 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudge Like Human Examiners: A Weighted Importance Multi-Point Evaluation Framework for Generative Tasks with Long-form Answers
Apr 14, 2026Evaluating the quality of model responses remains challenging in generative tasks with long-form answers, as the expected answers usually contain multiple semantically distinct yet complementary factors that should be factorized for fine-grained assessment. Recent evaluation methods resort to relying on either task-level rubrics or question-aware checklists. However, they still 1) struggle to assess whether a response is genuinely grounded in provided contexts; 2) fail to capture the heterogeneous importance of different aspects of reference answers. Inspired by human examiners, we propose a Weighted Importance Multi-Point Evaluation (WIMPE) framework, which factorizes each reference answer into weighted context-bound scoring points. Two complementary metrics, namely Weighted Point-wise Alignment (WPA) and Point-wise Conflict Penalty (PCP), are designed to measure the alignment and contradiction between model responses and reference answers. Extensive experiments on 10 generative tasks demonstrate that WIMPE achieves higher correlations with human annotations.
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Dec 30, 2025Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
The Essence of Contextual Understanding in Theory of Mind: A Study on Question Answering with Story Characters
Jan 03, 2025



Theory-of-Mind (ToM) is a fundamental psychological capability that allows humans to understand and interpret the mental states of others. Humans infer others' thoughts by integrating causal cues and indirect clues from broad contextual information, often derived from past interactions. In other words, human ToM heavily relies on the understanding about the backgrounds and life stories of others. Unfortunately, this aspect is largely overlooked in existing benchmarks for evaluating machines' ToM capabilities, due to their usage of short narratives without global backgrounds. In this paper, we verify the importance of understanding long personal backgrounds in ToM and assess the performance of LLMs in such realistic evaluation scenarios. To achieve this, we introduce a novel benchmark, CharToM-QA, comprising 1,035 ToM questions based on characters from classic novels. Our human study reveals a significant disparity in performance: the same group of educated participants performs dramatically better when they have read the novels compared to when they have not. In parallel, our experiments on state-of-the-art LLMs, including the very recent o1 model, show that LLMs still perform notably worse than humans, despite that they have seen these stories during pre-training. This highlights the limitations of current LLMs in capturing the nuanced contextual information required for ToM reasoning.
RC3: Regularized Contrastive Cross-lingual Cross-modal Pre-training
May 13, 2023



Multilingual vision-language (V&L) pre-training has achieved remarkable progress in learning universal representations across different modalities and languages. In spite of recent success, there still remain challenges limiting further improvements of V&L pre-trained models in multilingual settings. Particularly, current V&L pre-training methods rely heavily on strictly-aligned multilingual image-text pairs generated from English-centric datasets through machine translation. However, the cost of collecting and translating such strictly-aligned datasets is usually unbearable. In this paper, we propose Regularized Contrastive Cross-lingual Cross-modal (RC^3) pre-training, which further exploits more abundant weakly-aligned multilingual image-text pairs. Specifically, we design a regularized cross-lingual visio-textual contrastive learning objective that constrains the representation proximity of weakly-aligned visio-textual inputs according to textual relevance. Besides, existing V&L pre-training approaches mainly deal with visual inputs by either region-of-interest (ROI) features or patch embeddings. We flexibly integrate the two forms of visual features into our model for pre-training and downstream multi-modal tasks. Extensive experiments on 5 downstream multi-modal tasks across 6 languages demonstrate the effectiveness of our proposed method over competitive contrast models with stronger zero-shot capability.
A Multi-task Multi-stage Transitional Training Framework for Neural Chat Translation
Jan 27, 2023
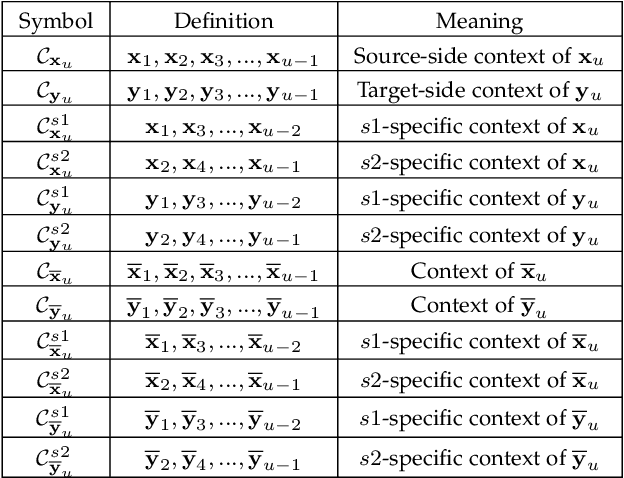


Neural chat translation (NCT) aims to translate a cross-lingual chat between speakers of different languages. Existing context-aware NMT models cannot achieve satisfactory performances due to the following inherent problems: 1) limited resources of annotated bilingual dialogues; 2) the neglect of modelling conversational properties; 3) training discrepancy between different stages. To address these issues, in this paper, we propose a multi-task multi-stage transitional (MMT) training framework, where an NCT model is trained using the bilingual chat translation dataset and additional monolingual dialogues. We elaborately design two auxiliary tasks, namely utterance discrimination and speaker discrimination, to introduce the modelling of dialogue coherence and speaker characteristic into the NCT model. The training process consists of three stages: 1) sentence-level pre-training on large-scale parallel corpus; 2) intermediate training with auxiliary tasks using additional monolingual dialogues; 3) context-aware fine-tuning with gradual transition. Particularly, the second stage serves as an intermediate phase that alleviates the training discrepancy between the pre-training and fine-tuning stages. Moreover, to make the stage transition smoother, we train the NCT model using a gradual transition strategy, i.e., gradually transiting from using monolingual to bilingual dialogues. Extensive experiments on two language pairs demonstrate the effectiveness and superiority of our proposed training framework.
Getting the Most out of Simile Recognition
Nov 11, 2022
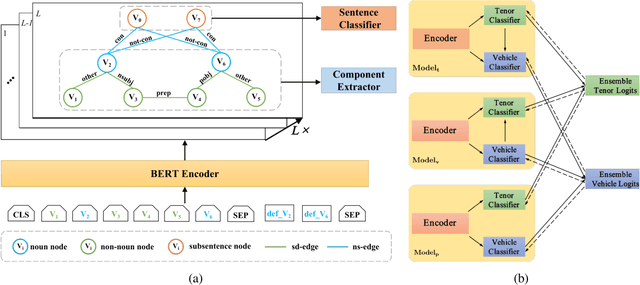
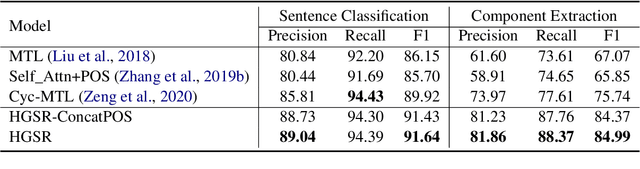
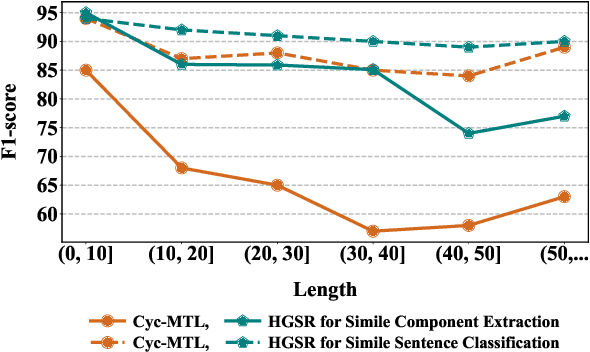
Simile recognition involves two subtasks: simile sentence classification that discriminates whether a sentence contains simile, and simile component extraction that locates the corresponding objects (i.e., tenors and vehicles). Recent work ignores features other than surface strings. In this paper, we explore expressive features for this task to achieve more effective data utilization. Particularly, we study two types of features: 1) input-side features that include POS tags, dependency trees and word definitions, and 2) decoding features that capture the interdependence among various decoding decisions. We further construct a model named HGSR, which merges the input-side features as a heterogeneous graph and leverages decoding features via distillation. Experiments show that HGSR significantly outperforms the current state-of-the-art systems and carefully designed baselines, verifying the effectiveness of introduced features. Our code is available at https://github.com/DeepLearnXMU/HGSR.
Towards Robust k-Nearest-Neighbor Machine Translation
Oct 17, 2022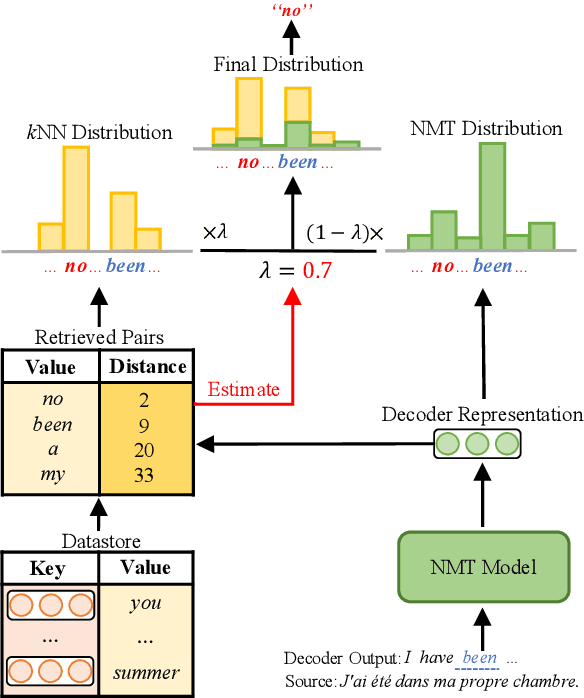
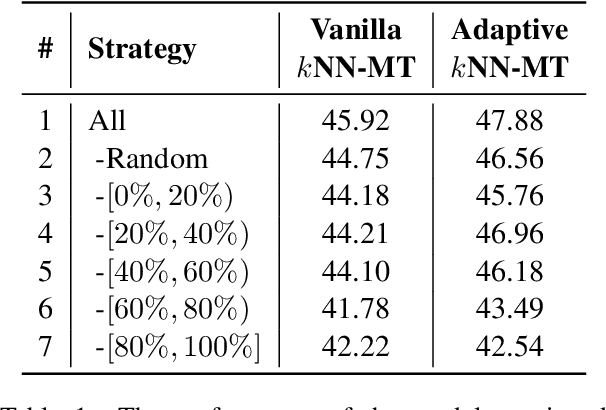
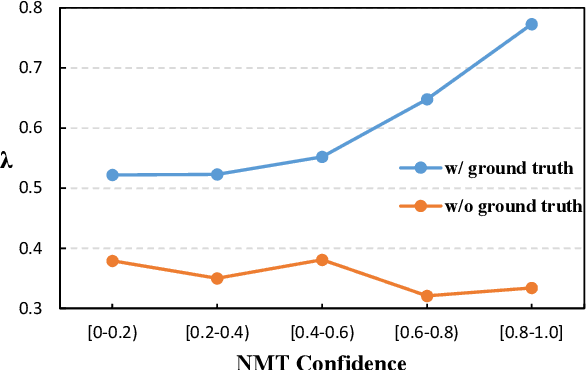
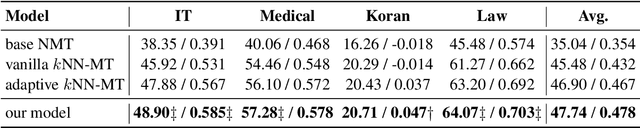
k-Nearest-Neighbor Machine Translation (kNN-MT) becomes an important research direction of NMT in recent years. Its main idea is to retrieve useful key-value pairs from an additional datastore to modify translations without updating the NMT model. However, the underlying retrieved noisy pairs will dramatically deteriorate the model performance. In this paper, we conduct a preliminary study and find that this problem results from not fully exploiting the prediction of the NMT model. To alleviate the impact of noise, we propose a confidence-enhanced kNN-MT model with robust training. Concretely, we introduce the NMT confidence to refine the modeling of two important components of kNN-MT: kNN distribution and the interpolation weight. Meanwhile we inject two types of perturbations into the retrieved pairs for robust training. Experimental results on four benchmark datasets demonstrate that our model not only achieves significant improvements over current kNN-MT models, but also exhibits better robustness. Our code is available at https://github.com/DeepLearnXMU/Robust-knn-mt.
A Variational Hierarchical Model for Neural Cross-Lingual Summarization
Mar 25, 2022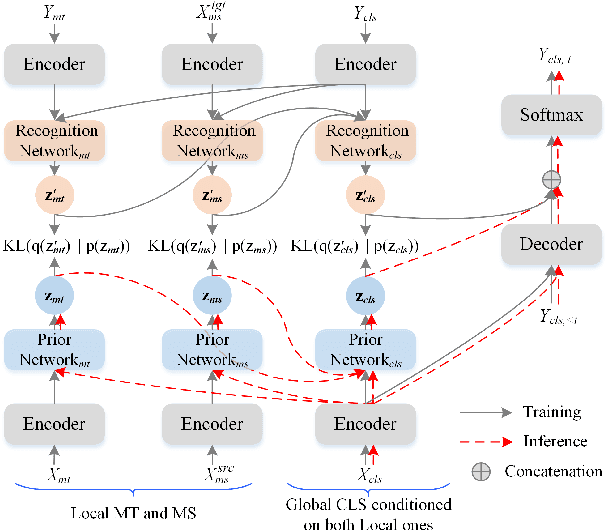
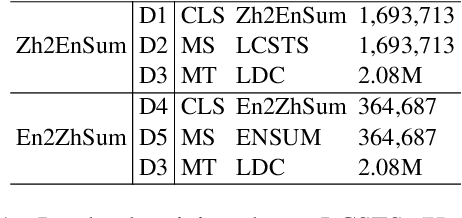
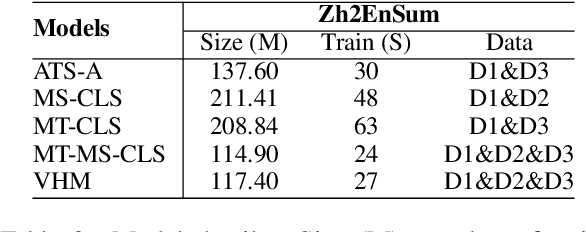
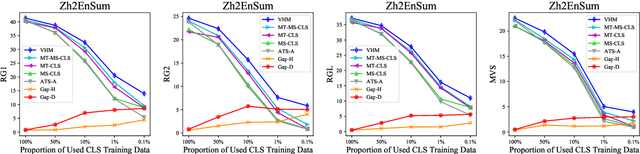
The goal of the cross-lingual summarization (CLS) is to convert a document in one language (e.g., English) to a summary in another one (e.g., Chinese). Essentially, the CLS task is the combination of machine translation (MT) and monolingual summarization (MS), and thus there exists the hierarchical relationship between MT\&MS and CLS. Existing studies on CLS mainly focus on utilizing pipeline methods or jointly training an end-to-end model through an auxiliary MT or MS objective. However, it is very challenging for the model to directly conduct CLS as it requires both the abilities to translate and summarize. To address this issue, we propose a hierarchical model for the CLS task, based on the conditional variational auto-encoder. The hierarchical model contains two kinds of latent variables at the local and global levels, respectively. At the local level, there are two latent variables, one for translation and the other for summarization. As for the global level, there is another latent variable for cross-lingual summarization conditioned on the two local-level variables. Experiments on two language directions (English-Chinese) verify the effectiveness and superiority of the proposed approach. In addition, we show that our model is able to generate better cross-lingual summaries than comparison models in the few-shot setting.
Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation
Mar 17, 2022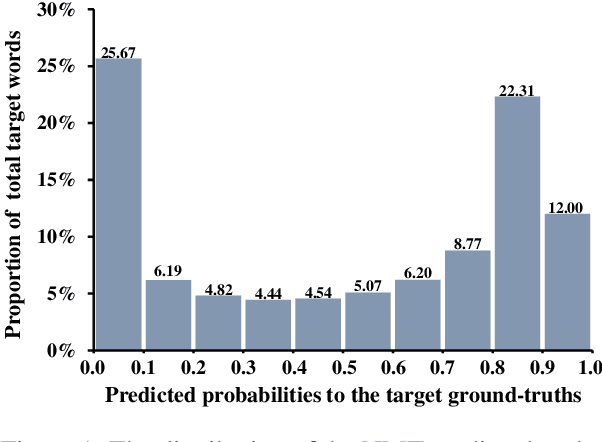

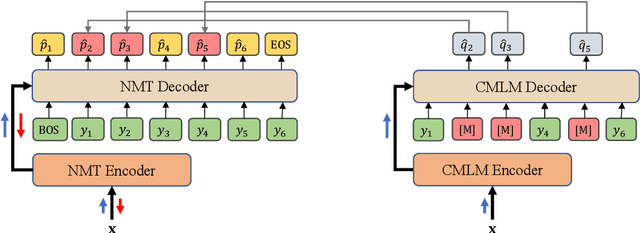
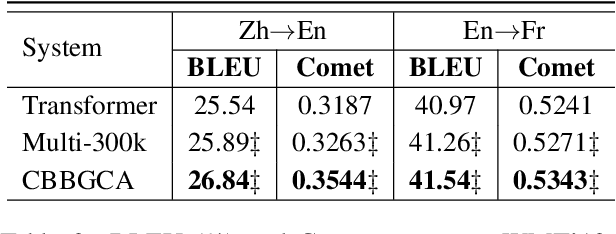
Most dominant neural machine translation (NMT) models are restricted to make predictions only according to the local context of preceding words in a left-to-right manner. Although many previous studies try to incorporate global information into NMT models, there still exist limitations on how to effectively exploit bidirectional global context. In this paper, we propose a Confidence Based Bidirectional Global Context Aware (CBBGCA) training framework for NMT, where the NMT model is jointly trained with an auxiliary conditional masked language model (CMLM). The training consists of two stages: (1) multi-task joint training; (2) confidence based knowledge distillation. At the first stage, by sharing encoder parameters, the NMT model is additionally supervised by the signal from the CMLM decoder that contains bidirectional global contexts. Moreover, at the second stage, using the CMLM as teacher, we further pertinently incorporate bidirectional global context to the NMT model on its unconfidently-predicted target words via knowledge distillation. Experimental results show that our proposed CBBGCA training framework significantly improves the NMT model by +1.02, +1.30 and +0.57 BLEU scores on three large-scale translation datasets, namely WMT'14 English-to-German, WMT'19 Chinese-to-English and WMT'14 English-to-French, respectively.
Towards Making the Most of Dialogue Characteristics for Neural Chat Translation
Sep 02, 2021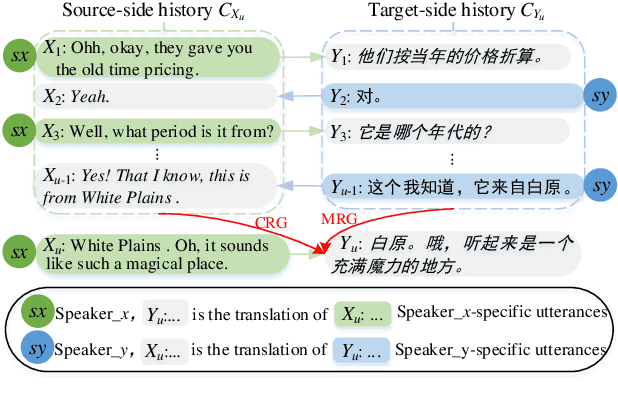
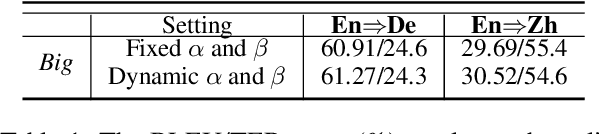
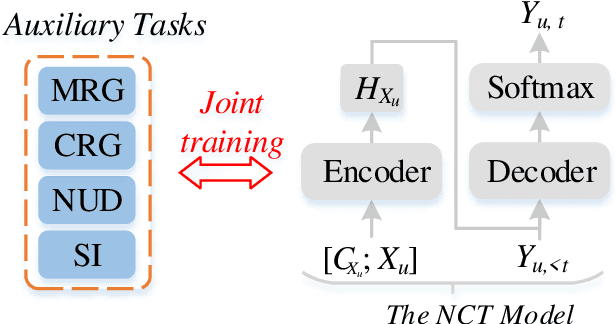
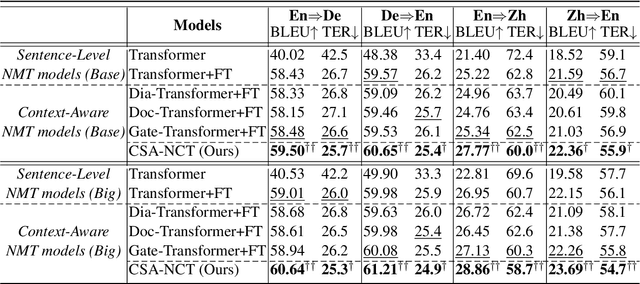
Neural Chat Translation (NCT) aims to translate conversational text between speakers of different languages. Despite the promising performance of sentence-level and context-aware neural machine translation models, there still remain limitations in current NCT models because the inherent dialogue characteristics of chat, such as dialogue coherence and speaker personality, are neglected. In this paper, we propose to promote the chat translation by introducing the modeling of dialogue characteristics into the NCT model. To this end, we design four auxiliary tasks including monolingual response generation, cross-lingual response generation, next utterance discrimination, and speaker identification. Together with the main chat translation task, we optimize the NCT model through the training objectives of all these tasks. By this means, the NCT model can be enhanced by capturing the inherent dialogue characteristics, thus generating more coherent and speaker-relevant translations. Comprehensive experiments on four language directions (English-German and English-Chinese) verify the effectiveness and superiority of the proposed approach.