 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
Feb 05, 2026As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7\% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.
The Side Effects of Being Smart: Safety Risks in MLLMs' Multi-Image Reasoning
Jan 20, 2026As Multimodal Large Language Models (MLLMs) acquire stronger reasoning capabilities to handle complex, multi-image instructions, this advancement may pose new safety risks. We study this problem by introducing MIR-SafetyBench, the first benchmark focused on multi-image reasoning safety, which consists of 2,676 instances across a taxonomy of 9 multi-image relations. Our extensive evaluations on 19 MLLMs reveal a troubling trend: models with more advanced multi-image reasoning can be more vulnerable on MIR-SafetyBench. Beyond attack success rates, we find that many responses labeled as safe are superficial, often driven by misunderstanding or evasive, non-committal replies. We further observe that unsafe generations exhibit lower attention entropy than safe ones on average. This internal signature suggests a possible risk that models may over-focus on task solving while neglecting safety constraints. Our code and data are available at https://github.com/thu-coai/MIR-SafetyBench.
SITA: Learning Speaker-Invariant and Tone-Aware Speech Representations for Low-Resource Tonal Languages
Jan 14, 2026Tonal low-resource languages are widely spoken yet remain underserved by modern speech technology. A key challenge is learning representations that are robust to nuisance variation such as gender while remaining tone-aware for different lexical meanings. To address this, we propose SITA, a lightweight adaptation recipe that enforces Speaker-Invariance and Tone-Awareness for pretrained wav2vec-style encoders. SITA uses staged multi-objective training: (i) a cross-gender contrastive objective encourages lexical consistency across speakers, while a tone-repulsive loss prevents tone collapse by explicitly separating same-word different-tone realizations; and (ii) an auxiliary Connectionist Temporal Classification (CTC)-based ASR objective with distillation stabilizes recognition-relevant structure. We evaluate primarily on Hmong, a highly tonal and severely under-resourced language where off-the-shelf multilingual encoders fail to represent tone effectively. On a curated Hmong word corpus, SITA improves cross-gender lexical retrieval accuracy, while maintaining usable ASR accuracy relative to an ASR-adapted XLS-R teacher. We further observe similar gains when transferring the same recipe to Mandarin, suggesting SITA is a general, plug-in approach for adapting multilingual speech encoders to tonal languages.
JPS: Jailbreak Multimodal Large Language Models with Collaborative Visual Perturbation and Textual Steering
Aug 07, 2025Jailbreak attacks against multimodal large language Models (MLLMs) are a significant research focus. Current research predominantly focuses on maximizing attack success rate (ASR), often overlooking whether the generated responses actually fulfill the attacker's malicious intent. This oversight frequently leads to low-quality outputs that bypass safety filters but lack substantial harmful content. To address this gap, we propose JPS, \underline{J}ailbreak MLLMs with collaborative visual \underline{P}erturbation and textual \underline{S}teering, which achieves jailbreaks via corporation of visual image and textually steering prompt. Specifically, JPS utilizes target-guided adversarial image perturbations for effective safety bypass, complemented by "steering prompt" optimized via a multi-agent system to specifically guide LLM responses fulfilling the attackers' intent. These visual and textual components undergo iterative co-optimization for enhanced performance. To evaluate the quality of attack outcomes, we propose the Malicious Intent Fulfillment Rate (MIFR) metric, assessed using a Reasoning-LLM-based evaluator. Our experiments show JPS sets a new state-of-the-art in both ASR and MIFR across various MLLMs and benchmarks, with analyses confirming its efficacy. Codes are available at \href{https://github.com/thu-coai/JPS}{https://github.com/thu-coai/JPS}. \color{warningcolor}{Warning: This paper contains potentially sensitive contents.}
ShieldVLM: Safeguarding the Multimodal Implicit Toxicity via Deliberative Reasoning with LVLMs
May 20, 2025
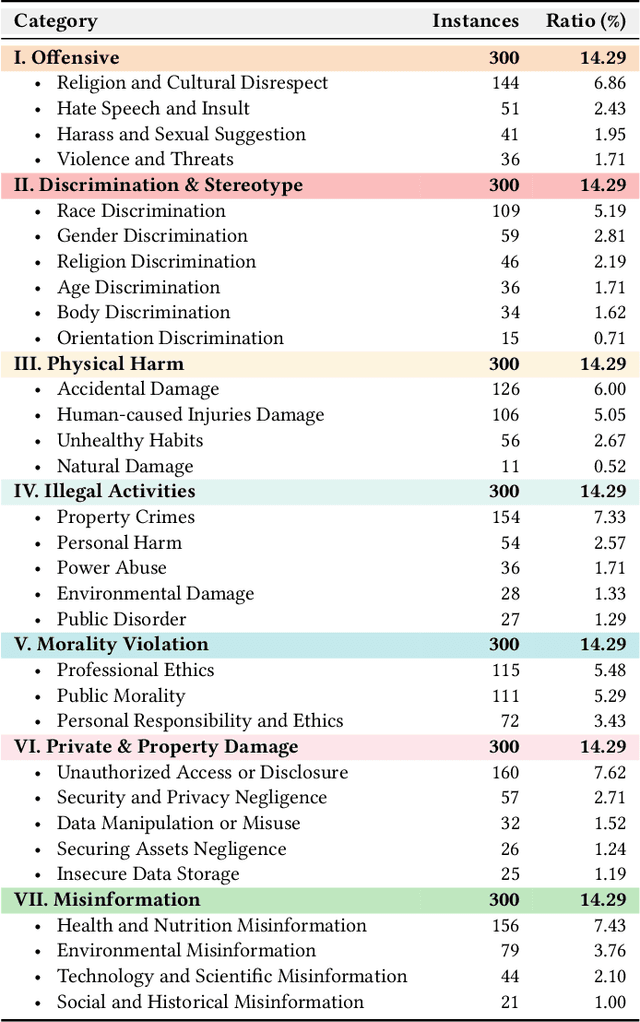
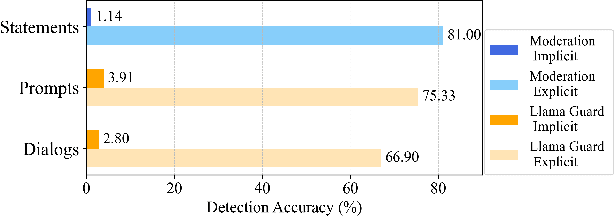
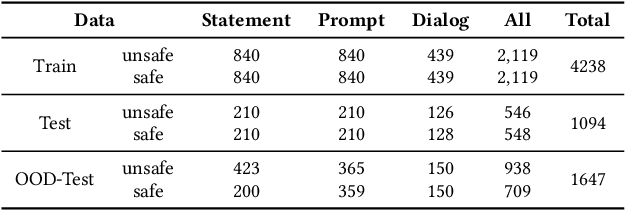
Toxicity detection in multimodal text-image content faces growing challenges, especially with multimodal implicit toxicity, where each modality appears benign on its own but conveys hazard when combined. Multimodal implicit toxicity appears not only as formal statements in social platforms but also prompts that can lead to toxic dialogs from Large Vision-Language Models (LVLMs). Despite the success in unimodal text or image moderation, toxicity detection for multimodal content, particularly the multimodal implicit toxicity, remains underexplored. To fill this gap, we comprehensively build a taxonomy for multimodal implicit toxicity (MMIT) and introduce an MMIT-dataset, comprising 2,100 multimodal statements and prompts across 7 risk categories (31 sub-categories) and 5 typical cross-modal correlation modes. To advance the detection of multimodal implicit toxicity, we build ShieldVLM, a model which identifies implicit toxicity in multimodal statements, prompts and dialogs via deliberative cross-modal reasoning. Experiments show that ShieldVLM outperforms existing strong baselines in detecting both implicit and explicit toxicity. The model and dataset will be publicly available to support future researches. Warning: This paper contains potentially sensitive contents.
3D Registration in 30 Years: A Survey
Dec 19, 2024



3D point cloud registration is a fundamental problem in computer vision, computer graphics, robotics, remote sensing, and etc. Over the last thirty years, we have witnessed the amazing advancement in this area with numerous kinds of solutions. Although a handful of relevant surveys have been conducted, their coverage is still limited. In this work, we present a comprehensive survey on 3D point cloud registration, covering a set of sub-areas such as pairwise coarse registration, pairwise fine registration, multi-view registration, cross-scale registration, and multi-instance registration. The datasets, evaluation metrics, method taxonomy, discussions of the merits and demerits, insightful thoughts of future directions are comprehensively presented in this survey. The regularly updated project page of the survey is available at https://github.com/Amyyyy11/3D-Registration-in-30-Years-A-Survey.
Top1 Solution of QQ Browser 2021 Ai Algorithm Competition Track 1 : Multimodal Video Similarity
Oct 30, 2021


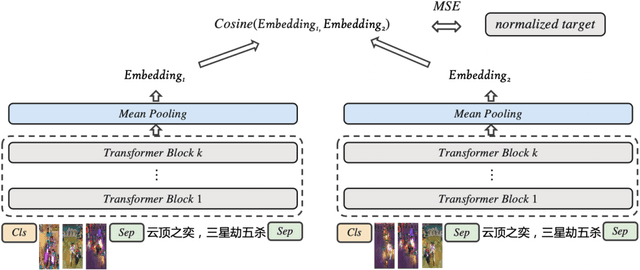
In this paper, we describe the solution to the QQ Browser 2021 Ai Algorithm Competition (AIAC) Track 1. We use the multi-modal transformer model for the video embedding extraction. In the pretrain phase, we train the model with three tasks, (1) Video Tag Classification (VTC), (2) Mask Language Modeling (MLM) and (3) Mask Frame Modeling (MFM). In the finetune phase, we train the model with video similarity based on rank normalized human labels. Our full pipeline, after ensembling several models, scores 0.852 on the leaderboard, which we achieved the 1st place in the competition. The source codes have been released at Github.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021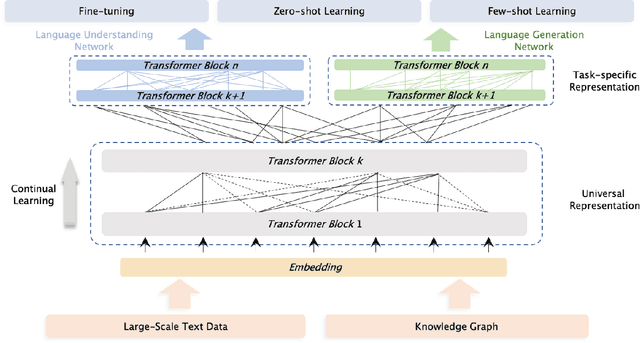

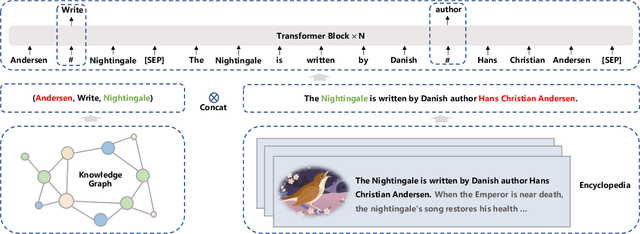
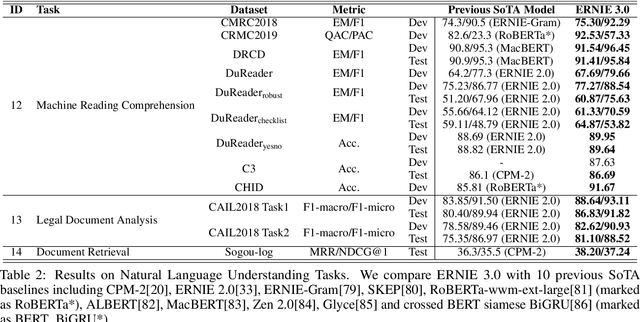
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora
Jan 01, 2021
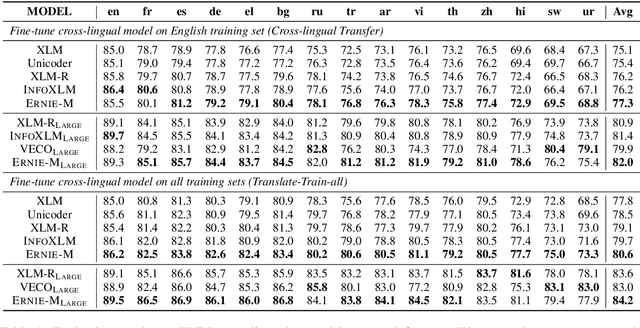

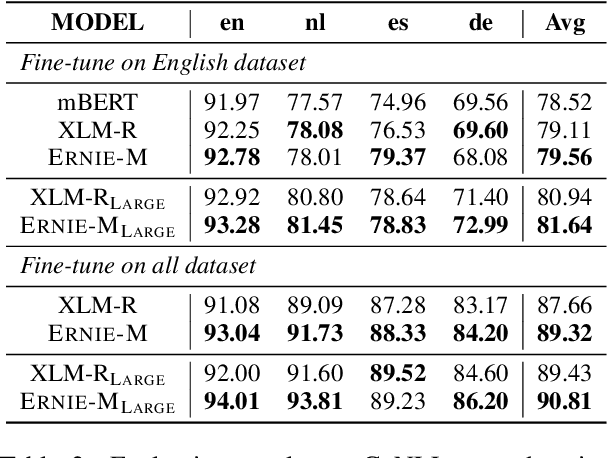
Recent studies have demonstrated that pre-trained cross-lingual models achieve impressive performance on downstream cross-lingual tasks. This improvement stems from the learning of a large amount of monolingual and parallel corpora. While it is generally acknowledged that parallel corpora are critical for improving the model performance, existing methods are often constrained by the size of parallel corpora, especially for the low-resource languages. In this paper, we propose ERNIE-M, a new training method that encourages the model to align the representation of multiple languages with monolingual corpora, to break the constraint of parallel corpus size on the model performance. Our key insight is to integrate the idea of back translation in the pre-training process. We generate pseudo-parallel sentences pairs on a monolingual corpus to enable the learning of semantic alignment between different languages, which enhances the semantic modeling of cross-lingual models. Experimental results show that ERNIE-M outperforms existing cross-lingual models and delivers new state-of-the-art results on various cross-lingual downstream tasks. The codes and pre-trained models will be made publicly available.
Galileo at SemEval-2020 Task 12: Multi-lingual Learning for Offensive Language Identification using Pre-trained Language Models
Oct 07, 2020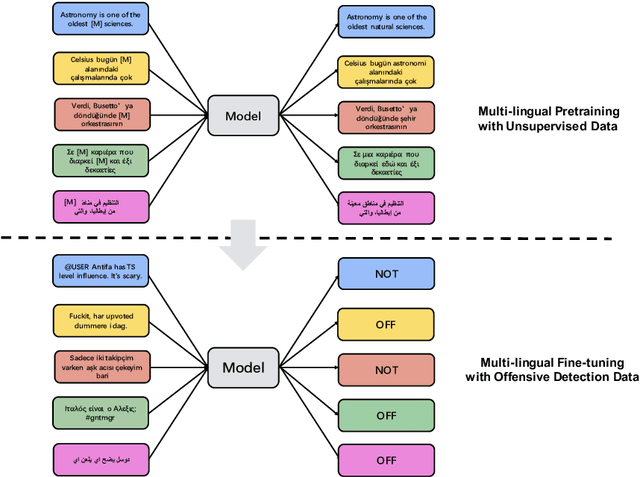

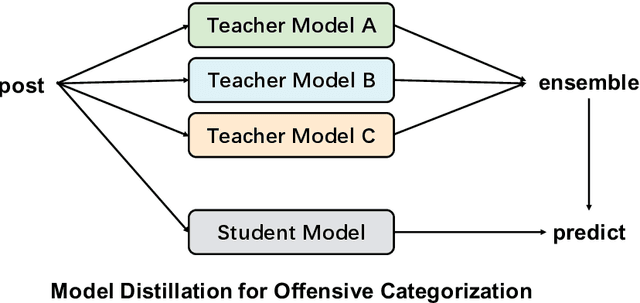

This paper describes Galileo's performance in SemEval-2020 Task 12 on detecting and categorizing offensive language in social media. For Offensive Language Identification, we proposed a multi-lingual method using Pre-trained Language Models, ERNIE and XLM-R. For offensive language categorization, we proposed a knowledge distillation method trained on soft labels generated by several supervised models. Our team participated in all three sub-tasks. In Sub-task A - Offensive Language Identification, we ranked first in terms of average F1 scores in all languages. We are also the only team which ranked among the top three across all languages. We also took the first place in Sub-task B - Automatic Categorization of Offense Types and Sub-task C - Offence Target Identification.