 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating Representation Degradation Problem in Diffusion Model Training
May 11, 2026Diffusion models have achieved remarkable success, yet their training remains inefficient due to a severe optimization bottleneck, which we term Representation Degradation. As noise levels increase, the outputs of the trained model exhibit progressive structural distortion, which can destabilize training and impair generation quality. Our analysis suggests that this instability is driven by mismatched target recoverability, which is associated with Neural Tangent Kernel (NTK) spectral weakening and effective low-rank behavior. To address this, we propose Elucidated Representation Diffusion (ERD), a plug-and-play framework that dynamically reallocates optimization effort according to effective recoverability. By stabilizing representation learning without external supervision, ERD accelerates convergence and achieves strong empirical performance across diffusion backbones.
LightGTS-Cov: Covariate-Enhanced Time Series Forecasting
Feb 11, 2026Time series foundation models are typically pre-trained on large, multi-source datasets; however, they often ignore exogenous covariates or incorporate them via simple concatenation with the target series, which limits their effectiveness in covariate-rich applications such as electricity price forecasting and renewable energy forecasting. We introduce LightGTS-Cov, a covariate-enhanced extension of LightGTS that preserves its lightweight, period-aware backbone while explicitly incorporating both past and future-known covariates. Built on a $\sim$1M-parameter LightGTS backbone, LightGTS-Cov adds only a $\sim$0.1M-parameter MLP plug-in that integrates time-aligned covariates into the target forecasts by residually refining the outputs of the decoding process. Across covariate-aware benchmarks on electricity price and energy generation datasets, LightGTS-Cov consistently outperforms LightGTS and achieves superior performance over other covariate-aware baselines under both settings, regardless of whether future-known covariates are provided. We further demonstrate its practical value in two real-world energy case applications: long-term photovoltaic power forecasting with future weather forecasts and day-ahead electricity price forecasting with weather and dispatch-plan covariates. Across both applications, LightGTS-Cov achieves strong forecasting accuracy and stable operational performance after deployment, validating its effectiveness in real-world industrial settings.
3D-Grounded Vision-Language Framework for Robotic Task Planning: Automated Prompt Synthesis and Supervised Reasoning
Feb 13, 2025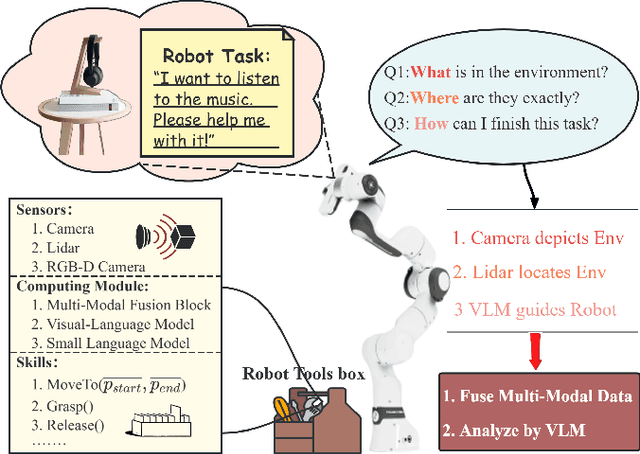
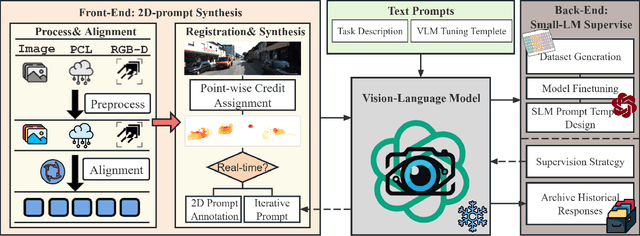
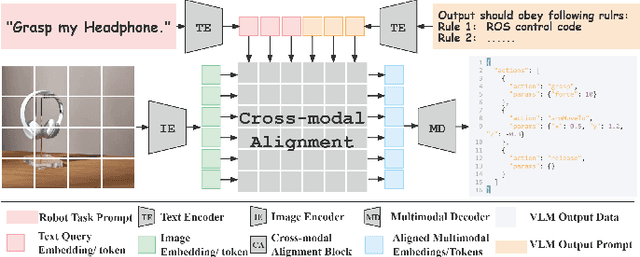
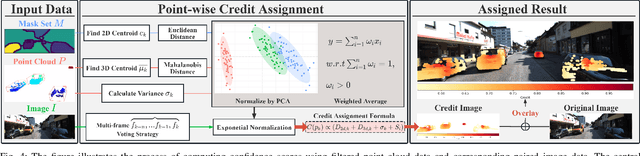
Vision-language models (VLMs) have achieved remarkable success in scene understanding and perception tasks, enabling robots to plan and execute actions adaptively in dynamic environments. However, most multimodal large language models lack robust 3D scene localization capabilities, limiting their effectiveness in fine-grained robotic operations. Additionally, challenges such as low recognition accuracy, inefficiency, poor transferability, and reliability hinder their use in precision tasks. To address these limitations, we propose a novel framework that integrates a 2D prompt synthesis module by mapping 2D images to point clouds, and incorporates a small language model (SLM) for supervising VLM outputs. The 2D prompt synthesis module enables VLMs, trained on 2D images and text, to autonomously extract precise 3D spatial information without manual intervention, significantly enhancing 3D scene understanding. Meanwhile, the SLM supervises VLM outputs, mitigating hallucinations and ensuring reliable, executable robotic control code generation. Our framework eliminates the need for retraining in new environments, thereby improving cost efficiency and operational robustness. Experimental results that the proposed framework achieved a 96.0\% Task Success Rate (TSR), outperforming other methods. Ablation studies demonstrated the critical role of both the 2D prompt synthesis module and the output supervision module (which, when removed, caused a 67\% TSR drop). These findings validate the framework's effectiveness in improving 3D recognition, task planning, and robotic task execution.
UDQL: Bridging The Gap between MSE Loss and The Optimal Value Function in Offline Reinforcement Learning
Jun 05, 2024


The Mean Square Error (MSE) is commonly utilized to estimate the solution of the optimal value function in the vast majority of offline reinforcement learning (RL) models and has achieved outstanding performance. However, we find that its principle can lead to overestimation phenomenon for the value function. In this paper, we first theoretically analyze overestimation phenomenon led by MSE and provide the theoretical upper bound of the overestimated error. Furthermore, to address it, we propose a novel Bellman underestimated operator to counteract overestimation phenomenon and then prove its contraction characteristics. At last, we propose the offline RL algorithm based on underestimated operator and diffusion policy model. Extensive experimental results on D4RL tasks show that our method can outperform state-of-the-art offline RL algorithms, which demonstrates that our theoretical analysis and underestimation way are effective for offline RL tasks.
Signal Processing Meets SGD: From Momentum to Filter
Nov 17, 2023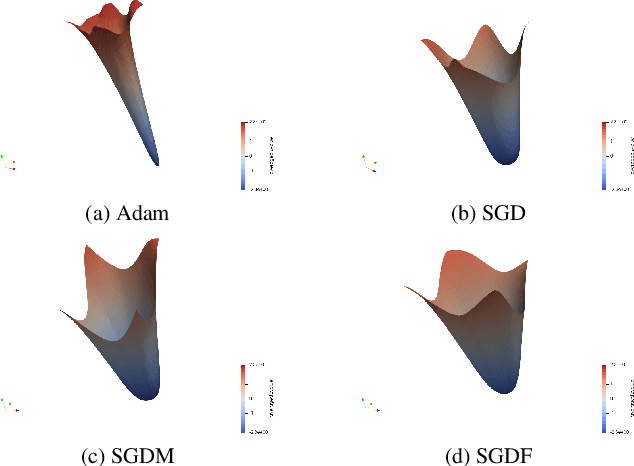


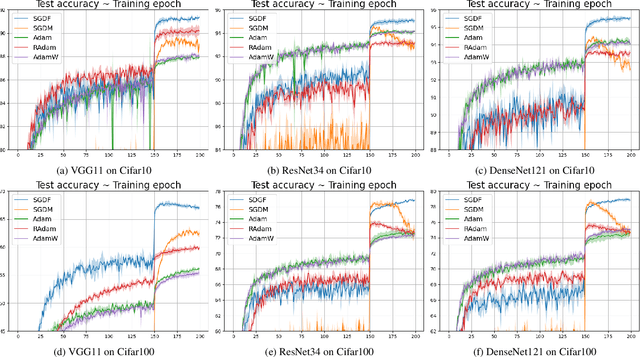
In the field of deep learning, Stochastic Gradient Descent (SGD) and its momentum-based variants are the predominant choices for optimization algorithms. Despite all that, these momentum strategies, which accumulate historical gradients by using a fixed $\beta$ hyperparameter to smooth the optimization processing, often neglect the potential impact of the variance of historical gradients on the current gradient estimation. In the gradient variance during training, fluctuation indicates the objective function does not meet the Lipschitz continuity condition at all time, which raises the troublesome optimization problem. This paper aims to explore the potential benefits of reducing the variance of historical gradients to make optimizer converge to flat solutions. Moreover, we proposed a new optimization method based on reducing the variance. We employed the Wiener filter theory to enhance the first moment estimation of SGD, notably introducing an adaptive weight to optimizer. Specifically, the adaptive weight dynamically changes along with temporal fluctuation of gradient variance during deep learning model training. Experimental results demonstrated our proposed adaptive weight optimizer, SGDF (Stochastic Gradient Descent With Filter), can achieve satisfactory performance compared with state-of-the-art optimizers.