 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
SpikingBrain Technical Report: Spiking Brain-inspired Large Models
Sep 05, 2025Mainstream Transformer-based large language models face major efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly, limiting long-context processing. Building large models on non-NVIDIA platforms also poses challenges for stable and efficient training. To address this, we introduce SpikingBrain, a family of brain-inspired models designed for efficient long-context training and inference. SpikingBrain leverages the MetaX GPU cluster and focuses on three aspects: (1) Model Architecture: linear and hybrid-linear attention architectures with adaptive spiking neurons; (2) Algorithmic Optimizations: an efficient, conversion-based training pipeline and a dedicated spike coding framework; (3) System Engineering: customized training frameworks, operator libraries, and parallelism strategies tailored to MetaX hardware. Using these techniques, we develop two models: SpikingBrain-7B, a linear LLM, and SpikingBrain-76B, a hybrid-linear MoE LLM. These models demonstrate the feasibility of large-scale LLM development on non-NVIDIA platforms. SpikingBrain achieves performance comparable to open-source Transformer baselines while using only about 150B tokens for continual pre-training. Our models significantly improve long-sequence training efficiency and deliver inference with (partially) constant memory and event-driven spiking behavior. For example, SpikingBrain-7B attains over 100x speedup in Time to First Token for 4M-token sequences. Training remains stable for weeks on hundreds of MetaX C550 GPUs, with the 7B model reaching a Model FLOPs Utilization of 23.4 percent. The proposed spiking scheme achieves 69.15 percent sparsity, enabling low-power operation. Overall, this work demonstrates the potential of brain-inspired mechanisms to drive the next generation of efficient and scalable large model design.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022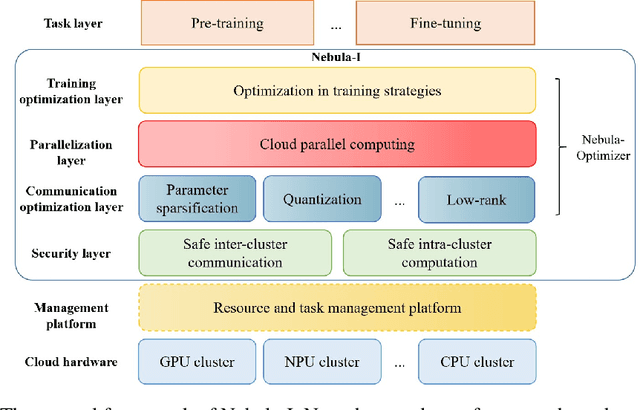
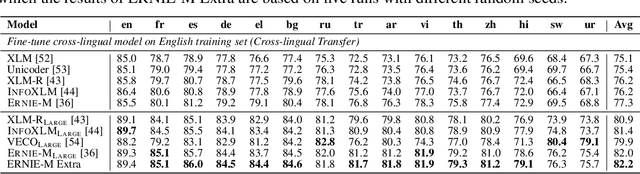
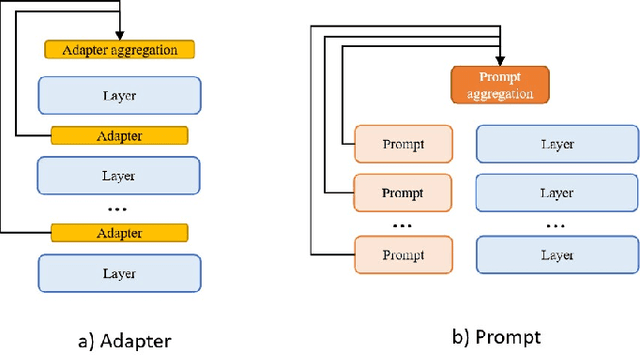
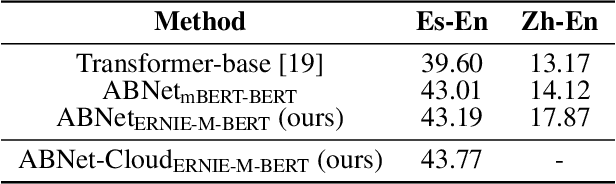
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021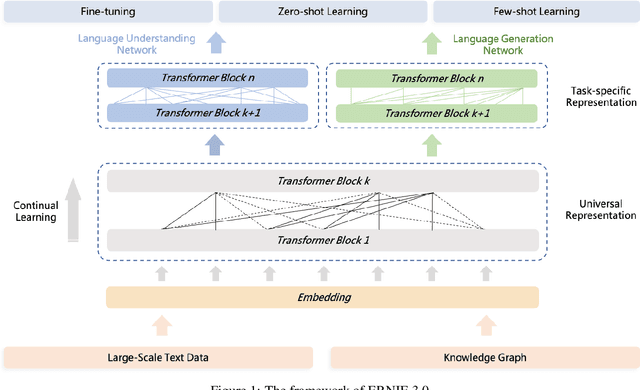
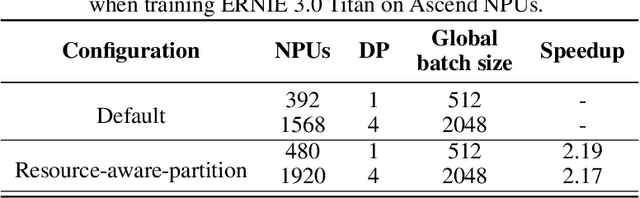
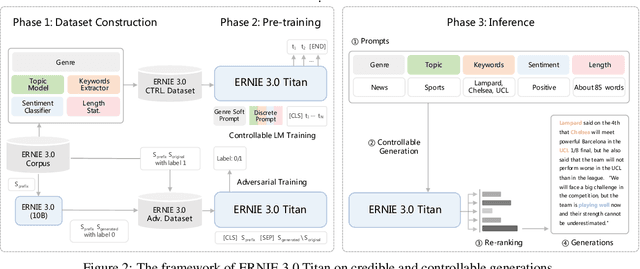
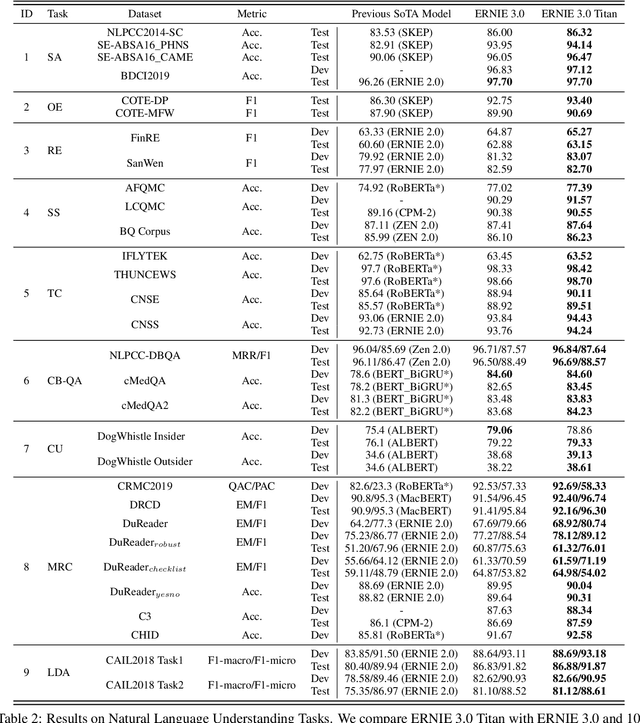
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021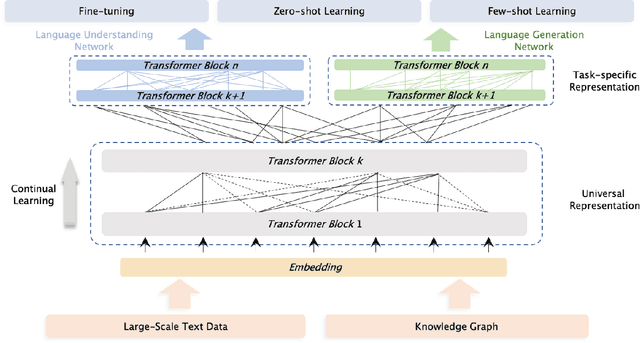

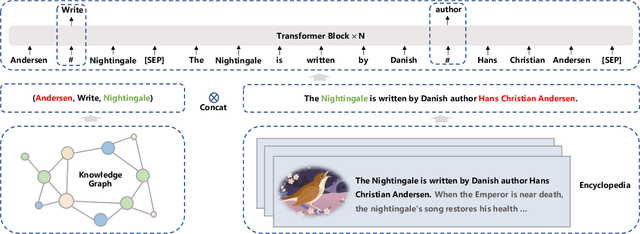
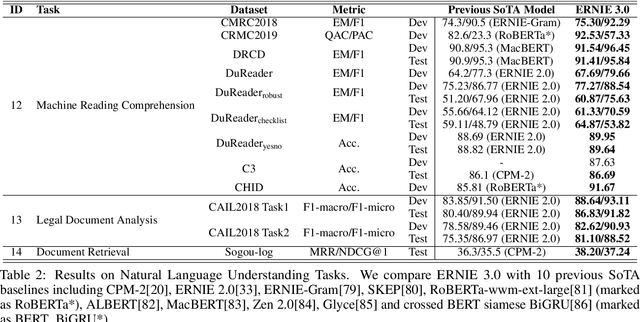
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
ERNIE-DOC: The Retrospective Long-Document Modeling Transformer
Dec 31, 2020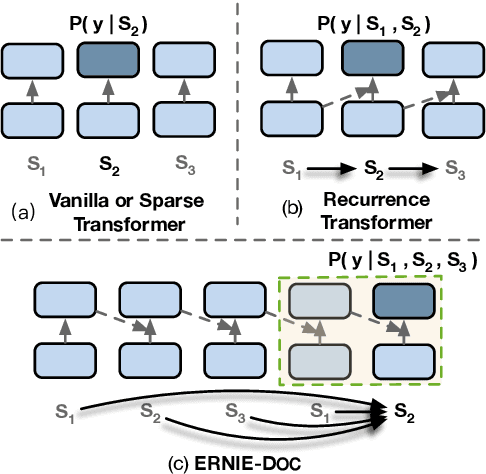
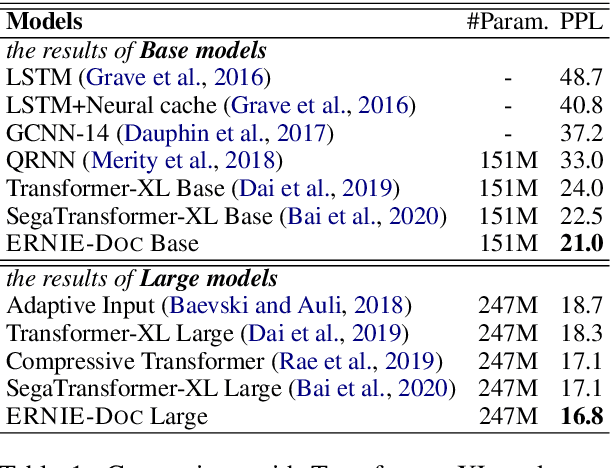
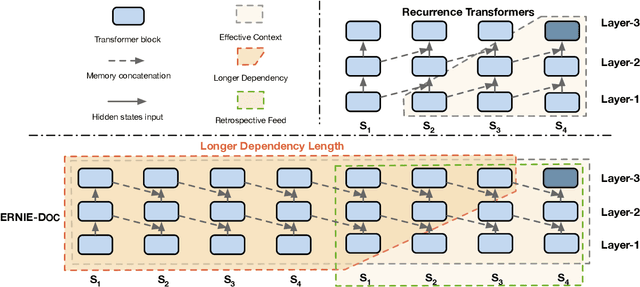
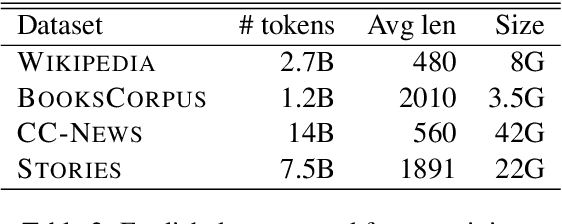
Transformers are not suited for processing long document input due to its quadratically increasing memory and time consumption. Simply truncating a long document or applying the sparse attention mechanism will incur the context fragmentation problem or inferior modeling capability with comparable model size. In this paper, we propose ERNIE-DOC, a document-level language pretraining model based on Recurrence Transformers. Two well-designed techniques, namely the retrospective feed mechanism and the enhanced recurrence mechanism enable ERNIE-DOC with much longer effective context length to capture the contextual information of a whole document. We pretrain ERNIE-DOC to explicitly learn the relationship among segments with an additional document-aware segment reordering objective. Various experiments on both English and Chinese document-level tasks are conducted. ERNIE-DOC achieves SOTA language modeling result of 16.8 ppl on WikiText-103 and outperforms competitive pretraining models on most language understanding tasks such as text classification, question answering by a large margin.