 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve, Forgetting to Retain: Correct-Set Turnover in RLVR
Jun 02, 2026Reinforcement learning with verifiable rewards (RLVR) improves the ability of large language model, yet headline accuracy gains often conceal a hidden cost: previously solved problems quietly become unsolvable as training proceeds. We frame this phenomenon as \emph{correct-set turnover}, representing the coupled dynamics of solution acquisition and regression over the mastered set. Under this view, retention becomes an explicit optimization target alongside acquisition. We analytically and empirically establish the \emph{repair-window principle}: the cost of restoring a regressed prompt grows sharply with review delay, defining a low-cost window that standard RLVR pipelines fail to exploit. To address this, we propose \textbf{\method{}}, a retention-aware review mechanism that tracks mastered prompts and periodically reintroduces them to \textbf{remind} the model of previous solutions. By utilizing pre-rollout batch replacement, \method{} incurs zero additional rollout overhead. Evaluated across 20 benchmarks spanning image-text, video, and text-only tasks with Qwen3-VL and Qwen2.5-Math, \method{} consistently improves performance over GRPO, DAPO, and replay baselines, demonstrating robust generalizability across modalities and algorithms.
What to Format and How: A Benchmark and Workflow Approach for Document Formatting
Jun 01, 2026Recent advances in large language models (LLMs) have opened up new possibilities for automated document formatting. However, real-world formatting often requires identifying targets based on document content. This content-aware setting remains challenging and underexplored, primarily due to the lack of dedicated evaluation datasets.To enable evaluation in realistic content-aware scenarios, we introduce DocFormBench, a benchmark that extends Text-to-Format evaluation to diverse formatting requirements, along with metrics for both accuracy and efficiency.To mitigate redundant document reading in existing methods during formatting, we propose DocFormFlow, a workflow formatting method that decouples target localization from modification execution into what to format and how. Extensive experiments across multiple LLMs and multimodal models show that DocFormFlow consistently improves formatting accuracy while reducing token consumption compared to representative baselines. Further analysis reveals that precise target localization is the primary factor influencing formatting performance. We hope DocFormBench and DocFormFlow will facilitate future research toward more intelligent and reliable document formatting.
Near-Future Policy Optimization
Apr 22, 2026Reinforcement learning with verifiable rewards (RLVR) has become a core post-training recipe. Introducing suitable off-policy trajectories into on-policy exploration accelerates RLVR convergence and raises the performance ceiling, yet finding a source of such trajectories remains the key challenge. Existing mixed-policy methods either import trajectories from external teachers (high-quality but distributionally far) or replay past training trajectories (close but capped in quality), and neither simultaneously satisfies the strong enough (higher $Q$ , more new knowledge to learn) and close enough (lower $V$ , more readily absorbed) conditions required to maximize the effective learning signal $\mathcal{S} = Q/V$. We propose \textbf{N}ear-Future \textbf{P}olicy \textbf{O}ptimization (\textbf{NPO}), a simple mixed-policy scheme that learns from a policy's own near-future self: a later checkpoint from the same training run is a natural source of auxiliary trajectories that is both stronger than the current policy and closer than any external source, directly balancing trajectory quality against variance cost. We validate NPO through two manual interventions, early-stage bootstrapping and late-stage plateau breakthrough, and further propose \textbf{AutoNPO},an adaptive variant that automatically triggers interventions from online training signals and selects the guide checkpoint that maximizes $S$. On Qwen3-VL-8B-Instruct with GRPO, NPO improves average performance from 57.88 to 62.84, and AutoNPO pushes it to 63.15, raising the final performance ceiling while accelerating convergence.
EXaMCaP: Subset Selection with Entropy Gain Maximization for Probing Capability Gains of Large Chart Understanding Training Sets
Feb 04, 2026Recent works focus on synthesizing Chart Understanding (ChartU) training sets to inject advanced chart knowledge into Multimodal Large Language Models (MLLMs), where the sufficiency of the knowledge is typically verified by quantifying capability gains via the fine-tune-then-evaluate paradigm. However, full-set fine-tuning MLLMs to assess such gains incurs significant time costs, hindering the iterative refinement cycles of the ChartU dataset. Reviewing the ChartU dataset synthesis and data selection domains, we find that subsets can potentially probe the MLLMs' capability gains from full-set fine-tuning. Given that data diversity is vital for boosting MLLMs' performance and entropy reflects this feature, we propose EXaMCaP, which uses entropy gain maximization to select a subset. To obtain a high-diversity subset, EXaMCaP chooses the maximum-entropy subset from the large ChartU dataset. As enumerating all possible subsets is impractical, EXaMCaP iteratively selects samples to maximize the gain in set entropy relative to the current set, approximating the maximum-entropy subset of the full dataset. Experiments show that EXaMCaP outperforms baselines in probing the capability gains of the ChartU training set, along with its strong effectiveness across diverse subset sizes and compatibility with various MLLM architectures.
Blink: Dynamic Visual Token Resolution for Enhanced Multimodal Understanding
Dec 11, 2025Multimodal large language models (MLLMs) have achieved remarkable progress on various vision-language tasks, yet their visual perception remains limited. Humans, in comparison, perceive complex scenes efficiently by dynamically scanning and focusing on salient regions in a sequential "blink-like" process. Motivated by this strategy, we first investigate whether MLLMs exhibit similar behavior. Our pilot analysis reveals that MLLMs naturally attend to different visual regions across layers and that selectively allocating more computation to salient tokens can enhance visual perception. Building on this insight, we propose Blink, a dynamic visual token resolution framework that emulates the human-inspired process within a single forward pass. Specifically, Blink includes two modules: saliency-guided scanning and dynamic token resolution. It first estimates the saliency of visual tokens in each layer based on the attention map, and extends important tokens through a plug-and-play token super-resolution (TokenSR) module. In the next layer, it drops the extended tokens when they lose focus. This dynamic mechanism balances broad exploration and fine-grained focus, thereby enhancing visual perception adaptively and efficiently. Extensive experiments validate Blink, demonstrating its effectiveness in enhancing visual perception and multimodal understanding.
DIVE into MoE: Diversity-Enhanced Reconstruction of Large Language Models from Dense into Mixture-of-Experts
Jun 11, 2025



Large language models (LLMs) with the Mixture-of-Experts (MoE) architecture achieve high cost-efficiency by selectively activating a subset of the parameters. Despite the inference efficiency of MoE LLMs, the training of extensive experts from scratch incurs substantial overhead, whereas reconstructing a dense LLM into an MoE LLM significantly reduces the training budget. However, existing reconstruction methods often overlook the diversity among experts, leading to potential redundancy. In this paper, we come up with the observation that a specific LLM exhibits notable diversity after being pruned on different calibration datasets, based on which we present a Diversity-Enhanced reconstruction method named DIVE. The recipe of DIVE includes domain affinity mining, pruning-based expert reconstruction, and efficient retraining. Specifically, the reconstruction includes pruning and reassembly of the feed-forward network (FFN) module. After reconstruction, we efficiently retrain the model on routers, experts and normalization modules. We implement DIVE on Llama-style LLMs with open-source training corpora. Experiments show that DIVE achieves training efficiency with minimal accuracy trade-offs, outperforming existing pruning and MoE reconstruction methods with the same number of activated parameters.
Adapt Once, Thrive with Updates: Transferable Parameter-Efficient Fine-Tuning on Evolving Base Models
Jun 07, 2025Parameter-efficient fine-tuning (PEFT) has become a common method for fine-tuning large language models, where a base model can serve multiple users through PEFT module switching. To enhance user experience, base models require periodic updates. However, once updated, PEFT modules fine-tuned on previous versions often suffer substantial performance degradation on newer versions. Re-tuning these numerous modules to restore performance would incur significant computational costs. Through a comprehensive analysis of the changes that occur during base model updates, we uncover an interesting phenomenon: continual training primarily affects task-specific knowledge stored in Feed-Forward Networks (FFN), while having less impact on the task-specific pattern in the Attention mechanism. Based on these findings, we introduce Trans-PEFT, a novel approach that enhances the PEFT module by focusing on the task-specific pattern while reducing its dependence on certain knowledge in the base model. Further theoretical analysis supports our approach. Extensive experiments across 7 base models and 12 datasets demonstrate that Trans-PEFT trained modules can maintain performance on updated base models without re-tuning, significantly reducing maintenance overhead in real-world applications.
Advantageous Parameter Expansion Training Makes Better Large Language Models
May 30, 2025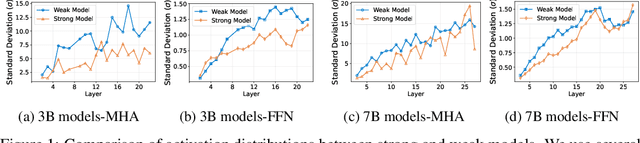
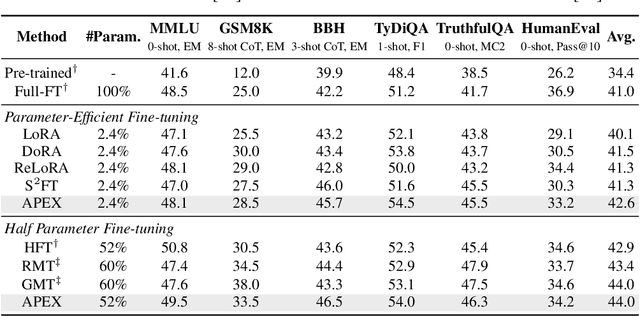
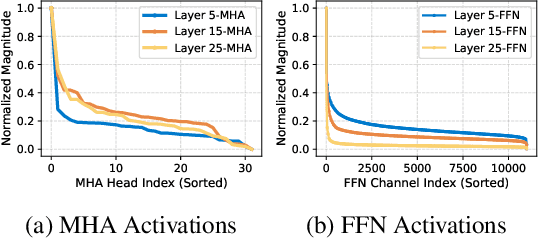
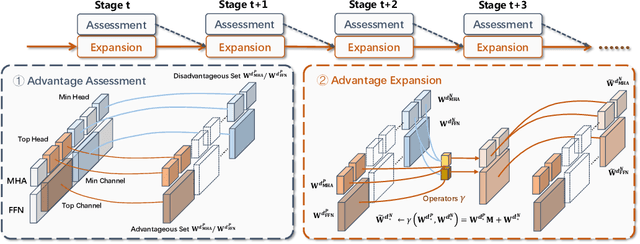
Although scaling up the number of trainable parameters in both pre-training and fine-tuning can effectively improve the performance of large language models, it also leads to increased computational overhead. When delving into the parameter difference, we find that a subset of parameters, termed advantageous parameters, plays a crucial role in determining model performance. Further analysis reveals that stronger models tend to possess more such parameters. In this paper, we propose Advantageous Parameter EXpansion Training (APEX), a method that progressively expands advantageous parameters into the space of disadvantageous ones, thereby increasing their proportion and enhancing training effectiveness. Further theoretical analysis from the perspective of matrix effective rank explains the performance gains of APEX. Extensive experiments on both instruction tuning and continued pre-training demonstrate that, in instruction tuning, APEX outperforms full-parameter tuning while using only 52% of the trainable parameters. In continued pre-training, APEX achieves the same perplexity level as conventional training with just 33% of the training data, and yields significant improvements on downstream tasks.
BeamLoRA: Beam-Constraint Low-Rank Adaptation
Feb 19, 2025Due to the demand for efficient fine-tuning of large language models, Low-Rank Adaptation (LoRA) has been widely adopted as one of the most effective parameter-efficient fine-tuning methods. Nevertheless, while LoRA improves efficiency, there remains room for improvement in accuracy. Herein, we adopt a novel perspective to assess the characteristics of LoRA ranks. The results reveal that different ranks within the LoRA modules not only exhibit varying levels of importance but also evolve dynamically throughout the fine-tuning process, which may limit the performance of LoRA. Based on these findings, we propose BeamLoRA, which conceptualizes each LoRA module as a beam where each rank naturally corresponds to a potential sub-solution, and the fine-tuning process becomes a search for the optimal sub-solution combination. BeamLoRA dynamically eliminates underperforming sub-solutions while expanding the parameter space for promising ones, enhancing performance with a fixed rank. Extensive experiments across three base models and 12 datasets spanning math reasoning, code generation, and commonsense reasoning demonstrate that BeamLoRA consistently enhances the performance of LoRA, surpassing the other baseline methods.
Multimodal Hypothetical Summary for Retrieval-based Multi-image Question Answering
Dec 19, 2024Retrieval-based multi-image question answering (QA) task involves retrieving multiple question-related images and synthesizing these images to generate an answer. Conventional "retrieve-then-answer" pipelines often suffer from cascading errors because the training objective of QA fails to optimize the retrieval stage. To address this issue, we propose a novel method to effectively introduce and reference retrieved information into the QA. Given the image set to be retrieved, we employ a multimodal large language model (visual perspective) and a large language model (textual perspective) to obtain multimodal hypothetical summary in question-form and description-form. By combining visual and textual perspectives, MHyS captures image content more specifically and replaces real images in retrieval, which eliminates the modality gap by transforming into text-to-text retrieval and helps improve retrieval. To more advantageously introduce retrieval with QA, we employ contrastive learning to align queries (questions) with MHyS. Moreover, we propose a coarse-to-fine strategy for calculating both sentence-level and word-level similarity scores, to further enhance retrieval and filter out irrelevant details. Our approach achieves a 3.7% absolute improvement over state-of-the-art methods on RETVQA and a 14.5% improvement over CLIP. Comprehensive experiments and detailed ablation studies demonstrate the superiority of our method.