 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Audio-Visual Alignment for Generation
May 28, 2026Joint audio-video generation aims to synthesize temporally synchronized and semantically coherent visual-acoustic content. However, existing open-source methods mainly rely on either dual-tower designs with posterior alignment or fully unified tri-modal designs that mix textual context, audio and video in one shared space. The former weakens fine-grained audio-video co-evolution, while the latter couples semantic conditioning with low-level synchronization. To address these limitations, we propose NAVA, a Native Audio-Visual Alignment framework for joint audio-video generation. NAVA is built upon context-conditioned native audio-visual alignment: it first establishes audio-video correspondence in a dedicated interaction space, and then uses external context to condition the joint denoising process. Specifically, NAVA is instantiated with an Align-then-Fuse MMDiT architecture, which transitions from modality-aware audio-video alignment to modality-shared joint denoising. Furthermore, we introduce Timbre-in-Context Conditioning to associate reference timbre cues with corresponding speech spans to achieve controllable speech timbre. Experiments on Verse-Bench and Seed-TTS, together with a user study, demonstrate that NAVA achieves superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability using only 6.3B parameters.
CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
Apr 06, 2026Image degradation from blur, noise, compression, and poor illumination severely undermines multimodal understanding in real-world settings. Unified multimodal models that combine understanding and generation within a single architecture are a natural fit for this challenge, as their generative pathway can model the fine-grained visual structure that degradation destroys. Yet these models fail to leverage their own generative capacity on degraded inputs. We trace this disconnect to two compounding factors: existing training regimes never ask the model to invoke generation during reasoning, and the standard decode-reencode pathway does not support effective joint optimization. We present CLEAR, a framework that connects the two capabilities through three progressive steps: (1) supervised fine-tuning on a degradation-aware dataset to establish the generate-then-answer reasoning pattern; (2) a Latent Representation Bridge that replaces the decode-reencode detour with a direct, optimizable connection between generation and reasoning; (3) Interleaved GRPO, a reinforcement learning method that jointly optimizes text reasoning and visual generation under answer-correctness rewards. We construct MMD-Bench, covering three degradation severity levels across six standard multimodal benchmarks. Experiments show that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance. Our analysis further reveals that removing pixel-level reconstruction supervision leads to intermediate visual states with higher perceptual quality, suggesting that task-driven optimization and visual quality are naturally aligned.
Sparse Growing Transformer: Training-Time Sparse Depth Allocation via Progressive Attention Looping
Mar 25, 2026Existing approaches to increasing the effective depth of Transformers predominantly rely on parameter reuse, extending computation through recursive execution. Under this paradigm, the network structure remains static along the training timeline, and additional computational depth is uniformly assigned to entire blocks at the parameter level. This rigidity across training time and parameter space leads to substantial computational redundancy during training. In contrast, we argue that depth allocation during training should not be a static preset, but rather a progressively growing structural process. Our systematic analysis reveals a deep-to-shallow maturation trajectory across layers, where high-entropy attention heads play a crucial role in semantic integration. Motivated by this observation, we introduce the Sparse Growing Transformer (SGT). SGT is a training-time sparse depth allocation framework that progressively extends recurrence from deeper to shallower layers via targeted attention looping on informative heads. This mechanism induces structural sparsity by selectively increasing depth only for a small subset of parameters as training evolves. Extensive experiments across multiple parameter scales demonstrate that SGT consistently outperforms training-time static block-level looping baselines under comparable settings, while reducing the additional training FLOPs overhead from approximately 16--20% to only 1--3% relative to a standard Transformer backbone.
Mixture of Universal Experts: Scaling Virtual Width via Depth-Width Transformation
Mar 05, 2026Mixture-of-Experts (MoE) decouples model capacity from per-token computation, yet their scalability remains limited by the physical dimensions of depth and width. To overcome this, we propose Mixture of Universal Experts (MOUE),a MoE generalization introducing a novel scaling dimension: Virtual Width. In general, MoUE aims to reuse a universal layer-agnostic expert pool across layers, converting depth into virtual width under a fixed per-token activation budget. However, two challenges remain: a routing path explosion from recursive expert reuse, and a mismatch between the exposure induced by reuse and the conventional load-balancing objectives. We address these with three core components: a Staggered Rotational Topology for structured expert sharing, a Universal Expert Load Balance for depth-aware exposure correction, and a Universal Router with lightweight trajectory state for coherent multi-step routing. Empirically, MoUE consistently outperforms matched MoE baselines by up to 1.3% across scaling regimes, enables progressive conversion of existing MoE checkpoints with up to 4.2% gains, and reveals a new scaling dimension for MoE architectures.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
VideoAR: Autoregressive Video Generation via Next-Frame & Scale Prediction
Jan 09, 2026Recent advances in video generation have been dominated by diffusion and flow-matching models, which produce high-quality results but remain computationally intensive and difficult to scale. In this work, we introduce VideoAR, the first large-scale Visual Autoregressive (VAR) framework for video generation that combines multi-scale next-frame prediction with autoregressive modeling. VideoAR disentangles spatial and temporal dependencies by integrating intra-frame VAR modeling with causal next-frame prediction, supported by a 3D multi-scale tokenizer that efficiently encodes spatio-temporal dynamics. To improve long-term consistency, we propose Multi-scale Temporal RoPE, Cross-Frame Error Correction, and Random Frame Mask, which collectively mitigate error propagation and stabilize temporal coherence. Our multi-stage pretraining pipeline progressively aligns spatial and temporal learning across increasing resolutions and durations. Empirically, VideoAR achieves new state-of-the-art results among autoregressive models, improving FVD on UCF-101 from 99.5 to 88.6 while reducing inference steps by over 10x, and reaching a VBench score of 81.74-competitive with diffusion-based models an order of magnitude larger. These results demonstrate that VideoAR narrows the performance gap between autoregressive and diffusion paradigms, offering a scalable, efficient, and temporally consistent foundation for future video generation research.
Blink: Dynamic Visual Token Resolution for Enhanced Multimodal Understanding
Dec 11, 2025Multimodal large language models (MLLMs) have achieved remarkable progress on various vision-language tasks, yet their visual perception remains limited. Humans, in comparison, perceive complex scenes efficiently by dynamically scanning and focusing on salient regions in a sequential "blink-like" process. Motivated by this strategy, we first investigate whether MLLMs exhibit similar behavior. Our pilot analysis reveals that MLLMs naturally attend to different visual regions across layers and that selectively allocating more computation to salient tokens can enhance visual perception. Building on this insight, we propose Blink, a dynamic visual token resolution framework that emulates the human-inspired process within a single forward pass. Specifically, Blink includes two modules: saliency-guided scanning and dynamic token resolution. It first estimates the saliency of visual tokens in each layer based on the attention map, and extends important tokens through a plug-and-play token super-resolution (TokenSR) module. In the next layer, it drops the extended tokens when they lose focus. This dynamic mechanism balances broad exploration and fine-grained focus, thereby enhancing visual perception adaptively and efficiently. Extensive experiments validate Blink, demonstrating its effectiveness in enhancing visual perception and multimodal understanding.
Advantageous Parameter Expansion Training Makes Better Large Language Models
May 30, 2025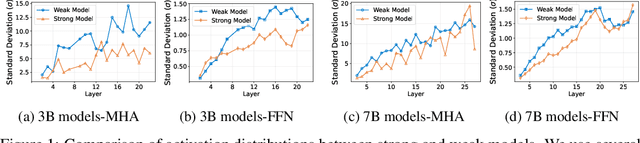
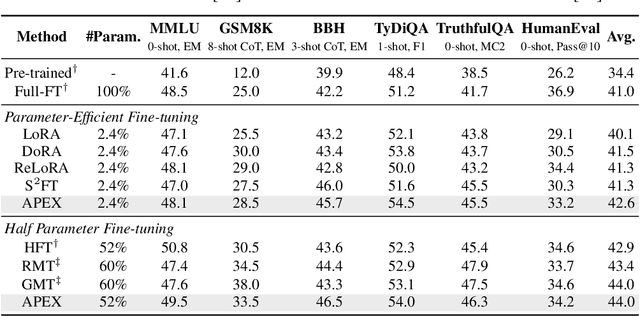
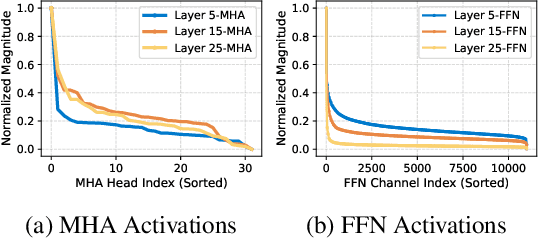
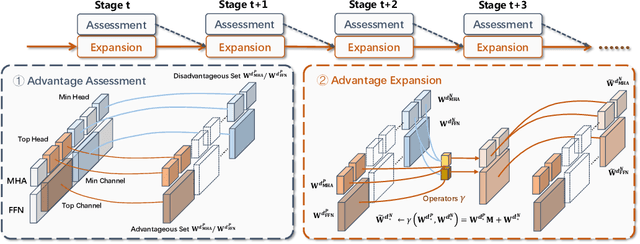
Although scaling up the number of trainable parameters in both pre-training and fine-tuning can effectively improve the performance of large language models, it also leads to increased computational overhead. When delving into the parameter difference, we find that a subset of parameters, termed advantageous parameters, plays a crucial role in determining model performance. Further analysis reveals that stronger models tend to possess more such parameters. In this paper, we propose Advantageous Parameter EXpansion Training (APEX), a method that progressively expands advantageous parameters into the space of disadvantageous ones, thereby increasing their proportion and enhancing training effectiveness. Further theoretical analysis from the perspective of matrix effective rank explains the performance gains of APEX. Extensive experiments on both instruction tuning and continued pre-training demonstrate that, in instruction tuning, APEX outperforms full-parameter tuning while using only 52% of the trainable parameters. In continued pre-training, APEX achieves the same perplexity level as conventional training with just 33% of the training data, and yields significant improvements on downstream tasks.
BeamLoRA: Beam-Constraint Low-Rank Adaptation
Feb 19, 2025Due to the demand for efficient fine-tuning of large language models, Low-Rank Adaptation (LoRA) has been widely adopted as one of the most effective parameter-efficient fine-tuning methods. Nevertheless, while LoRA improves efficiency, there remains room for improvement in accuracy. Herein, we adopt a novel perspective to assess the characteristics of LoRA ranks. The results reveal that different ranks within the LoRA modules not only exhibit varying levels of importance but also evolve dynamically throughout the fine-tuning process, which may limit the performance of LoRA. Based on these findings, we propose BeamLoRA, which conceptualizes each LoRA module as a beam where each rank naturally corresponds to a potential sub-solution, and the fine-tuning process becomes a search for the optimal sub-solution combination. BeamLoRA dynamically eliminates underperforming sub-solutions while expanding the parameter space for promising ones, enhancing performance with a fixed rank. Extensive experiments across three base models and 12 datasets spanning math reasoning, code generation, and commonsense reasoning demonstrate that BeamLoRA consistently enhances the performance of LoRA, surpassing the other baseline methods.
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
Feb 19, 2025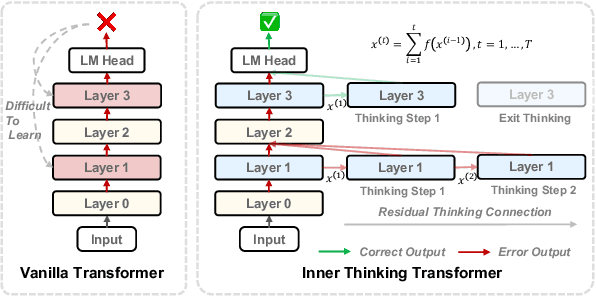
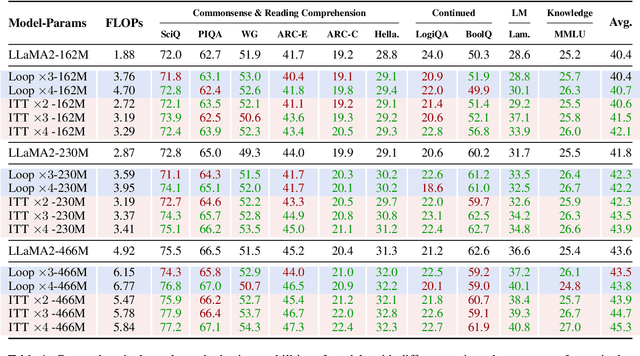
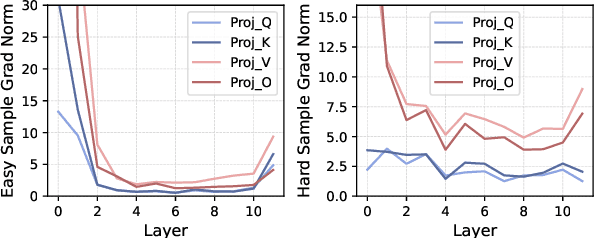
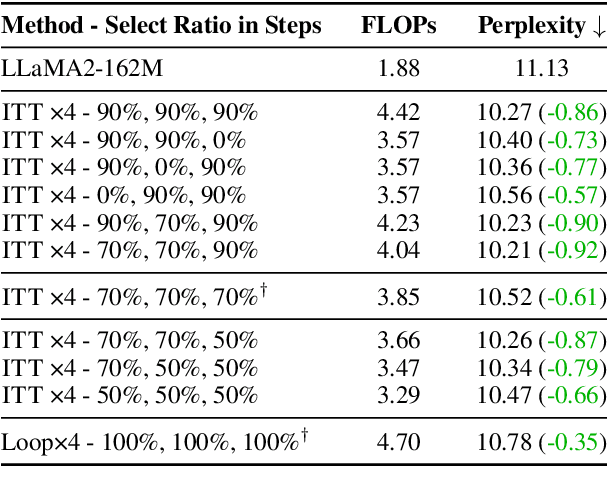
Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals challenging tokens induce abrupt gradient spikes across layers, exposing architectural stress points in standard Transformers. Building on this insight, we propose Inner Thinking Transformer (ITT), which reimagines layer computations as implicit thinking steps. ITT dynamically allocates computation through Adaptive Token Routing, iteratively refines representations via Residual Thinking Connections, and distinguishes reasoning phases using Thinking Step Encoding. ITT enables deeper processing of critical tokens without parameter expansion. Evaluations across 162M-466M parameter models show ITT achieves 96.5\% performance of a 466M Transformer using only 162M parameters, reduces training data by 43.2\%, and outperforms Transformer/Loop variants in 11 benchmarks. By enabling elastic computation allocation during inference, ITT balances performance and efficiency through architecture-aware optimization of implicit thinking pathways.