 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual LLM-based ASR with Mixture of Experts and Dynamic Downsampling
Jun 09, 2026The rapid progress of large language models (LLMs) has opened up a new frontier for automatic speech recognition (ASR), making their effective integration a critical and challenging research direction. To this end, this work proposes a projector-based LLM-ASR framework targeting the key challenges of multilingual generalization and modality alignment. Our approach incorporates a Mixture of Experts (MoE) architecture to improve cross-lingual adaptability, and a Continuous Integrate-and-Fire (CIF) mechanism for dynamic downsampling and modality alignment. Experimental results show that the combination of these components yields substantial performance improvements, surpassing strong baseline models. The proposed method represents a step toward building more accurate, robust, and generalizable LLM-based ASR systems.
* Accepted by ICASSP 2026
MOSS-Audio Technical Report
Jun 01, 2026MOSS-Audio is a unified audio-language model for speech, environmental sound, and music understanding, supporting audio captioning, time-aware question answering, timestamped transcription, and audio-grounded reasoning. MOSS-Audio couples a dedicated audio encoder with a modality adapter and a large language model: the encoder produces 12.5 Hz temporal representations, the adapter projects them into the decoder space, and the decoder generates autoregressive text outputs. Two design choices are central to the system: \textbf{DeepStack cross-layer feature injection}, which exposes the decoder to acoustic information from multiple encoder depths, and \textbf{time markers}, which provide explicit temporal cues by inserting timestamp markers into the audio-token stream. At the data level, we design an event-preserving audio annotation pipeline that segments raw audio at coherent event boundaries, applies branch-specific annotation to speech, music, and general audio, and merges the results into unified captions for pretraining. The intermediate branch-specific captions are further retained to support the construction of task-oriented SFT data. The model is pretrained on large-scale audio-language data, with time-aware objectives incorporated to support temporal grounding, and then undergoes multi-stage post-training to enhance instruction following and audio-grounded reasoning. We release 4B and 8B variants in both Instruct and Thinking configurations. MOSS-Audio achieves strong performance across general audio understanding, speech captioning, ASR, and timestamped ASR, positioning it as a promising understanding foundation for future voice agents.
A Wireless World Model for AI-Native 6G Networks
Mar 26, 2026Integrating AI into the physical layer is a cornerstone of 6G networks. However, current data-driven approaches struggle to generalize across dynamic environments because they lack an intrinsic understanding of electromagnetic wave propagation. We introduce the Wireless World Model (WWM), a multi-modal foundation framework predicting the spatiotemporal evolution of wireless channels by internalizing the causal relationship between 3D geometry and signal dynamics. Pre-trained on a massive ray-traced multi-modal dataset, WWM overcomes the data authenticity gap, further validated under real-world measurement data. Using a joint-embedding predictive architecture with a multi-modal mixture-of-experts Transformer, WWM fuses channel state information, 3D point clouds, and user trajectories into a unified representation. Across the five key downstream tasks supported by WWM, it achieves remarkable performance in seen environments, unseen generalization scenarios, and real-world measurements, consistently outperforming SOTA uni-modal foundation models and task-specific models. This paves the way for physics-aware 6G intelligence that adapts to the physical world.
MOSS-TTS Technical Report
Mar 18, 2026This technical report presents MOSS-TTS, a speech generation foundation model built on a scalable recipe: discrete audio tokens, autoregressive modeling, and large-scale pretraining. Built on MOSS-Audio-Tokenizer, a causal Transformer tokenizer that compresses 24 kHz audio to 12.5 fps with variable-bitrate RVQ and unified semantic-acoustic representations, we release two complementary generators: MOSS-TTS, which emphasizes structural simplicity, scalability, and long-context/control-oriented deployment, and MOSS-TTS-Local-Transformer, which introduces a frame-local autoregressive module for higher modeling efficiency, stronger speaker preservation, and a shorter time to first audio. Across multilingual and open-domain settings, MOSS-TTS supports zero-shot voice cloning, token-level duration control, phoneme-/pinyin-level pronunciation control, smooth code-switching, and stable long-form generation. This report summarizes the design, training recipe, and empirical characteristics of the released models.
AgenticTagger: Structured Item Representation for Recommendation with LLM Agents
Feb 05, 2026High-quality representations are a core requirement for effective recommendation. In this work, we study the problem of LLM-based descriptor generation, i.e., keyphrase-like natural language item representation generation frameworks with minimal constraints on downstream applications. We propose AgenticTagger, a framework that queries LLMs for representing items with sequences of text descriptors. However, open-ended generation provides little control over the generation space, leading to high cardinality, low-performance descriptors that renders downstream modeling challenging. To this end, AgenticTagger features two core stages: (1) a vocabulary building stage where a set of hierarchical, low-cardinality, and high-quality descriptors is identified, and (2) a vocabulary assignment stage where LLMs assign in-vocabulary descriptors to items. To effectively and efficiently ground vocabulary in the item corpus of interest, we design a multi-agent reflection mechanism where an architect LLM iteratively refines the vocabulary guided by parallelized feedback from annotator LLMs that validates the vocabulary against item data. Experiments on public and private data show AgenticTagger brings consistent improvements across diverse recommendation scenarios, including generative and term-based retrieval, ranking, and controllability-oriented, critique-based recommendation.
PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
Jan 15, 2026Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.
Unleashing Diffusion and State Space Models for Medical Image Segmentation
Jun 15, 2025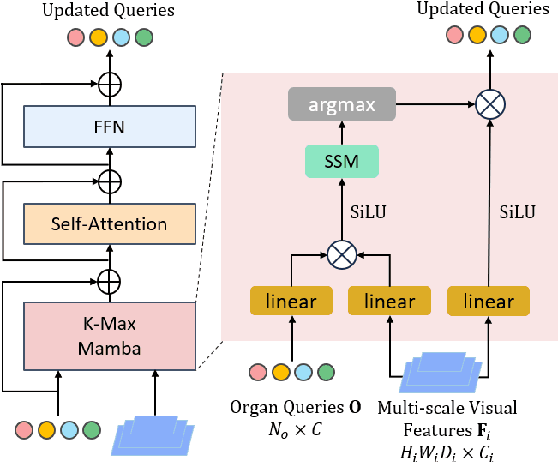
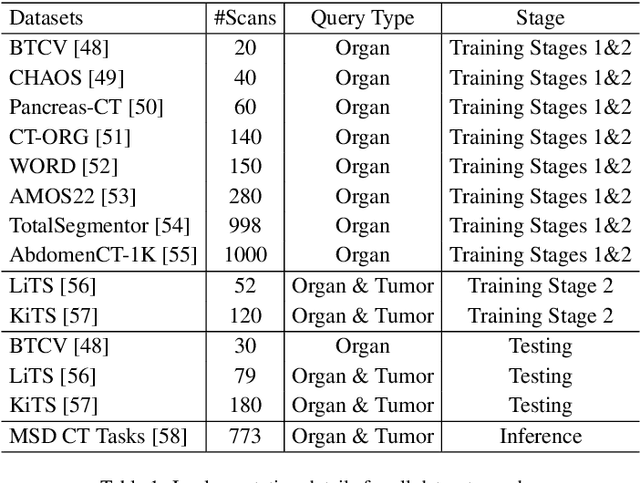
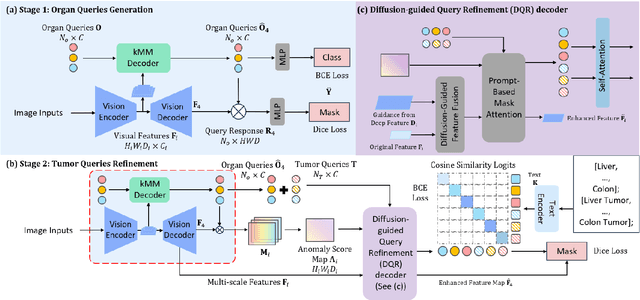
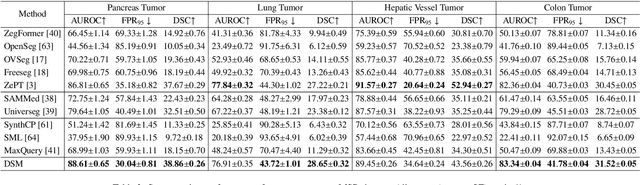
Existing segmentation models trained on a single medical imaging dataset often lack robustness when encountering unseen organs or tumors. Developing a robust model capable of identifying rare or novel tumor categories not present during training is crucial for advancing medical imaging applications. We propose DSM, a novel framework that leverages diffusion and state space models to segment unseen tumor categories beyond the training data. DSM utilizes two sets of object queries trained within modified attention decoders to enhance classification accuracy. Initially, the model learns organ queries using an object-aware feature grouping strategy to capture organ-level visual features. It then refines tumor queries by focusing on diffusion-based visual prompts, enabling precise segmentation of previously unseen tumors. Furthermore, we incorporate diffusion-guided feature fusion to improve semantic segmentation performance. By integrating CLIP text embeddings, DSM captures category-sensitive classes to improve linguistic transfer knowledge, thereby enhancing the model's robustness across diverse scenarios and multi-label tasks. Extensive experiments demonstrate the superior performance of DSM in various tumor segmentation tasks. Code is available at https://github.com/Rows21/KMax-Mamba.
DiffER: Categorical Diffusion for Chemical Retrosynthesis
May 29, 2025Methods for automatic chemical retrosynthesis have found recent success through the application of models traditionally built for natural language processing, primarily through transformer neural networks. These models have demonstrated significant ability to translate between the SMILES encodings of chemical products and reactants, but are constrained as a result of their autoregressive nature. We propose DiffER, an alternative template-free method for retrosynthesis prediction in the form of categorical diffusion, which allows the entire output SMILES sequence to be predicted in unison. We construct an ensemble of diffusion models which achieves state-of-the-art performance for top-1 accuracy and competitive performance for top-3, top-5, and top-10 accuracy among template-free methods. We prove that DiffER is a strong baseline for a new class of template-free model, capable of learning a variety of synthetic techniques used in laboratory settings and outperforming a variety of other template-free methods on top-k accuracy metrics. By constructing an ensemble of categorical diffusion models with a novel length prediction component with variance, our method is able to approximately sample from the posterior distribution of reactants, producing results with strong metrics of confidence and likelihood. Furthermore, our analyses demonstrate that accurate prediction of the SMILES sequence length is key to further boosting the performance of categorical diffusion models.
High-Dimensional Dynamic Covariance Models with Random Forests
May 18, 2025This paper introduces a novel nonparametric method for estimating high-dimensional dynamic covariance matrices with multiple conditioning covariates, leveraging random forests and supported by robust theoretical guarantees. Unlike traditional static methods, our dynamic nonparametric covariance models effectively capture distributional heterogeneity. Furthermore, unlike kernel-smoothing methods, which are restricted to a single conditioning covariate, our approach accommodates multiple covariates in a fully nonparametric framework. To the best of our knowledge, this is the first method to use random forests for estimating high-dimensional dynamic covariance matrices. In high-dimensional settings, we establish uniform consistency theory, providing nonasymptotic error rates and model selection properties, even when the response dimension grows sub-exponentially with the sample size. These results hold uniformly across a range of conditioning variables. The method's effectiveness is demonstrated through simulations and a stock dataset analysis, highlighting its ability to model complex dynamics in high-dimensional scenarios.
Uni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.