 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Global Plan in Chain-of-Thought: Uncover the Latent Planning Horizon of LLMs
Feb 02, 2026This work stems from prior complementary observations on the dynamics of Chain-of-Thought (CoT): Large Language Models (LLMs) is shown latent planning of subsequent reasoning prior to CoT emergence, thereby diminishing the significance of explicit CoT; whereas CoT remains critical for tasks requiring multi-step reasoning. To deepen the understanding between LLM's internal states and its verbalized reasoning trajectories, we investigate the latent planning strength of LLMs, through our probing method, Tele-Lens, applying to hidden states across diverse task domains. Our empirical results indicate that LLMs exhibit a myopic horizon, primarily conducting incremental transitions without precise global planning. Leveraging this characteristic, we propose a hypothesis on enhancing uncertainty estimation of CoT, which we validate that a small subset of CoT positions can effectively represent the uncertainty of the entire path. We further underscore the significance of exploiting CoT dynamics, and demonstrate that automatic recognition of CoT bypass can be achieved without performance degradation. Our code, data and models are released at https://github.com/lxucs/tele-lens.
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Dec 30, 2025Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
Mindscape-Aware Retrieval Augmented Generation for Improved Long Context Understanding
Dec 19, 2025Humans understand long and complex texts by relying on a holistic semantic representation of the content. This global view helps organize prior knowledge, interpret new information, and integrate evidence dispersed across a document, as revealed by the Mindscape-Aware Capability of humans in psychology. Current Retrieval-Augmented Generation (RAG) systems lack such guidance and therefore struggle with long-context tasks. In this paper, we propose Mindscape-Aware RAG (MiA-RAG), the first approach that equips LLM-based RAG systems with explicit global context awareness. MiA-RAG builds a mindscape through hierarchical summarization and conditions both retrieval and generation on this global semantic representation. This enables the retriever to form enriched query embeddings and the generator to reason over retrieved evidence within a coherent global context. We evaluate MiA-RAG across diverse long-context and bilingual benchmarks for evidence-based understanding and global sense-making. It consistently surpasses baselines, and further analysis shows that it aligns local details with a coherent global representation, enabling more human-like long-context retrieval and reasoning.
DivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
Sep 19, 2025Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.
ComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning
Aug 14, 2025



Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given the LLM's diminished reasoning over extended context and high computational cost, retrieval-based approaches remain a pivotal role in practice. However, traditional RAG methods can fall short due to their stateless, single-step retrieval process, which often overlooks the dynamic nature of capturing interconnected relations within long-range context. In this work, we propose ComoRAG, holding the principle that narrative reasoning is not a one-shot process, but a dynamic, evolving interplay between new evidence acquisition and past knowledge consolidation, analogous to human cognition when reasoning with memory-related signals in the brain. Specifically, when encountering a reasoning impasse, ComoRAG undergoes iterative reasoning cycles while interacting with a dynamic memory workspace. In each cycle, it generates probing queries to devise new exploratory paths, then integrates the retrieved evidence of new aspects into a global memory pool, thereby supporting the emergence of a coherent context for the query resolution. Across four challenging long-context narrative benchmarks (200K+ tokens), ComoRAG outperforms strong RAG baselines with consistent relative gains up to 11% compared to the strongest baseline. Further analysis reveals that ComoRAG is particularly advantageous for complex queries requiring global comprehension, offering a principled, cognitively motivated paradigm for retrieval-based long context comprehension towards stateful reasoning. Our code is publicly released at https://github.com/EternityJune25/ComoRAG
Dense Retrievers Can Fail on Simple Queries: Revealing The Granularity Dilemma of Embeddings
Jun 10, 2025This work focuses on an observed limitation of text encoders: embeddings may not be able to recognize fine-grained entities or events within the semantics, resulting in failed dense retrieval on even simple cases. To examine such behaviors, we first introduce a new evaluation dataset in Chinese, named CapRetrieval, whose passages are image captions, and queries are phrases inquiring entities or events in various forms. Zero-shot evaluation suggests that encoders may fail on these fine-grained matching, regardless of training sources or model sizes. Aiming for enhancement, we proceed to finetune encoders with our proposed data generation strategies, which obtains the best performance on CapRetrieval. Within this process, we further identify an issue of granularity dilemma, a challenge for embeddings to express fine-grained salience while aligning with overall semantics. Our dataset, code and models in this work are publicly released at https://github.com/lxucs/CapRetrieval.
Pushing the Limits of Low-Bit Optimizers: A Focus on EMA Dynamics
May 01, 2025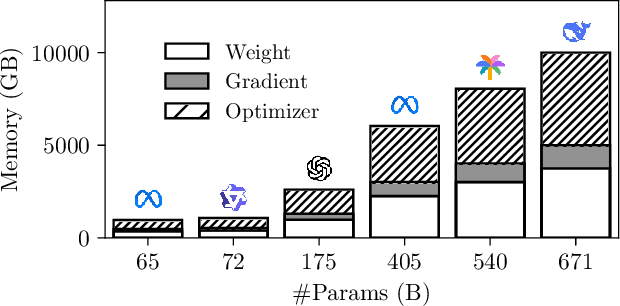
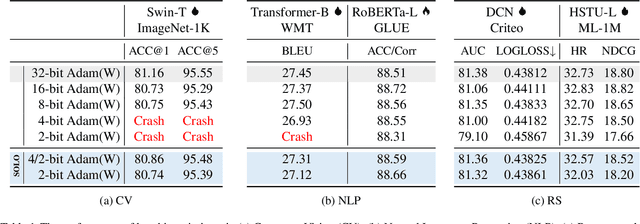
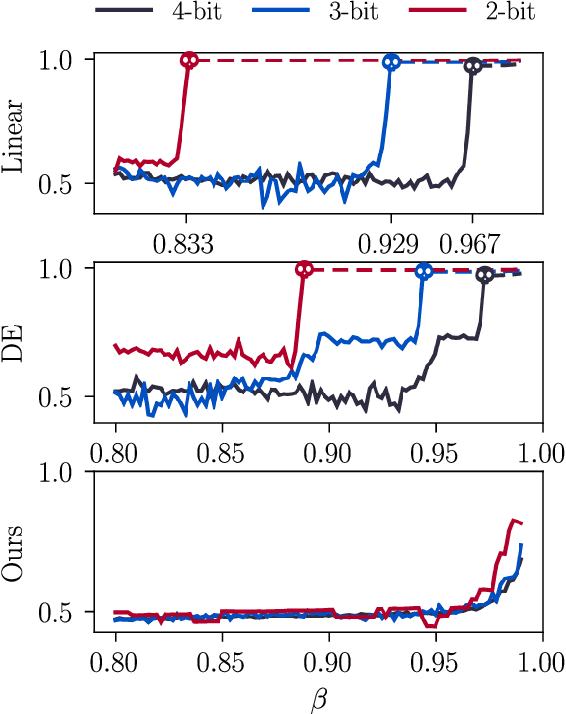
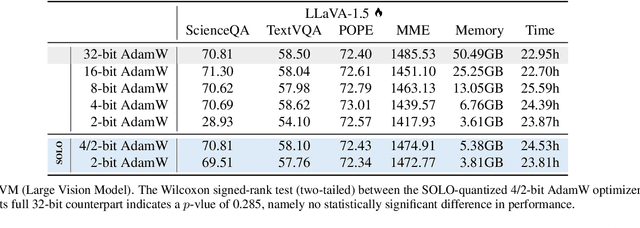
The explosion in model sizes leads to continued growth in prohibitive training/fine-tuning costs, particularly for stateful optimizers which maintain auxiliary information of even 2x the model size to achieve optimal convergence. We therefore present in this work a novel type of optimizer that carries with extremely lightweight state overloads, achieved through ultra-low-precision quantization. While previous efforts have achieved certain success with 8-bit or 4-bit quantization, our approach enables optimizers to operate at precision as low as 3 bits, or even 2 bits per state element. This is accomplished by identifying and addressing two critical challenges: the signal swamping problem in unsigned quantization that results in unchanged state dynamics, and the rapidly increased gradient variance in signed quantization that leads to incorrect descent directions. The theoretical analysis suggests a tailored logarithmic quantization for the former and a precision-specific momentum value for the latter. Consequently, the proposed SOLO achieves substantial memory savings (approximately 45 GB when training a 7B model) with minimal accuracy loss. We hope that SOLO can contribute to overcoming the bottleneck in computational resources, thereby promoting greater accessibility in fundamental research.
FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
Mar 11, 2025Due to the data-driven nature of current face identity (FaceID) customization methods, all state-of-the-art models rely on large-scale datasets containing millions of high-quality text-image pairs for training. However, none of these datasets are publicly available, which restricts transparency and hinders further advancements in the field. To address this issue, in this paper, we collect and release FaceID-6M, the first large-scale, open-source FaceID dataset containing 6 million high-quality text-image pairs. Filtered from LAION-5B \cite{schuhmann2022laion}, FaceID-6M undergoes a rigorous image and text filtering steps to ensure dataset quality, including resolution filtering to maintain high-quality images and faces, face filtering to remove images that lack human faces, and keyword-based strategy to retain descriptions containing human-related terms (e.g., nationality, professions and names). Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development. We conduct extensive experiments to show the effectiveness of our FaceID-6M, demonstrating that models trained on our FaceID-6M dataset achieve performance that is comparable to, and slightly better than currently available industrial models. Additionally, to support and advance research in the FaceID customization community, we make our code, datasets, and models fully publicly available. Our codes, models, and datasets are available at: https://github.com/ShuheSH/FaceID-6M.
DBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Feb 24, 2025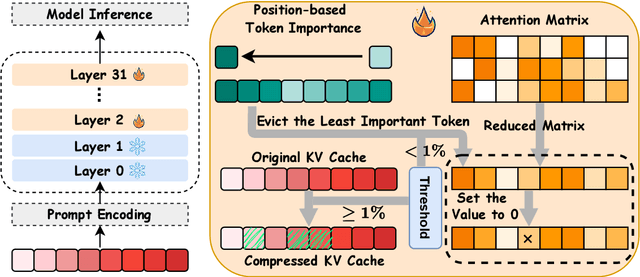
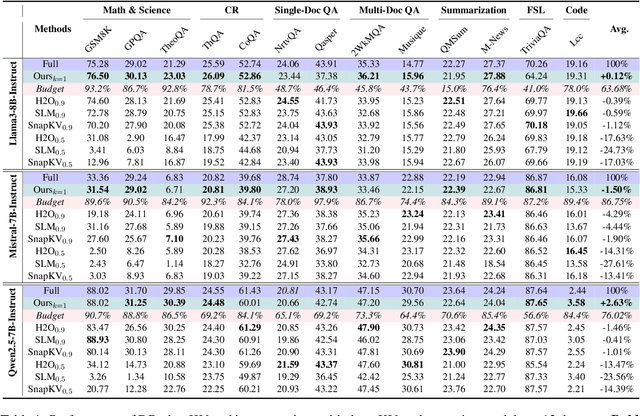
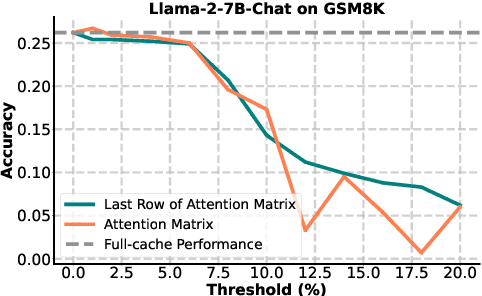
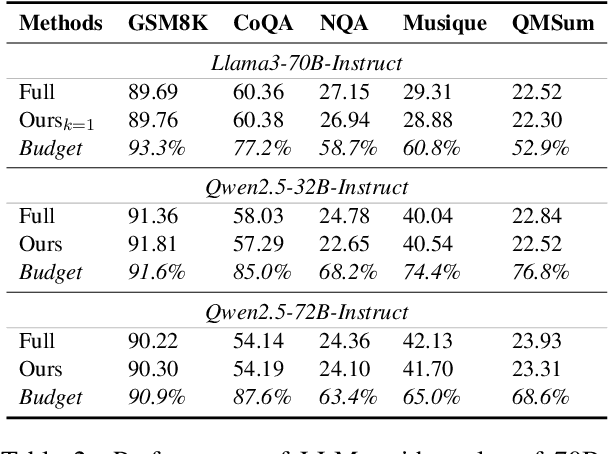
To alleviate memory burden during inference of large language models (LLMs), numerous studies have focused on compressing the KV cache by exploring aspects such as attention sparsity. However, these techniques often require a pre-defined cache budget; as the optimal budget varies with different input lengths and task types, it limits their practical deployment accepting open-domain instructions. To address this limitation, we propose a new KV cache compression objective: to always ensure the full-cache performance regardless of specific inputs, while maximizing KV cache pruning as much as possible. To achieve this goal, we introduce a novel KV cache compression method dubbed DBudgetKV, which features an attention-based metric to signal when the remaining KV cache is unlikely to match the full-cache performance, then halting the pruning process. Empirical evaluation spanning diverse context lengths, task types, and model sizes suggests that our method achieves lossless KV pruning effectively and robustly, exceeding 25% compression ratio on average. Furthermore, our method is easy to integrate within LLM inference, not only optimizing memory space, but also showing reduced inference time compared to existing methods.
The Stochastic Parrot on LLM's Shoulder: A Summative Assessment of Physical Concept Understanding
Feb 13, 2025



In a systematic way, we investigate a widely asked question: Do LLMs really understand what they say?, which relates to the more familiar term Stochastic Parrot. To this end, we propose a summative assessment over a carefully designed physical concept understanding task, PhysiCo. Our task alleviates the memorization issue via the usage of grid-format inputs that abstractly describe physical phenomena. The grids represents varying levels of understanding, from the core phenomenon, application examples to analogies to other abstract patterns in the grid world. A comprehensive study on our task demonstrates: (1) state-of-the-art LLMs, including GPT-4o, o1 and Gemini 2.0 flash thinking, lag behind humans by ~40%; (2) the stochastic parrot phenomenon is present in LLMs, as they fail on our grid task but can describe and recognize the same concepts well in natural language; (3) our task challenges the LLMs due to intrinsic difficulties rather than the unfamiliar grid format, as in-context learning and fine-tuning on same formatted data added little to their performance.