 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Bayesian Design for Efficient Surrogate Construction in the Inversion of Darcy Flows
Jul 23, 2025Inverse problems governed by partial differential equations (PDEs) play a crucial role in various fields, including computational science, image processing, and engineering. Particularly, Darcy flow equation is a fundamental equation in fluid mechanics, which plays a crucial role in understanding fluid flow through porous media. Bayesian methods provide an effective approach for solving PDEs inverse problems, while their numerical implementation requires numerous evaluations of computationally expensive forward solvers. Therefore, the adoption of surrogate models with lower computational costs is essential. However, constructing a globally accurate surrogate model for high-dimensional complex problems demands high model capacity and large amounts of data. To address this challenge, this study proposes an efficient locally accurate surrogate that focuses on the high-probability regions of the true likelihood in inverse problems, with relatively low model complexity and few training data requirements. Additionally, we introduce a sequential Bayesian design strategy to acquire the proposed surrogate since the high-probability region of the likelihood is unknown. The strategy treats the posterior evolution process of sequential Bayesian design as a Gaussian process, enabling algorithmic acceleration through one-step ahead prior. The complete algorithmic framework is referred to as Sequential Bayesian design for locally accurate surrogate (SBD-LAS). Finally, three experiments based the Darcy flow equation demonstrate the advantages of the proposed method in terms of both inversion accuracy and computational speed.
Joint Training or Not: An Exploration of Pre-trained Speech Models in Audio-Visual Speaker Diarization
Dec 07, 2023



The scarcity of labeled audio-visual datasets is a constraint for training superior audio-visual speaker diarization systems. To improve the performance of audio-visual speaker diarization, we leverage pre-trained supervised and self-supervised speech models for audio-visual speaker diarization. Specifically, we adopt supervised~(ResNet and ECAPA-TDNN) and self-supervised pre-trained models~(WavLM and HuBERT) as the speaker and audio embedding extractors in an end-to-end audio-visual speaker diarization~(AVSD) system. Then we explore the effectiveness of different frameworks, including Transformer, Conformer, and cross-attention mechanism, in the audio-visual decoder. To mitigate the degradation of performance caused by separate training, we jointly train the audio encoder, speaker encoder, and audio-visual decoder in the AVSD system. Experiments on the MISP dataset demonstrate that the proposed method achieves superior performance and obtained third place in MISP Challenge 2022.
The FlySpeech Audio-Visual Speaker Diarization System for MISP Challenge 2022
Jul 28, 2023


This paper describes the FlySpeech speaker diarization system submitted to the second \textbf{M}ultimodal \textbf{I}nformation Based \textbf{S}peech \textbf{P}rocessing~(\textbf{MISP}) Challenge held in ICASSP 2022. We develop an end-to-end audio-visual speaker diarization~(AVSD) system, which consists of a lip encoder, a speaker encoder, and an audio-visual decoder. Specifically, to mitigate the degradation of diarization performance caused by separate training, we jointly train the speaker encoder and the audio-visual decoder. In addition, we leverage the large-data pretrained speaker extractor to initialize the speaker encoder.
Wespeaker baselines for VoxSRC2023
Jun 28, 2023



This report showcases the results achieved using the wespeaker toolkit for the VoxSRC2023 Challenge. Our aim is to provide participants, especially those with limited experience, with clear and straightforward guidelines to develop their initial systems. Via well-structured recipes and strong results, we hope to offer an accessible and good enough start point for all interested individuals. In this report, we describe the results achieved on the VoxSRC2023 dev set using the pretrained models, you can check the CodaLab evaluation server for the results on the evaluation set.
Distance-based Weight Transfer from Near-field to Far-field Speaker Verification
Mar 15, 2023


The scarcity of labeled far-field speech is a constraint for training superior far-field speaker verification systems. Fine-tuning the model pre-trained on large-scale near-field speech substantially outperforms training from scratch. However, the fine-tuning method suffers from two limitations--catastrophic forgetting and overfitting. In this paper, we propose a weight transfer regularization(WTR) loss to constrain the distance of the weights between the pre-trained model with large-scale near-field speech and the fine-tuned model through a small number of far-field speech. With the WTR loss, the fine-tuning process takes advantage of the previously acquired discriminative ability from the large-scale near-field speech without catastrophic forgetting. Meanwhile, we use the PAC-Bayes generalization theory to analyze the generalization bound of the fine-tuned model with the WTR loss. The analysis result indicates that the WTR term makes the fine-tuned model have a tighter generalization upper bound. Moreover, we explore three kinds of norm distance for weight transfer, which are L1-norm distance, L2-norm distance and Max-norm distance. Finally, we evaluate the effectiveness of the WTR loss on VoxCeleb (pre-trained dataset) and FFSVC (fine-tuned dataset) datasets.
A Multi-task Multi-stage Transitional Training Framework for Neural Chat Translation
Jan 27, 2023
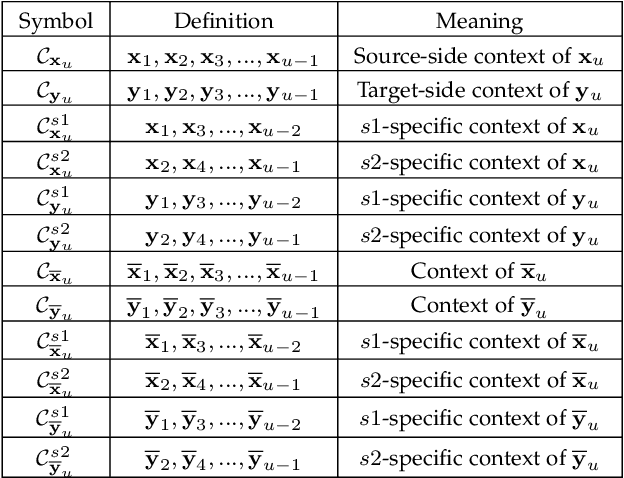


Neural chat translation (NCT) aims to translate a cross-lingual chat between speakers of different languages. Existing context-aware NMT models cannot achieve satisfactory performances due to the following inherent problems: 1) limited resources of annotated bilingual dialogues; 2) the neglect of modelling conversational properties; 3) training discrepancy between different stages. To address these issues, in this paper, we propose a multi-task multi-stage transitional (MMT) training framework, where an NCT model is trained using the bilingual chat translation dataset and additional monolingual dialogues. We elaborately design two auxiliary tasks, namely utterance discrimination and speaker discrimination, to introduce the modelling of dialogue coherence and speaker characteristic into the NCT model. The training process consists of three stages: 1) sentence-level pre-training on large-scale parallel corpus; 2) intermediate training with auxiliary tasks using additional monolingual dialogues; 3) context-aware fine-tuning with gradual transition. Particularly, the second stage serves as an intermediate phase that alleviates the training discrepancy between the pre-training and fine-tuning stages. Moreover, to make the stage transition smoother, we train the NCT model using a gradual transition strategy, i.e., gradually transiting from using monolingual to bilingual dialogues. Extensive experiments on two language pairs demonstrate the effectiveness and superiority of our proposed training framework.
Wespeaker: A Research and Production oriented Speaker Embedding Learning Toolkit
Nov 01, 2022Speaker modeling is essential for many related tasks, such as speaker recognition and speaker diarization. The dominant modeling approach is fixed-dimensional vector representation, i.e., speaker embedding. This paper introduces a research and production oriented speaker embedding learning toolkit, Wespeaker. Wespeaker contains the implementation of scalable data management, state-of-the-art speaker embedding models, loss functions, and scoring back-ends, with highly competitive results achieved by structured recipes which were adopted in the winning systems in several speaker verification challenges. The application to other downstream tasks such as speaker diarization is also exhibited in the related recipe. Moreover, CPU- and GPU-compatible deployment codes are integrated for production-oriented development. The toolkit is publicly available at https://github.com/wenet-e2e/wespeaker.
Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation
Mar 17, 2022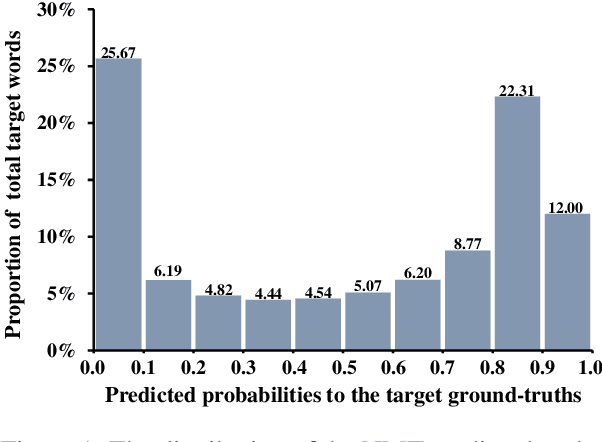

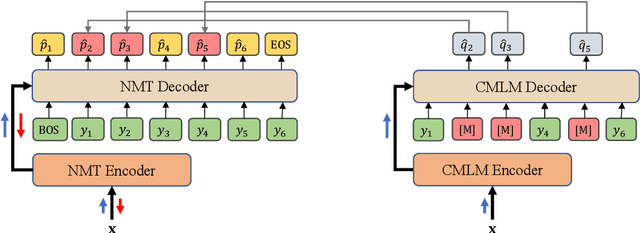
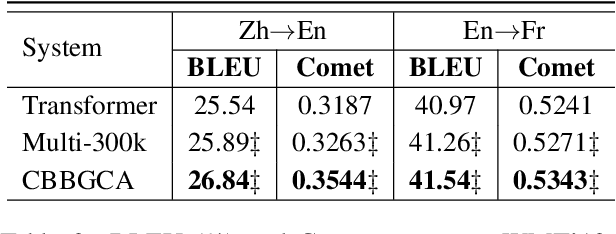
Most dominant neural machine translation (NMT) models are restricted to make predictions only according to the local context of preceding words in a left-to-right manner. Although many previous studies try to incorporate global information into NMT models, there still exist limitations on how to effectively exploit bidirectional global context. In this paper, we propose a Confidence Based Bidirectional Global Context Aware (CBBGCA) training framework for NMT, where the NMT model is jointly trained with an auxiliary conditional masked language model (CMLM). The training consists of two stages: (1) multi-task joint training; (2) confidence based knowledge distillation. At the first stage, by sharing encoder parameters, the NMT model is additionally supervised by the signal from the CMLM decoder that contains bidirectional global contexts. Moreover, at the second stage, using the CMLM as teacher, we further pertinently incorporate bidirectional global context to the NMT model on its unconfidently-predicted target words via knowledge distillation. Experimental results show that our proposed CBBGCA training framework significantly improves the NMT model by +1.02, +1.30 and +0.57 BLEU scores on three large-scale translation datasets, namely WMT'14 English-to-German, WMT'19 Chinese-to-English and WMT'14 English-to-French, respectively.
Asynchronous Bidirectional Decoding for Neural Machine Translation
Feb 03, 2018
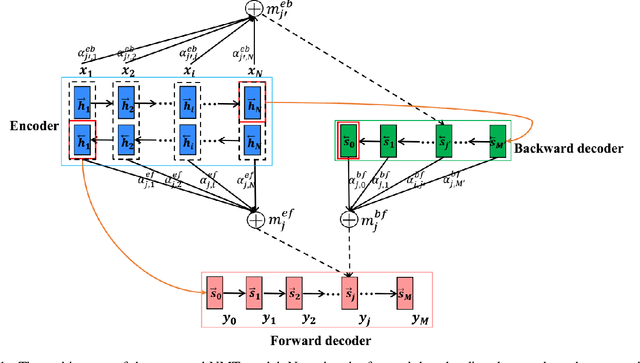
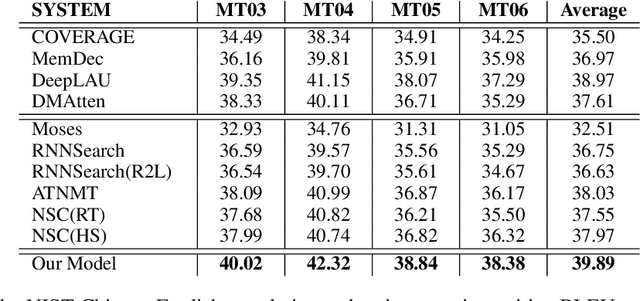
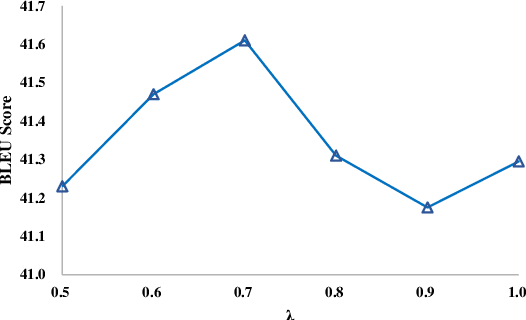
The dominant neural machine translation (NMT) models apply unified attentional encoder-decoder neural networks for translation. Traditionally, the NMT decoders adopt recurrent neural networks (RNNs) to perform translation in a left-toright manner, leaving the target-side contexts generated from right to left unexploited during translation. In this paper, we equip the conventional attentional encoder-decoder NMT framework with a backward decoder, in order to explore bidirectional decoding for NMT. Attending to the hidden state sequence produced by the encoder, our backward decoder first learns to generate the target-side hidden state sequence from right to left. Then, the forward decoder performs translation in the forward direction, while in each translation prediction timestep, it simultaneously applies two attention models to consider the source-side and reverse target-side hidden states, respectively. With this new architecture, our model is able to fully exploit source- and target-side contexts to improve translation quality altogether. Experimental results on NIST Chinese-English and WMT English-German translation tasks demonstrate that our model achieves substantial improvements over the conventional NMT by 3.14 and 1.38 BLEU points, respectively. The source code of this work can be obtained from https://github.com/DeepLearnXMU/ABDNMT.