 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Graph Clustering with Multi-Scale Weight-Based Pairwise Coarsening and Contrastive Learning
Jul 28, 2025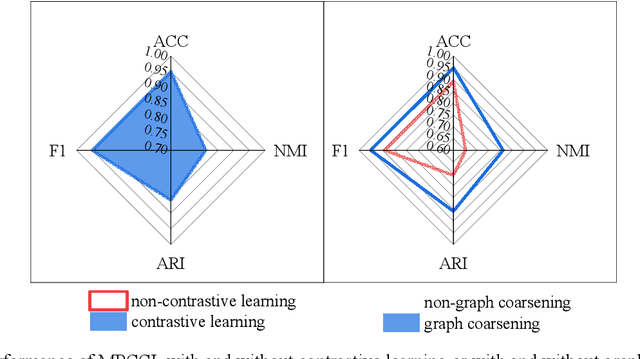
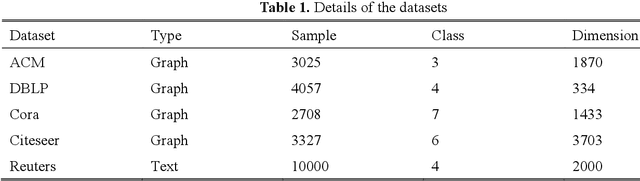
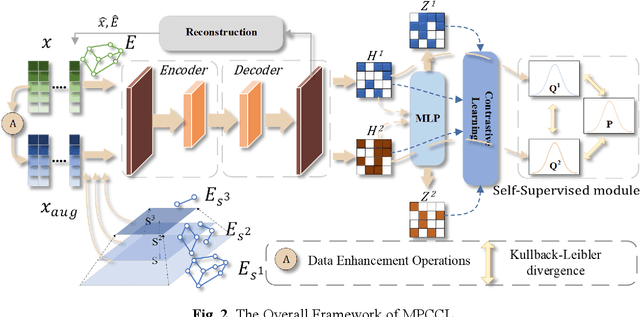
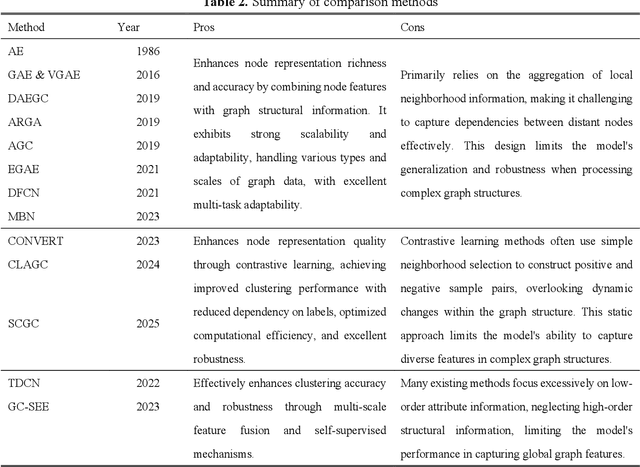
This study introduces the Multi-Scale Weight-Based Pairwise Coarsening and Contrastive Learning (MPCCL) model, a novel approach for attributed graph clustering that effectively bridges critical gaps in existing methods, including long-range dependency, feature collapse, and information loss. Traditional methods often struggle to capture high-order graph features due to their reliance on low-order attribute information, while contrastive learning techniques face limitations in feature diversity by overemphasizing local neighborhood structures. Similarly, conventional graph coarsening methods, though reducing graph scale, frequently lose fine-grained structural details. MPCCL addresses these challenges through an innovative multi-scale coarsening strategy, which progressively condenses the graph while prioritizing the merging of key edges based on global node similarity to preserve essential structural information. It further introduces a one-to-many contrastive learning paradigm, integrating node embeddings with augmented graph views and cluster centroids to enhance feature diversity, while mitigating feature masking issues caused by the accumulation of high-frequency node weights during multi-scale coarsening. By incorporating a graph reconstruction loss and KL divergence into its self-supervised learning framework, MPCCL ensures cross-scale consistency of node representations. Experimental evaluations reveal that MPCCL achieves a significant improvement in clustering performance, including a remarkable 15.24% increase in NMI on the ACM dataset and notable robust gains on smaller-scale datasets such as Citeseer, Cora and DBLP.
* The source code for this study is available at https://github.com/YF-W/MPCCL
Wespeaker baselines for VoxSRC2023
Jun 28, 2023



This report showcases the results achieved using the wespeaker toolkit for the VoxSRC2023 Challenge. Our aim is to provide participants, especially those with limited experience, with clear and straightforward guidelines to develop their initial systems. Via well-structured recipes and strong results, we hope to offer an accessible and good enough start point for all interested individuals. In this report, we describe the results achieved on the VoxSRC2023 dev set using the pretrained models, you can check the CodaLab evaluation server for the results on the evaluation set.
Build a SRE Challenge System: Lessons from VoxSRC 2022 and CNSRC 2022
Nov 02, 2022Different speaker recognition challenges have been held to assess the speaker verification system in the wild and probe the performance limit. Voxceleb Speaker Recognition Challenge (VoxSRC), based on the voxceleb, is the most popular. Besides, another challenge called CN-Celeb Speaker Recognition Challenge (CNSRC) is also held this year, which is based on the Chinese celebrity multi-genre dataset CN-Celeb. This year, our team participated in both speaker verification closed tracks in CNSRC 2022 and VoxSRC 2022, and achieved the 1st place and 3rd place respectively. In most system reports, the authors usually only provide a description of their systems but lack an effective analysis of their methods. In this paper, we will outline how to build a strong speaker verification challenge system and give a detailed analysis of each method compared with some other popular technical means.
Wespeaker: A Research and Production oriented Speaker Embedding Learning Toolkit
Nov 01, 2022Speaker modeling is essential for many related tasks, such as speaker recognition and speaker diarization. The dominant modeling approach is fixed-dimensional vector representation, i.e., speaker embedding. This paper introduces a research and production oriented speaker embedding learning toolkit, Wespeaker. Wespeaker contains the implementation of scalable data management, state-of-the-art speaker embedding models, loss functions, and scoring back-ends, with highly competitive results achieved by structured recipes which were adopted in the winning systems in several speaker verification challenges. The application to other downstream tasks such as speaker diarization is also exhibited in the related recipe. Moreover, CPU- and GPU-compatible deployment codes are integrated for production-oriented development. The toolkit is publicly available at https://github.com/wenet-e2e/wespeaker.
SJTU-AISPEECH System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022
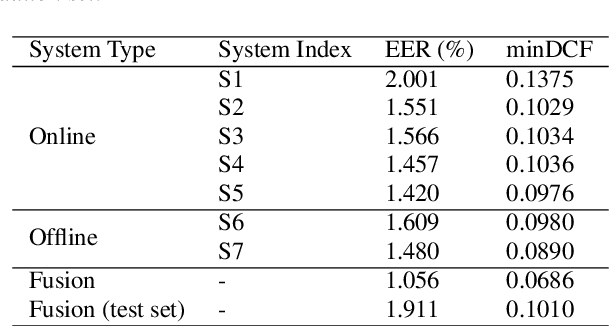

This report describes the SJTU-AISPEECH system for the Voxceleb Speaker Recognition Challenge 2022. For track1, we implemented two kinds of systems, the online system and the offline system. Different ResNet-based backbones and loss functions are explored. Our final fusion system achieved 3rd place in track1. For track3, we implemented statistic adaptation and jointly training based domain adaptation. In the jointly training based domain adaptation, we jointly trained the source and target domain dataset with different training objectives to do the domain adaptation. We explored two different training objectives for target domain data, self-supervised learning based angular proto-typical loss and semi-supervised learning based classification loss with estimated pseudo labels. Besides, we used the dynamic loss-gate and label correction (DLG-LC) strategy to improve the quality of pseudo labels when the target domain objective is a classification loss. Our final fusion system achieved 4th place (very close to 3rd place, relatively less than 1%) in track3.
AISPEECH-SJTU accent identification system for the Accented English Speech Recognition Challenge
Feb 19, 2021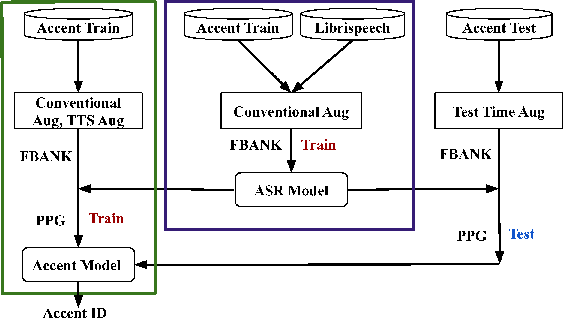
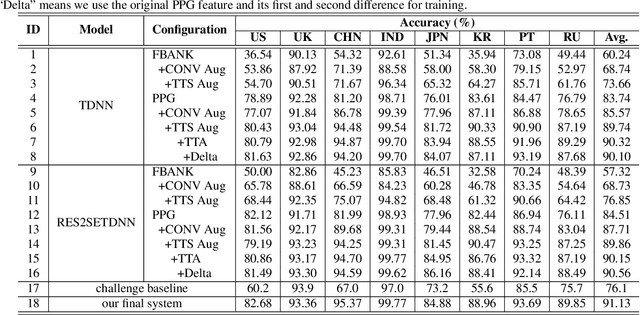
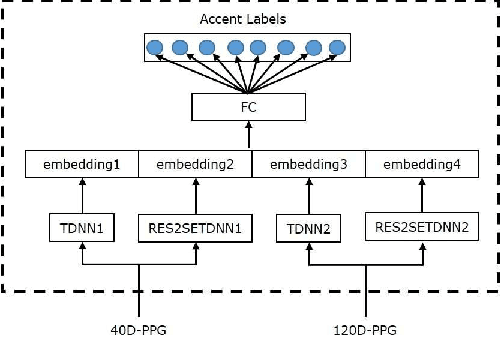
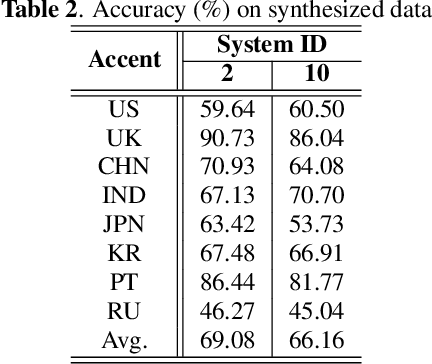
This paper describes the AISpeech-SJTU system for the accent identification track of the Interspeech-2020 Accented English Speech Recognition Challenge. In this challenge track, only 160-hour accented English data collected from 8 countries and the auxiliary Librispeech dataset are provided for training. To build an accurate and robust accent identification system, we explore the whole system pipeline in detail. First, we introduce the ASR based phone posteriorgram (PPG) feature to accent identification and verify its efficacy. Then, a novel TTS based approach is carefully designed to augment the very limited accent training data for the first time. Finally, we propose the test time augmentation and embedding fusion schemes to further improve the system performance. Our final system is ranked first in the challenge and outperforms all the other participants by a large margin. The submitted system achieves 83.63\% average accuracy on the challenge evaluation data, ahead of the others by more than 10\% in absolute terms.
Unit selection synthesis based data augmentation for fixed phrase speaker verification
Feb 19, 2021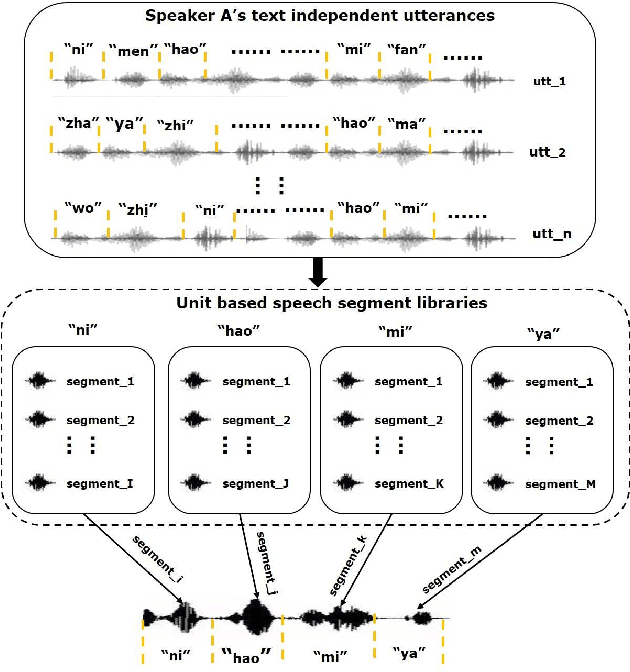
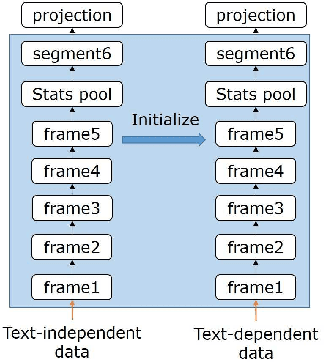
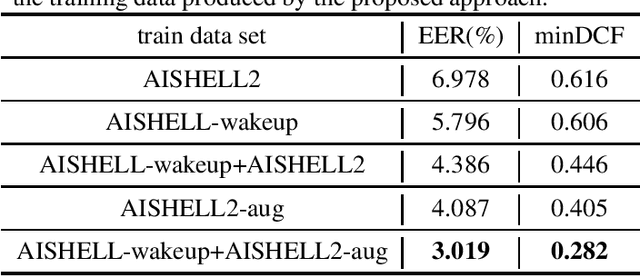
Data augmentation is commonly used to help build a robust speaker verification system, especially in limited-resource case. However, conventional data augmentation methods usually focus on the diversity of acoustic environment, leaving the lexicon variation neglected. For text dependent speaker verification tasks, it's well-known that preparing training data with the target transcript is the most effectual approach to build a well-performing system, however collecting such data is time-consuming and expensive. In this work, we propose a unit selection synthesis based data augmentation method to leverage the abundant text-independent data resources. In this approach text-independent speeches of each speaker are firstly broke up to speech segments each contains one phone unit. Then segments that contain phonetics in the target transcript are selected to produce a speech with the target transcript by concatenating them in turn. Experiments are carried out on the AISHELL Speaker Verification Challenge 2019 database, the results and analysis shows that our proposed method can boost the system performance significantly.
The xx205 System for the VoxCeleb Speaker Recognition Challenge 2020
Oct 31, 2020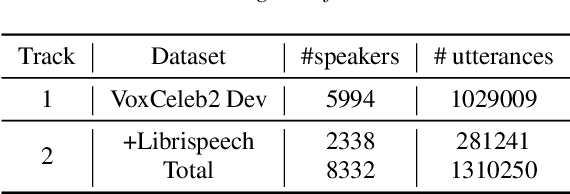
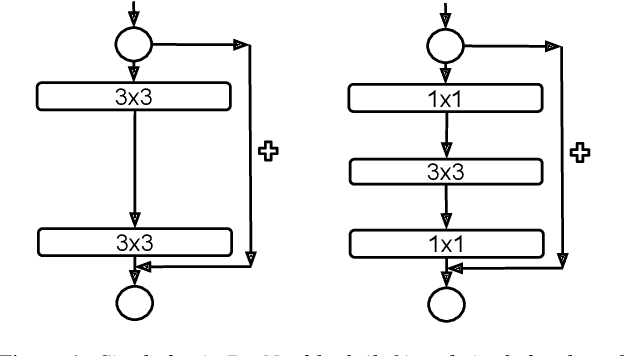

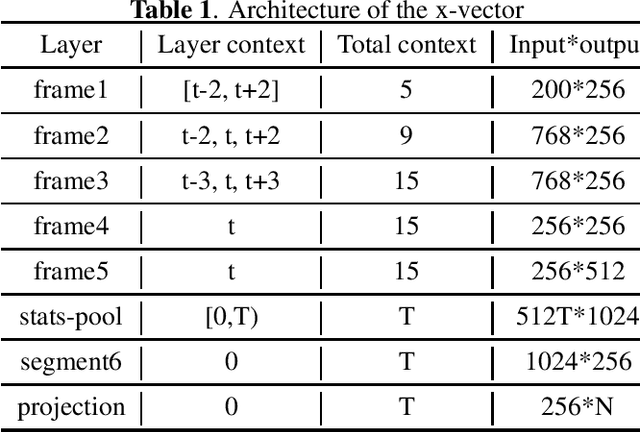
This report describes the systems submitted to the first and second tracks of the VoxCeleb Speaker Recognition Challenge (VoxSRC) 2020, which ranked second in both tracks. Three key points of the system pipeline are explored: (1) investigating multiple CNN architectures including ResNet, Res2Net and dual path network (DPN) to extract the x-vectors, (2) using a composite angular margin softmax loss to train the speaker models, and (3) applying score normalization and system fusion to boost the performance. Measured on the VoxSRC-20 Eval set, the best submitted systems achieve an EER of $3.808\%$ and a MinDCF of $0.1958$ in the close-condition track 1, and an EER of $3.798\%$ and a MinDCF of $0.1942$ in the open-condition track 2, respectively.
Margin Matters: Towards More Discriminative Deep Neural Network Embeddings for Speaker Recognition
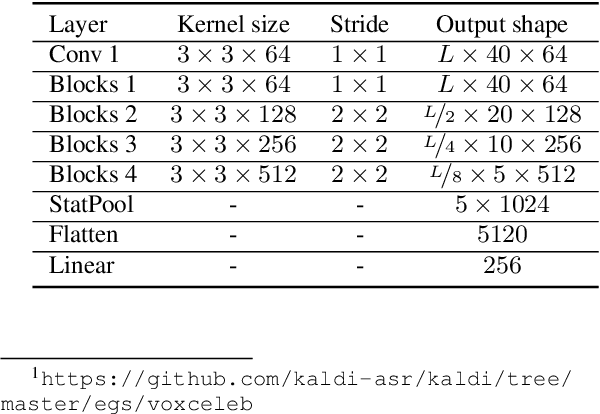
Jun 18, 2019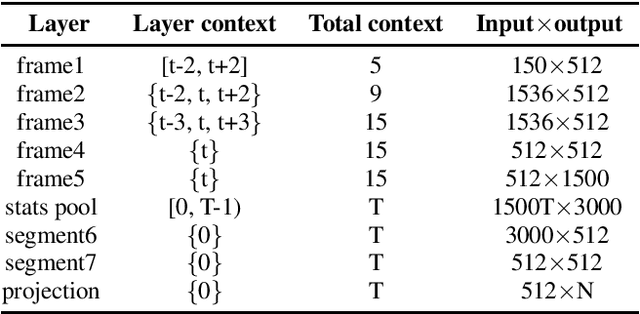
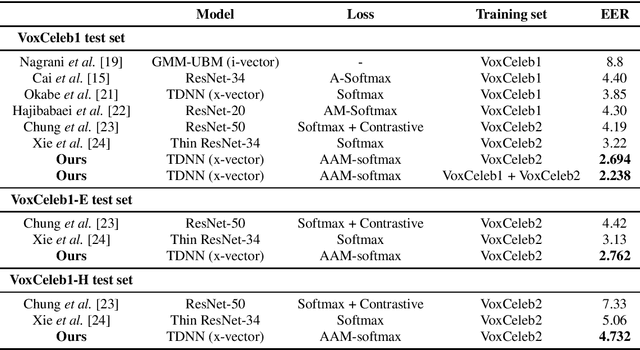
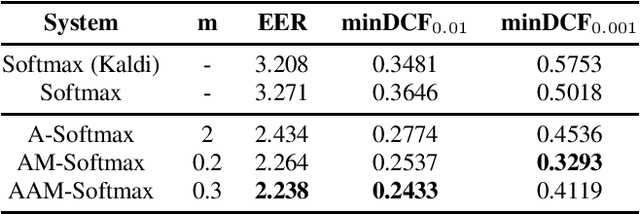
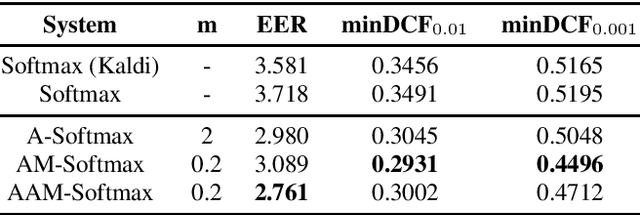
Recently, speaker embeddings extracted from a speaker discriminative deep neural network (DNN) yield better performance than the conventional methods such as i-vector. In most cases, the DNN speaker classifier is trained using cross entropy loss with softmax. However, this kind of loss function does not explicitly encourage inter-class separability and intra-class compactness. As a result, the embeddings are not optimal for speaker recognition tasks. In this paper, to address this issue, three different margin based losses which not only separate classes but also demand a fixed margin between classes are introduced to deep speaker embedding learning. It could be demonstrated that the margin is the key to obtain more discriminative speaker embeddings. Experiments are conducted on two public text independent tasks: VoxCeleb1 and Speaker in The Wild (SITW). The proposed approach can achieve the state-of-the-art performance, with 25% ~ 30% equal error rate (EER) reduction on both tasks when compared to strong baselines using cross entropy loss with softmax, obtaining 2.238% EER on VoxCeleb1 test set and 2.761% EER on SITW core-core test set, respectively.