 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing VLAs in Task-Agnostic World Models
May 12, 2026Post-training Vision-Language-Action (VLA) models via reinforcement learning (RL) in learned world models has emerged as an effective strategy to adapt to new tasks without costly real-world interactions. However, while using imagined trajectories reduces the sample complexity of policy training, existing methods still heavily rely on task-specific data to fine-tune both the world and reward models, fundamentally limiting their scalability to unseen tasks. To overcome this, we argue that world and reward models should capture transferable physical priors that enable zero-shot inference. We propose RAW-Dream (Reinforcing VLAs in task-Agnostic World Dreams), a new paradigm that completely disentangles world model learning from downstream task dependencies. RAW-Dream utilizes a world model pre-trained on diverse task-free behaviors for predicting future rollouts, and an off-the-shelf Vision-Language Model (VLM) for reward generation. Because both components are task-agnostic, VLAs can be readily finetuned for any new task entirely within this zero-shot imagination. Furthermore, to mitigate world model hallucinations, we introduce a dual-noise verification mechanism to filter out unreliable rollouts. Extensive experiments across simulation and real-world settings demonstrate consistent performance gains, proving that generalized physical priors can effectively substitute for costly task-dependent data, offering a highly scalable roadmap for VLA adaptation.
Elucidating Representation Degradation Problem in Diffusion Model Training
May 11, 2026Diffusion models have achieved remarkable success, yet their training remains inefficient due to a severe optimization bottleneck, which we term Representation Degradation. As noise levels increase, the outputs of the trained model exhibit progressive structural distortion, which can destabilize training and impair generation quality. Our analysis suggests that this instability is driven by mismatched target recoverability, which is associated with Neural Tangent Kernel (NTK) spectral weakening and effective low-rank behavior. To address this, we propose Elucidated Representation Diffusion (ERD), a plug-and-play framework that dynamically reallocates optimization effort according to effective recoverability. By stabilizing representation learning without external supervision, ERD accelerates convergence and achieves strong empirical performance across diffusion backbones.
PT-RAG: Structure-Fidelity Retrieval-Augmented Generation for Academic Papers
Feb 14, 2026Retrieval-augmented generation (RAG) is increasingly applied to question-answering over long academic papers, where accurate evidence allocation under a fixed token budget is critical. Existing approaches typically flatten academic papers into unstructured chunks during preprocessing, which destroys the native hierarchical structure. This loss forces retrieval to operate in a disordered space, thereby producing fragmented contexts, misallocating tokens to non-evidential regions under finite token budgets, and increasing the reasoning burden for downstream language models. To address these issues, we propose PT-RAG, an RAG framework that treats the native hierarchical structure of academic papers as a low-entropy retrieval prior. PT-RAG first inherits the native hierarchy to construct a structure-fidelity PaperTree index, which prevents entropy increase at the source. It then designs a path-guided retrieval mechanism that aligns query semantics to relevant sections and selects high relevance root-to-leaf paths under a fixed token budget, yielding compact, coherent, and low-entropy retrieval contexts. In contrast to existing RAG approaches, PT-RAG avoids entropy increase caused by destructive preprocessing and provides a native low-entropy structural basis for subsequent retrieval. To assess this design, we introduce entropy-based structural diagnostics that quantify retrieval fragmentation and evidence allocation accuracy. On three academic question-answering benchmarks, PT-RAG achieves consistently lower section entropy and evidence alignment cross entropy than strong baselines, indicating reduced context fragmentation and more precise allocation to evidential regions. These structural advantages directly translate into higher answer quality.
Fourier-RWKV: A Multi-State Perception Network for Efficient Image Dehazing
Dec 09, 2025Image dehazing is crucial for reliable visual perception, yet it remains highly challenging under real-world non-uniform haze conditions. Although Transformer-based methods excel at capturing global context, their quadratic computational complexity hinders real-time deployment. To address this, we propose Fourier Receptance Weighted Key Value (Fourier-RWKV), a novel dehazing framework based on a Multi-State Perception paradigm. The model achieves comprehensive haze degradation modeling with linear complexity by synergistically integrating three distinct perceptual states: (1) Spatial-form Perception, realized through the Deformable Quad-directional Token Shift (DQ-Shift) operation, which dynamically adjusts receptive fields to accommodate local haze variations; (2) Frequency-domain Perception, implemented within the Fourier Mix block, which extends the core WKV attention mechanism of RWKV from the spatial domain to the Fourier domain, preserving the long-range dependencies essential for global haze estimation while mitigating spatial attenuation; (3) Semantic-relation Perception, facilitated by the Semantic Bridge Module (SBM), which utilizes Dynamic Semantic Kernel Fusion (DSK-Fusion) to precisely align encoder-decoder features and suppress artifacts. Extensive experiments on multiple benchmarks demonstrate that Fourier-RWKV delivers state-of-the-art performance across diverse haze scenarios while significantly reducing computational overhead, establishing a favorable trade-off between restoration quality and practical efficiency. Code is available at: https://github.com/Dilizlr/Fourier-RWKV.
Fairness-Aware Graph Representation Learning with Limited Demographic Information
Nov 18, 2025Ensuring fairness in Graph Neural Networks is fundamental to promoting trustworthy and socially responsible machine learning systems. In response, numerous fair graph learning methods have been proposed in recent years. However, most of them assume full access to demographic information, a requirement rarely met in practice due to privacy, legal, or regulatory restrictions. To this end, this paper introduces a novel fair graph learning framework that mitigates bias in graph learning under limited demographic information. Specifically, we propose a mechanism guided by partial demographic data to generate proxies for demographic information and design a strategy that enforces consistent node embeddings across demographic groups. In addition, we develop an adaptive confidence strategy that dynamically adjusts each node's contribution to fairness and utility based on prediction confidence. We further provide theoretical analysis demonstrating that our framework, FairGLite, achieves provable upper bounds on group fairness metrics, offering formal guarantees for bias mitigation. Through extensive experiments on multiple datasets and fair graph learning frameworks, we demonstrate the framework's effectiveness in both mitigating bias and maintaining model utility.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025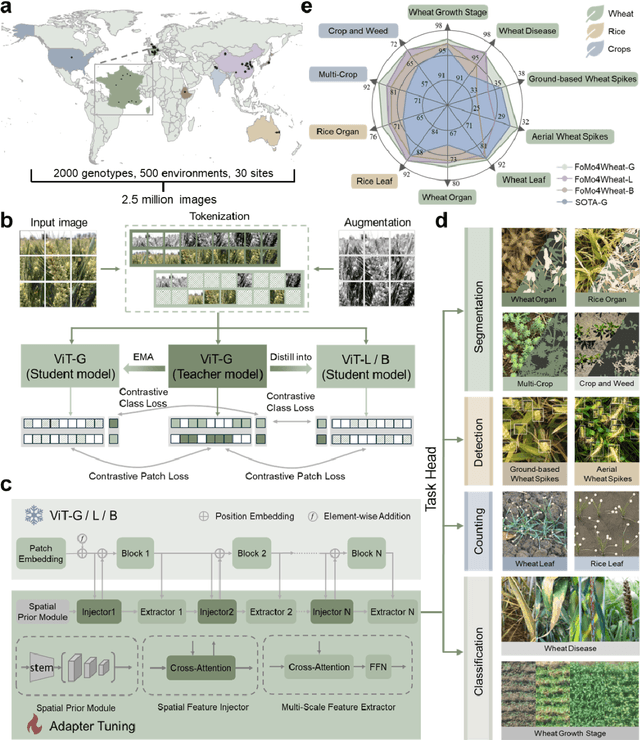

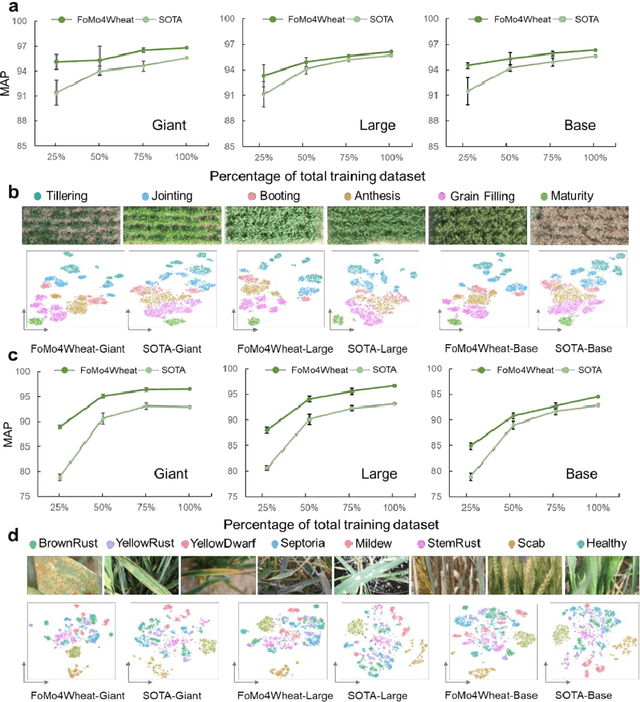
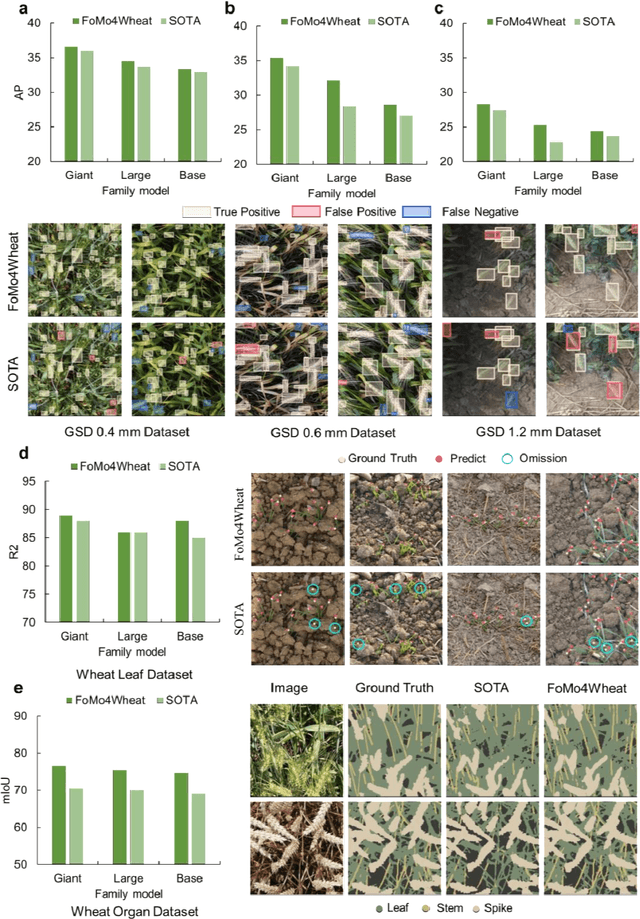
Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.
DistillDrive: End-to-End Multi-Mode Autonomous Driving Distillation by Isomorphic Hetero-Source Planning Model
Aug 07, 2025End-to-end autonomous driving has been recently seen rapid development, exerting a profound influence on both industry and academia. However, the existing work places excessive focus on ego-vehicle status as their sole learning objectives and lacks of planning-oriented understanding, which limits the robustness of the overall decision-making prcocess. In this work, we introduce DistillDrive, an end-to-end knowledge distillation-based autonomous driving model that leverages diversified instance imitation to enhance multi-mode motion feature learning. Specifically, we employ a planning model based on structured scene representations as the teacher model, leveraging its diversified planning instances as multi-objective learning targets for the end-to-end model. Moreover, we incorporate reinforcement learning to enhance the optimization of state-to-decision mappings, while utilizing generative modeling to construct planning-oriented instances, fostering intricate interactions within the latent space. We validate our model on the nuScenes and NAVSIM datasets, achieving a 50\% reduction in collision rate and a 3-point improvement in closed-loop performance compared to the baseline model. Code and model are publicly available at https://github.com/YuruiAI/DistillDrive
Reward Models in Deep Reinforcement Learning: A Survey
Jun 18, 2025In reinforcement learning (RL), agents continually interact with the environment and use the feedback to refine their behavior. To guide policy optimization, reward models are introduced as proxies of the desired objectives, such that when the agent maximizes the accumulated reward, it also fulfills the task designer's intentions. Recently, significant attention from both academic and industrial researchers has focused on developing reward models that not only align closely with the true objectives but also facilitate policy optimization. In this survey, we provide a comprehensive review of reward modeling techniques within the deep RL literature. We begin by outlining the background and preliminaries in reward modeling. Next, we present an overview of recent reward modeling approaches, categorizing them based on the source, the mechanism, and the learning paradigm. Building on this understanding, we discuss various applications of these reward modeling techniques and review methods for evaluating reward models. Finally, we conclude by highlighting promising research directions in reward modeling. Altogether, this survey includes both established and emerging methods, filling the vacancy of a systematic review of reward models in current literature.
JailBound: Jailbreaking Internal Safety Boundaries of Vision-Language Models
May 26, 2025Vision-Language Models (VLMs) exhibit impressive performance, yet the integration of powerful vision encoders has significantly broadened their attack surface, rendering them increasingly susceptible to jailbreak attacks. However, lacking well-defined attack objectives, existing jailbreak methods often struggle with gradient-based strategies prone to local optima and lacking precise directional guidance, and typically decouple visual and textual modalities, thereby limiting their effectiveness by neglecting crucial cross-modal interactions. Inspired by the Eliciting Latent Knowledge (ELK) framework, we posit that VLMs encode safety-relevant information within their internal fusion-layer representations, revealing an implicit safety decision boundary in the latent space. This motivates exploiting boundary to steer model behavior. Accordingly, we propose JailBound, a novel latent space jailbreak framework comprising two stages: (1) Safety Boundary Probing, which addresses the guidance issue by approximating decision boundary within fusion layer's latent space, thereby identifying optimal perturbation directions towards the target region; and (2) Safety Boundary Crossing, which overcomes the limitations of decoupled approaches by jointly optimizing adversarial perturbations across both image and text inputs. This latter stage employs an innovative mechanism to steer the model's internal state towards policy-violating outputs while maintaining cross-modal semantic consistency. Extensive experiments on six diverse VLMs demonstrate JailBound's efficacy, achieves 94.32% white-box and 67.28% black-box attack success averagely, which are 6.17% and 21.13% higher than SOTA methods, respectively. Our findings expose a overlooked safety risk in VLMs and highlight the urgent need for more robust defenses. Warning: This paper contains potentially sensitive, harmful and offensive content.
Computer-Aided Layout Generation for Building Design: A Review
Apr 13, 2025
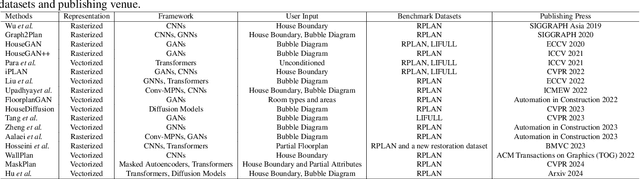
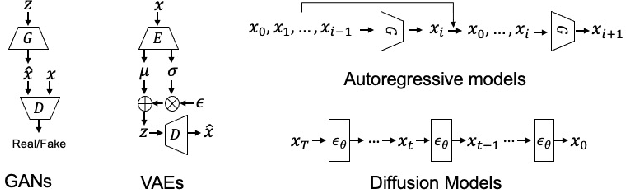

Generating realistic building layouts for automatic building design has been studied in both the computer vision and architecture domains. Traditional approaches from the architecture domain, which are based on optimization techniques or heuristic design guidelines, can synthesize desirable layouts, but usually require post-processing and involve human interaction in the design pipeline, making them costly and timeconsuming. The advent of deep generative models has significantly improved the fidelity and diversity of the generated architecture layouts, reducing the workload by designers and making the process much more efficient. In this paper, we conduct a comprehensive review of three major research topics of architecture layout design and generation: floorplan layout generation, scene layout synthesis, and generation of some other formats of building layouts. For each topic, we present an overview of the leading paradigms, categorized either by research domains (architecture or machine learning) or by user input conditions or constraints. We then introduce the commonly-adopted benchmark datasets that are used to verify the effectiveness of the methods, as well as the corresponding evaluation metrics. Finally, we identify the well-solved problems and limitations of existing approaches, then propose new perspectives as promising directions for future research in this important research area. A project associated with this survey to maintain the resources is available at awesome-building-layout-generation.