 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-Free Adaptive Bayesian Inference via Nonparametric Distribution Matching
May 07, 2025When the likelihood is analytically unavailable and computationally intractable, approximate Bayesian computation (ABC) has emerged as a widely used methodology for approximate posterior inference; however, it suffers from severe computational inefficiency in high-dimensional settings or under diffuse priors. To overcome these limitations, we propose Adaptive Bayesian Inference (ABI), a framework that bypasses traditional data-space discrepancies and instead compares distributions directly in posterior space through nonparametric distribution matching. By leveraging a novel Marginally-augmented Sliced Wasserstein (MSW) distance on posterior measures and exploiting its quantile representation, ABI transforms the challenging problem of measuring divergence between posterior distributions into a tractable sequence of one-dimensional conditional quantile regression tasks. Moreover, we introduce a new adaptive rejection sampling scheme that iteratively refines the posterior approximation by updating the proposal distribution via generative density estimation. Theoretically, we establish parametric convergence rates for the trimmed MSW distance and prove that the ABI posterior converges to the true posterior as the tolerance threshold vanishes. Through extensive empirical evaluation, we demonstrate that ABI significantly outperforms data-based Wasserstein ABC, summary-based ABC, and state-of-the-art likelihood-free simulators, especially in high-dimensional or dependent observation regimes.
An AI-powered Bayesian generative modeling approach for causal inference in observational studies
Jan 01, 2025



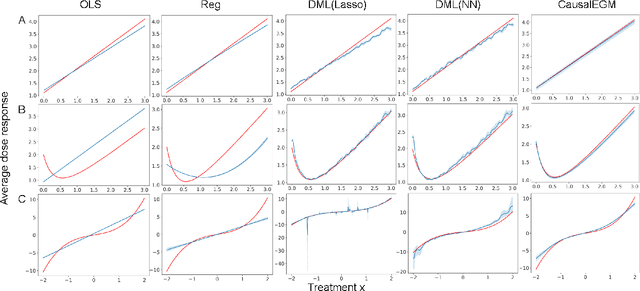
Causal inference in observational studies with high-dimensional covariates presents significant challenges. We introduce CausalBGM, an AI-powered Bayesian generative modeling approach that captures the causal relationship among covariates, treatment, and outcome variables. The core innovation of CausalBGM lies in its ability to estimate the individual treatment effect (ITE) by learning individual-specific distributions of a low-dimensional latent feature set (e.g., latent confounders) that drives changes in both treatment and outcome. This approach not only effectively mitigates confounding effects but also provides comprehensive uncertainty quantification, offering reliable and interpretable causal effect estimates at the individual level. CausalBGM adopts a Bayesian model and uses a novel iterative algorithm to update the model parameters and the posterior distribution of latent features until convergence. This framework leverages the power of AI to capture complex dependencies among variables while adhering to the Bayesian principles. Extensive experiments demonstrate that CausalBGM consistently outperforms state-of-the-art methods, particularly in scenarios with high-dimensional covariates and large-scale datasets. Its Bayesian foundation ensures statistical rigor, providing robust and well-calibrated posterior intervals. By addressing key limitations of existing methods, CausalBGM emerges as a robust and promising framework for advancing causal inference in modern applications in fields such as genomics, healthcare, and social sciences. CausalBGM is maintained at the website https://causalbgm.readthedocs.io/.
Generative Modeling for Tabular Data via Penalized Optimal Transport Network
Feb 16, 2024The task of precisely learning the probability distribution of rows within tabular data and producing authentic synthetic samples is both crucial and non-trivial. Wasserstein generative adversarial network (WGAN) marks a notable improvement in generative modeling, addressing the challenges faced by its predecessor, generative adversarial network. However, due to the mixed data types and multimodalities prevalent in tabular data, the delicate equilibrium between the generator and discriminator, as well as the inherent instability of Wasserstein distance in high dimensions, WGAN often fails to produce high-fidelity samples. To this end, we propose POTNet (Penalized Optimal Transport Network), a generative deep neural network based on a novel, robust, and interpretable marginally-penalized Wasserstein (MPW) loss. POTNet can effectively model tabular data containing both categorical and continuous features. Moreover, it offers the flexibility to condition on a subset of features. We provide theoretical justifications for the motivation behind the MPW loss. We also empirically demonstrate the effectiveness of our proposed method on four different benchmarks across a variety of real-world and simulated datasets. Our proposed model achieves orders of magnitude speedup during the sampling stage compared to state-of-the-art generative models for tabular data, thereby enabling efficient large-scale synthetic data generation.
CausalEGM: a general causal inference framework by encoding generative modeling
Dec 13, 2022


Although understanding and characterizing causal effects have become essential in observational studies, it is challenging when the confounders are high-dimensional. In this article, we develop a general framework $\textit{CausalEGM}$ for estimating causal effects by encoding generative modeling, which can be applied in both binary and continuous treatment settings. Under the potential outcome framework with unconfoundedness, we establish a bidirectional transformation between the high-dimensional confounders space and a low-dimensional latent space where the density is known (e.g., multivariate normal distribution). Through this, CausalEGM simultaneously decouples the dependencies of confounders on both treatment and outcome and maps the confounders to the low-dimensional latent space. By conditioning on the low-dimensional latent features, CausalEGM can estimate the causal effect for each individual or the average causal effect within a population. Our theoretical analysis shows that the excess risk for CausalEGM can be bounded through empirical process theory. Under an assumption on encoder-decoder networks, the consistency of the estimate can be guaranteed. In a series of experiments, CausalEGM demonstrates superior performance over existing methods for both binary and continuous treatments. Specifically, we find CausalEGM to be substantially more powerful than competing methods in the presence of large sample sizes and high dimensional confounders. The software of CausalEGM is freely available at https://github.com/SUwonglab/CausalEGM.
Roundtrip: A Deep Generative Neural Density Estimator
May 10, 2020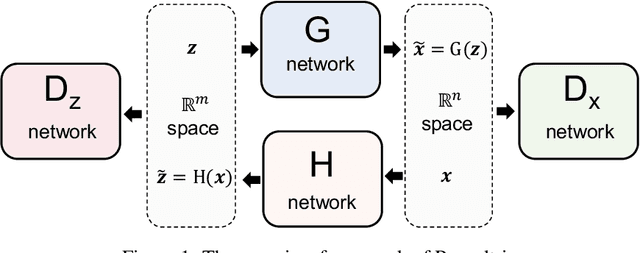

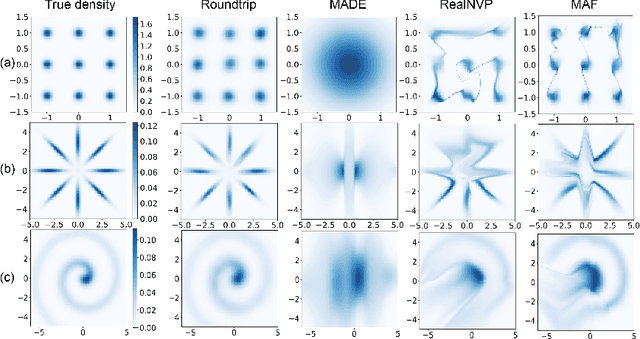
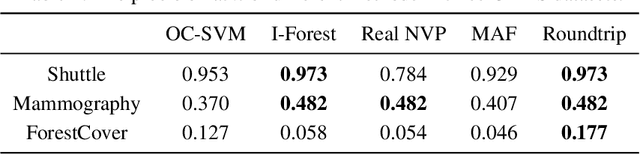
Density estimation is a fundamental problem in both statistics and machine learning. In this study, we proposed Roundtrip as a general-purpose neural density estimator based on deep generative models. Roundtrip retains the generative power of generative adversarial networks (GANs) but also provides estimates of density values. Unlike previous neural density estimators that put stringent conditions on the transformation from the latent space to the data space, Roundtrip enables the use of much more general mappings. In a series of experiments, Roundtrip achieves state-of-the-art performance in a diverse range of density estimation tasks.
Density Estimation via Discrepancy Based Adaptive Sequential Partition
Mar 11, 2018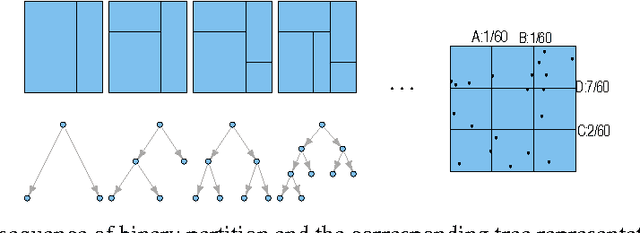


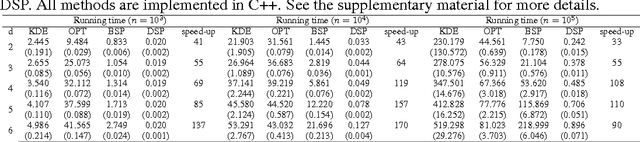
Given $iid$ observations from an unknown absolute continuous distribution defined on some domain $\Omega$, we propose a nonparametric method to learn a piecewise constant function to approximate the underlying probability density function. Our density estimate is a piecewise constant function defined on a binary partition of $\Omega$. The key ingredient of the algorithm is to use discrepancy, a concept originates from Quasi Monte Carlo analysis, to control the partition process. The resulting algorithm is simple, efficient, and has a provable convergence rate. We empirically demonstrate its efficiency as a density estimation method. We present its applications on a wide range of tasks, including finding good initializations for k-means.