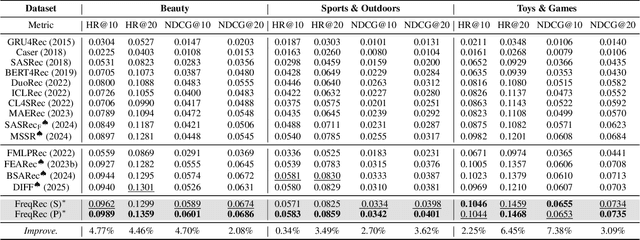
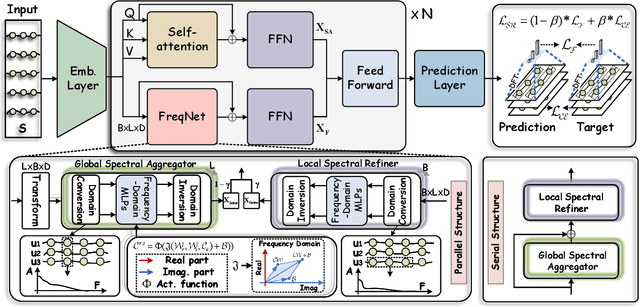
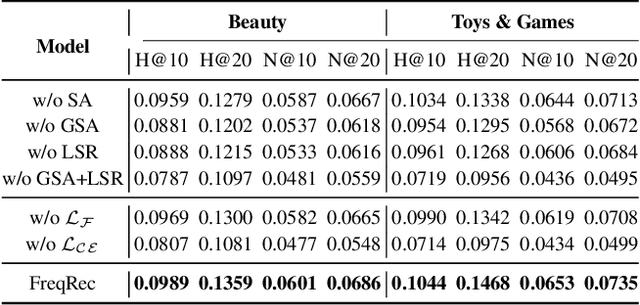
Sequential recommendation (SR) aims to predict a user's next item preference by modeling historical interaction sequences. Recent advances often integrate frequency-domain modules to compensate for self-attention's low-pass nature by restoring the high-frequency signals critical for personalized recommendations. Nevertheless, existing frequency-aware solutions process each session in isolation and optimize exclusively with time-domain objectives. Consequently, they overlook cross-session spectral dependencies and fail to enforce alignment between predicted and actual spectral signatures, leaving valuable frequency information under-exploited. To this end, we propose FreqRec, a Frequency-Enhanced Dual-Path Network for sequential Recommendation that jointly captures inter-session and intra-session behaviors via a learnable Frequency-domain Multi-layer Perceptrons. Moreover, FreqRec is optimized under a composite objective that combines cross entropy with a frequency-domain consistency loss, explicitly aligning predicted and true spectral signatures. Extensive experiments on three benchmarks show that FreqRec surpasses strong baselines and remains robust under data sparsity and noisy-log conditions.
More diverse more adaptive: Comprehensive Multi-task Learning for Improved LLM Domain Adaptation in E-commerce
Apr 09, 2025



In recent years, Large Language Models (LLMs) have been widely applied across various domains due to their powerful domain adaptation capabilities. Previous studies have suggested that diverse, multi-modal data can enhance LLMs' domain adaptation performance. However, this hypothesis remains insufficiently validated in the e-commerce sector. To address this gap, we propose a comprehensive e-commerce multi-task framework and design empirical experiments to examine the impact of diverse data and tasks on LLMs from two perspectives: "capability comprehensiveness" and "task comprehensiveness." Specifically, we observe significant improvements in LLM performance by progressively introducing tasks related to new major capability areas and by continuously adding subtasks within different major capability domains. Furthermore, we observe that increasing model capacity amplifies the benefits of diversity, suggesting a synergistic relationship between model capacity and data diversity. Finally, we validate the best-performing model from our empirical experiments in the KDD Cup 2024, achieving a rank 5 in Task 1. This outcome demonstrates the significance of our research for advancing LLMs in the e-commerce domain.
An AI-powered Bayesian generative modeling approach for causal inference in observational studies
Jan 01, 2025



Causal inference in observational studies with high-dimensional covariates presents significant challenges. We introduce CausalBGM, an AI-powered Bayesian generative modeling approach that captures the causal relationship among covariates, treatment, and outcome variables. The core innovation of CausalBGM lies in its ability to estimate the individual treatment effect (ITE) by learning individual-specific distributions of a low-dimensional latent feature set (e.g., latent confounders) that drives changes in both treatment and outcome. This approach not only effectively mitigates confounding effects but also provides comprehensive uncertainty quantification, offering reliable and interpretable causal effect estimates at the individual level. CausalBGM adopts a Bayesian model and uses a novel iterative algorithm to update the model parameters and the posterior distribution of latent features until convergence. This framework leverages the power of AI to capture complex dependencies among variables while adhering to the Bayesian principles. Extensive experiments demonstrate that CausalBGM consistently outperforms state-of-the-art methods, particularly in scenarios with high-dimensional covariates and large-scale datasets. Its Bayesian foundation ensures statistical rigor, providing robust and well-calibrated posterior intervals. By addressing key limitations of existing methods, CausalBGM emerges as a robust and promising framework for advancing causal inference in modern applications in fields such as genomics, healthcare, and social sciences. CausalBGM is maintained at the website https://causalbgm.readthedocs.io/.