 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
3D Registration in 30 Years: A Survey
Dec 19, 2024



3D point cloud registration is a fundamental problem in computer vision, computer graphics, robotics, remote sensing, and etc. Over the last thirty years, we have witnessed the amazing advancement in this area with numerous kinds of solutions. Although a handful of relevant surveys have been conducted, their coverage is still limited. In this work, we present a comprehensive survey on 3D point cloud registration, covering a set of sub-areas such as pairwise coarse registration, pairwise fine registration, multi-view registration, cross-scale registration, and multi-instance registration. The datasets, evaluation metrics, method taxonomy, discussions of the merits and demerits, insightful thoughts of future directions are comprehensively presented in this survey. The regularly updated project page of the survey is available at https://github.com/Amyyyy11/3D-Registration-in-30-Years-A-Survey.
Unleash the Power of Local Representations for Few-Shot Classification
Jul 02, 2024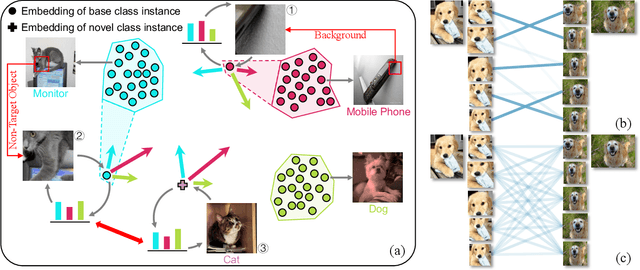
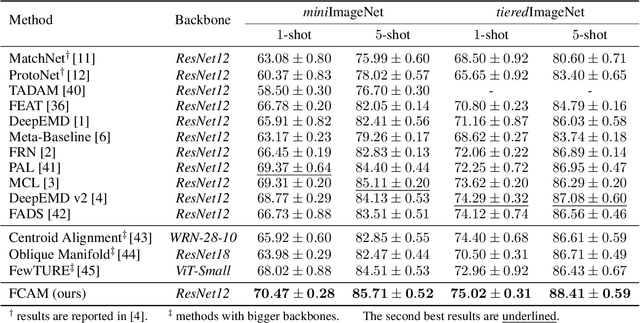
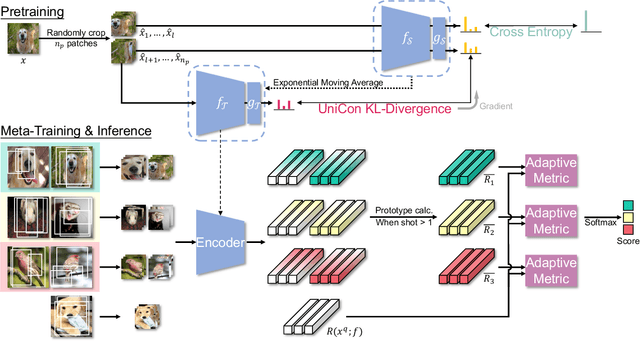
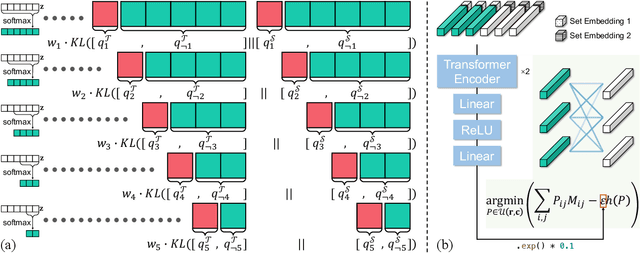
Generalizing to novel classes unseen during training is a key challenge of few-shot classification. Recent metric-based methods try to address this by local representations. However, they are unable to take full advantage of them due to (i) improper supervision for pretraining the feature extractor, and (ii) lack of adaptability in the metric for handling various possible compositions of local feature sets. In this work, we unleash the power of local representations in improving novel-class generalization. For the feature extractor, we design a novel pretraining paradigm that learns randomly cropped patches by soft labels. It utilizes the class-level diversity of patches while diminishing the impact of their semantic misalignments to hard labels. To align network output with soft labels, we also propose a UniCon KL-Divergence that emphasizes the equal contribution of each base class in describing "non-base" patches. For the metric, we formulate measuring local feature sets as an entropy-regularized optimal transport problem to introduce the ability to handle sets consisting of homogeneous elements. Furthermore, we design a Modulate Module to endow the metric with the necessary adaptability. Our method achieves new state-of-the-art performance on three popular benchmarks. Moreover, it exceeds state-of-the-art transductive and cross-modal methods in the fine-grained scenario.
Towards Fair and Comprehensive Comparisons for Image-Based 3D Object Detection
Oct 11, 2023



In this work, we build a modular-designed codebase, formulate strong training recipes, design an error diagnosis toolbox, and discuss current methods for image-based 3D object detection. In particular, different from other highly mature tasks, e.g., 2D object detection, the community of image-based 3D object detection is still evolving, where methods often adopt different training recipes and tricks resulting in unfair evaluations and comparisons. What is worse, these tricks may overwhelm their proposed designs in performance, even leading to wrong conclusions. To address this issue, we build a module-designed codebase and formulate unified training standards for the community. Furthermore, we also design an error diagnosis toolbox to measure the detailed characterization of detection models. Using these tools, we analyze current methods in-depth under varying settings and provide discussions for some open questions, e.g., discrepancies in conclusions on KITTI-3D and nuScenes datasets, which have led to different dominant methods for these datasets. We hope that this work will facilitate future research in image-based 3D object detection. Our codes will be released at \url{https://github.com/OpenGVLab/3dodi}
Rethinking Pseudo-LiDAR Representation
Aug 11, 2020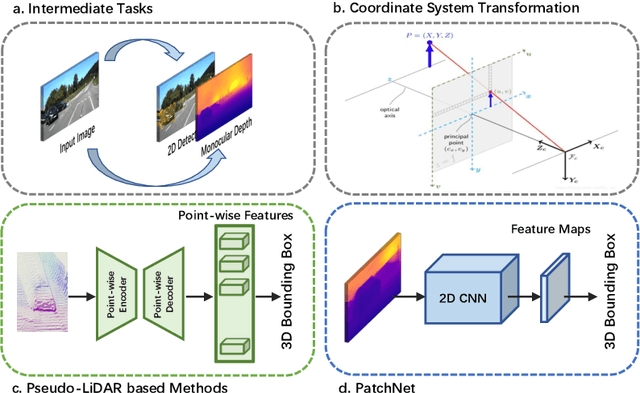
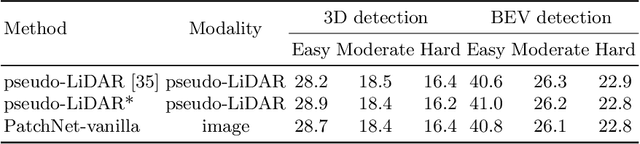
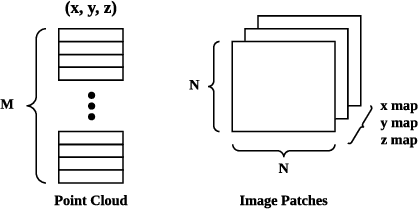
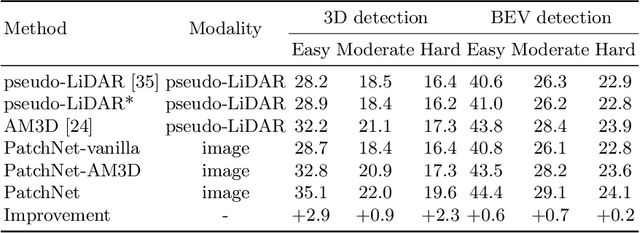
The recently proposed pseudo-LiDAR based 3D detectors greatly improve the benchmark of monocular/stereo 3D detection task. However, the underlying mechanism remains obscure to the research community. In this paper, we perform an in-depth investigation and observe that the efficacy of pseudo-LiDAR representation comes from the coordinate transformation, instead of data representation itself. Based on this observation, we design an image based CNN detector named Patch-Net, which is more generalized and can be instantiated as pseudo-LiDAR based 3D detectors. Moreover, the pseudo-LiDAR data in our PatchNet is organized as the image representation, which means existing 2D CNN designs can be easily utilized for extracting deep features from input data and boosting 3D detection performance. We conduct extensive experiments on the challenging KITTI dataset, where the proposed PatchNet outperforms all existing pseudo-LiDAR based counterparts. Code has been made available at: https://github.com/xinzhuma/patchnet.