 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Regularized Convolutional Audio Transformer for Audio Understanding
Jan 29, 2026Bootstrap-based Self-Supervised Learning (SSL) has achieved remarkable progress in audio understanding. However, existing methods typically operate at a single level of granularity, limiting their ability to model the diverse temporal and spectral structures inherent in complex audio signals. Furthermore, bootstrapping representations from scratch is computationally expensive, often requiring extensive training to converge. In this work, we propose the Convolutional Audio Transformer (CAT), a unified framework designed to address these challenges. First, to capture hierarchical audio features, CAT incorporates a Multi-resolution Block that aggregates information across varying granularities. Second, to enhance training efficiency, we introduce a Representation Regularization objective. Drawing inspiration from generative modeling, this auxiliary task guides the student model by aligning its predictions with high-quality semantic representations from frozen, pre-trained external encoders. Experimental results demonstrate that CAT significantly outperforms baselines on audio understanding benchmarks. Notably, it achieves competitive performance on the AudioSet 20k dataset with 5 times faster convergence than existing methods. Codes and checkpoints will be released soon at https://github.com/realzhouchushu/CAT.
TEFormer: Structured Bidirectional Temporal Enhancement Modeling in Spiking Transformers
Jan 26, 2026In recent years, Spiking Neural Networks (SNNs) have achieved remarkable progress, with Spiking Transformers emerging as a promising architecture for energy-efficient sequence modeling. However, existing Spiking Transformers still lack a principled mechanism for effective temporal fusion, limiting their ability to fully exploit spatiotemporal dependencies. Inspired by feedforward-feedback modulation in the human visual pathway, we propose TEFormer, the first Spiking Transformer framework that achieves bidirectional temporal fusion by decoupling temporal modeling across its core components. Specifically, TEFormer employs a lightweight and hyperparameter-free forward temporal fusion mechanism in the attention module, enabling fully parallel computation, while incorporating a backward gated recurrent structure in the MLP to aggregate temporal information in reverse order and reinforce temporal consistency. Extensive experiments across a wide range of benchmarks demonstrate that TEFormer consistently and significantly outperforms strong SNN and Spiking Transformer baselines under diverse datasets. Moreover, through the first systematic evaluation of Spiking Transformers under different neural encoding schemes, we show that the performance gains of TEFormer remain stable across encoding choices, indicating that the improved temporal modeling directly translates into reliable accuracy improvements across varied spiking representations. These results collectively establish TEFormer as an effective and general framework for temporal modeling in Spiking Transformers.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
Multi-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
TCM-5CEval: Extended Deep Evaluation Benchmark for LLM's Comprehensive Clinical Research Competence in Traditional Chinese Medicine
Nov 17, 2025Large language models (LLMs) have demonstrated exceptional capabilities in general domains, yet their application in highly specialized and culturally-rich fields like Traditional Chinese Medicine (TCM) requires rigorous and nuanced evaluation. Building upon prior foundational work such as TCM-3CEval, which highlighted systemic knowledge gaps and the importance of cultural-contextual alignment, we introduce TCM-5CEval, a more granular and comprehensive benchmark. TCM-5CEval is designed to assess LLMs across five critical dimensions: (1) Core Knowledge (TCM-Exam), (2) Classical Literacy (TCM-LitQA), (3) Clinical Decision-making (TCM-MRCD), (4) Chinese Materia Medica (TCM-CMM), and (5) Clinical Non-pharmacological Therapy (TCM-ClinNPT). We conducted a thorough evaluation of fifteen prominent LLMs, revealing significant performance disparities and identifying top-performing models like deepseek\_r1 and gemini\_2\_5\_pro. Our findings show that while models exhibit proficiency in recalling foundational knowledge, they struggle with the interpretative complexities of classical texts. Critically, permutation-based consistency testing reveals widespread fragilities in model inference. All evaluated models, including the highest-scoring ones, displayed a substantial performance degradation when faced with varied question option ordering, indicating a pervasive sensitivity to positional bias and a lack of robust understanding. TCM-5CEval not only provides a more detailed diagnostic tool for LLM capabilities in TCM but aldso exposes fundamental weaknesses in their reasoning stability. To promote further research and standardized comparison, TCM-5CEval has been uploaded to the Medbench platform, joining its predecessor in the "In-depth Challenge for Comprehensive TCM Abilities" special track.
Can Large Language Models Function as Qualified Pediatricians? A Systematic Evaluation in Real-World Clinical Contexts
Nov 17, 2025With the rapid rise of large language models (LLMs) in medicine, a key question is whether they can function as competent pediatricians in real-world clinical settings. We developed PEDIASBench, a systematic evaluation framework centered on a knowledge-system framework and tailored to realistic clinical environments. PEDIASBench assesses LLMs across three dimensions: application of basic knowledge, dynamic diagnosis and treatment capability, and pediatric medical safety and medical ethics. We evaluated 12 representative models released over the past two years, including GPT-4o, Qwen3-235B-A22B, and DeepSeek-V3, covering 19 pediatric subspecialties and 211 prototypical diseases. State-of-the-art models performed well on foundational knowledge, with Qwen3-235B-A22B achieving over 90% accuracy on licensing-level questions, but performance declined ~15% as task complexity increased, revealing limitations in complex reasoning. Multiple-choice assessments highlighted weaknesses in integrative reasoning and knowledge recall. In dynamic diagnosis and treatment scenarios, DeepSeek-R1 scored highest in case reasoning (mean 0.58), yet most models struggled to adapt to real-time patient changes. On pediatric medical ethics and safety tasks, Qwen2.5-72B performed best (accuracy 92.05%), though humanistic sensitivity remained limited. These findings indicate that pediatric LLMs are constrained by limited dynamic decision-making and underdeveloped humanistic care. Future development should focus on multimodal integration and a clinical feedback-model iteration loop to enhance safety, interpretability, and human-AI collaboration. While current LLMs cannot independently perform pediatric care, they hold promise for decision support, medical education, and patient communication, laying the groundwork for a safe, trustworthy, and collaborative intelligent pediatric healthcare system.
Towards Responsible Evaluation for Text-to-Speech
Oct 08, 2025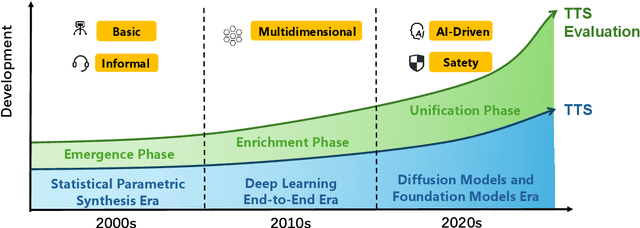


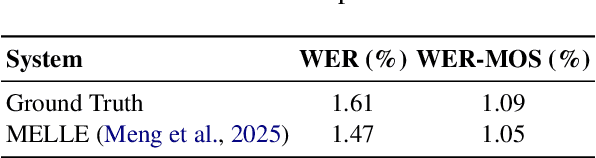
Recent advances in text-to-speech (TTS) technology have enabled systems to produce human-indistinguishable speech, bringing benefits across accessibility, content creation, and human-computer interaction. However, current evaluation practices are increasingly inadequate for capturing the full range of capabilities, limitations, and societal implications. This position paper introduces the concept of Responsible Evaluation and argues that it is essential and urgent for the next phase of TTS development, structured through three progressive levels: (1) ensuring the faithful and accurate reflection of a model's true capabilities, with more robust, discriminative, and comprehensive objective and subjective scoring methodologies; (2) enabling comparability, standardization, and transferability through standardized benchmarks, transparent reporting, and transferable evaluation metrics; and (3) assessing and mitigating ethical risks associated with forgery, misuse, privacy violations, and security vulnerabilities. Through this concept, we critically examine current evaluation practices, identify systemic shortcomings, and propose actionable recommendations. We hope this concept of Responsible Evaluation will foster more trustworthy and reliable TTS technology and guide its development toward ethically sound and societally beneficial applications.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025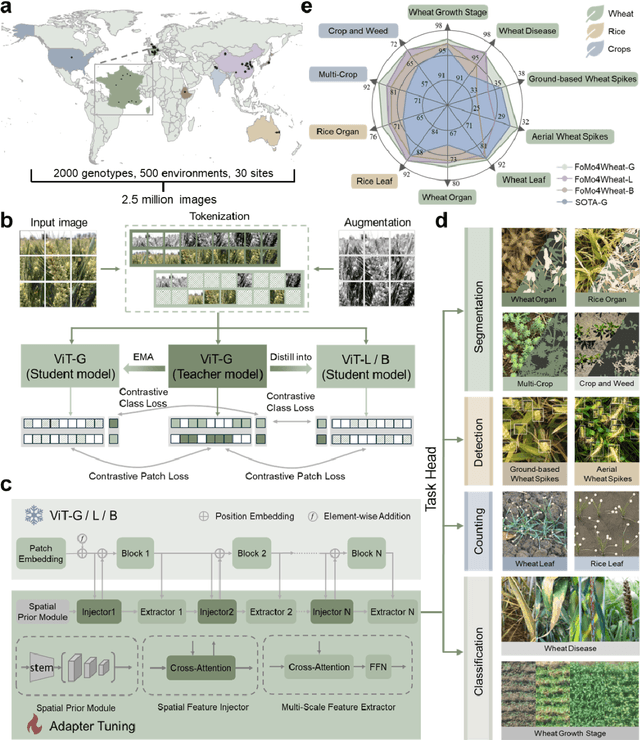

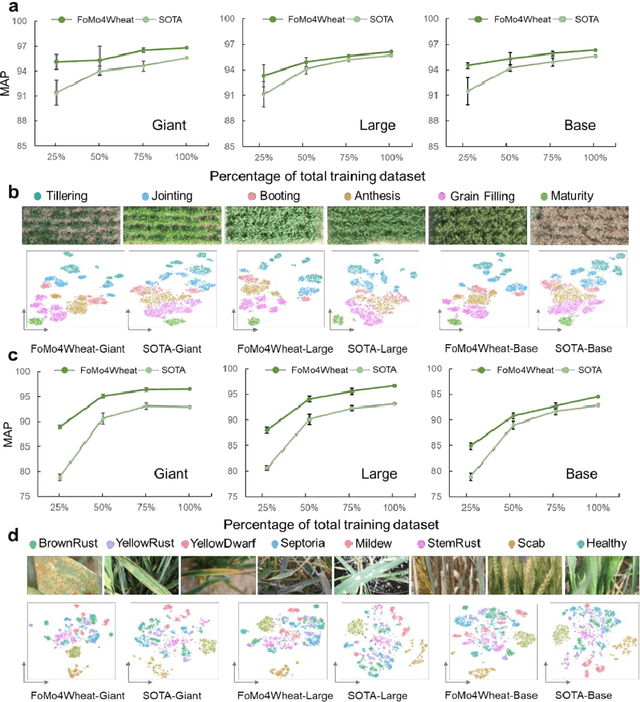
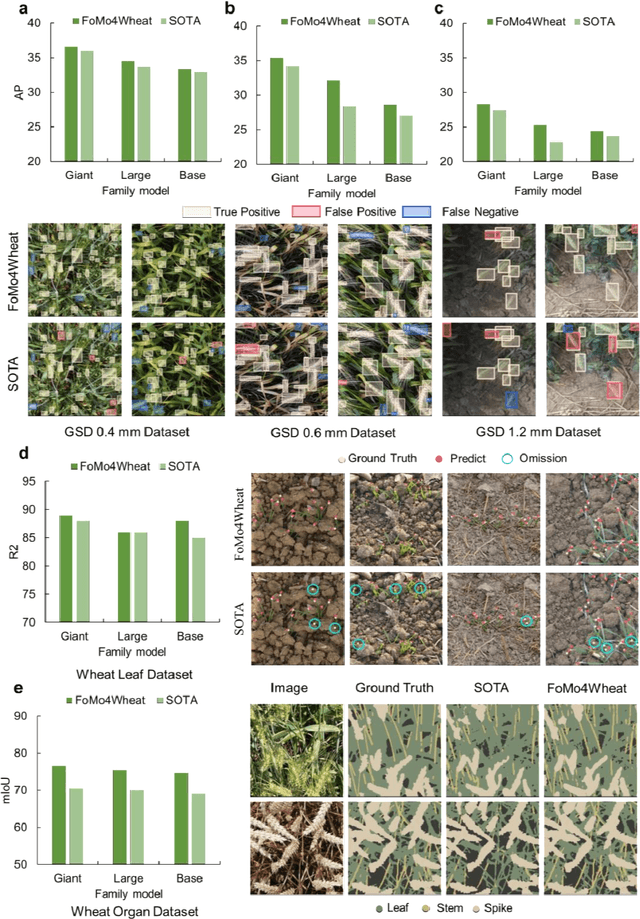
Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.
HyperDiff: Hypergraph Guided Diffusion Model for 3D Human Pose Estimation
Aug 20, 2025Monocular 3D human pose estimation (HPE) often encounters challenges such as depth ambiguity and occlusion during the 2D-to-3D lifting process. Additionally, traditional methods may overlook multi-scale skeleton features when utilizing skeleton structure information, which can negatively impact the accuracy of pose estimation. To address these challenges, this paper introduces a novel 3D pose estimation method, HyperDiff, which integrates diffusion models with HyperGCN. The diffusion model effectively captures data uncertainty, alleviating depth ambiguity and occlusion. Meanwhile, HyperGCN, serving as a denoiser, employs multi-granularity structures to accurately model high-order correlations between joints. This improves the model's denoising capability especially for complex poses. Experimental results demonstrate that HyperDiff achieves state-of-the-art performance on the Human3.6M and MPI-INF-3DHP datasets and can flexibly adapt to varying computational resources to balance performance and efficiency.