 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiving, Reasoning, Adapting: A Dual-Layer Framework for VLM-Guided Precision Robotic Manipulation
Mar 07, 2025



Vision-Language Models (VLMs) demonstrate remarkable potential in robotic manipulation, yet challenges persist in executing complex fine manipulation tasks with high speed and precision. While excelling at high-level planning, existing VLM methods struggle to guide robots through precise sequences of fine motor actions. To address this limitation, we introduce a progressive VLM planning algorithm that empowers robots to perform fast, precise, and error-correctable fine manipulation. Our method decomposes complex tasks into sub-actions and maintains three key data structures: task memory structure, 2D topology graphs, and 3D spatial networks, achieving high-precision spatial-semantic fusion. These three components collectively accumulate and store critical information throughout task execution, providing rich context for our task-oriented VLM interaction mechanism. This enables VLMs to dynamically adjust guidance based on real-time feedback, generating precise action plans and facilitating step-wise error correction. Experimental validation on complex assembly tasks demonstrates that our algorithm effectively guides robots to rapidly and precisely accomplish fine manipulation in challenging scenarios, significantly advancing robot intelligence for precision tasks.
3D-Grounded Vision-Language Framework for Robotic Task Planning: Automated Prompt Synthesis and Supervised Reasoning
Feb 13, 2025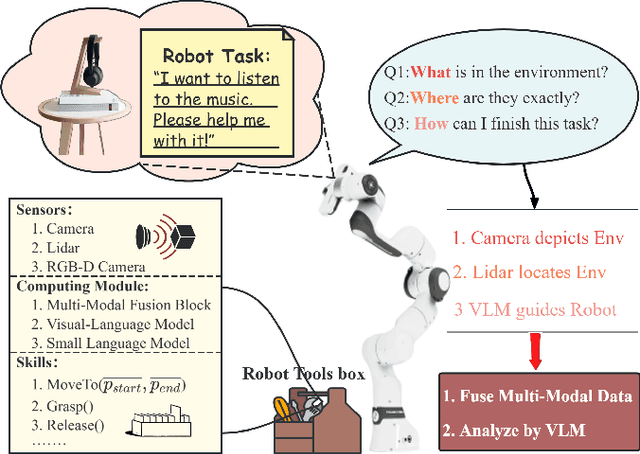
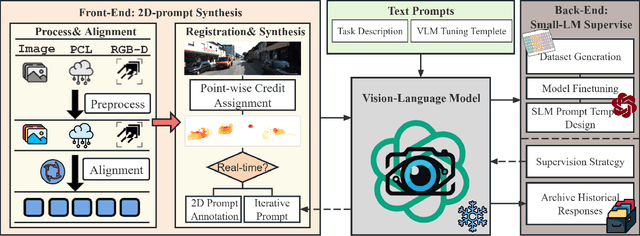
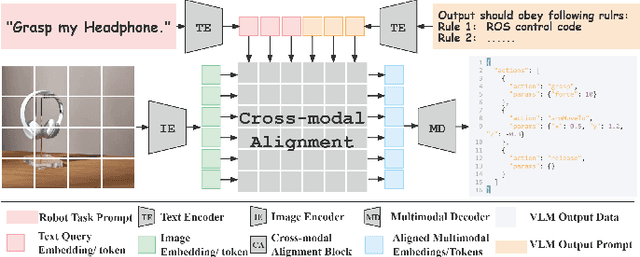
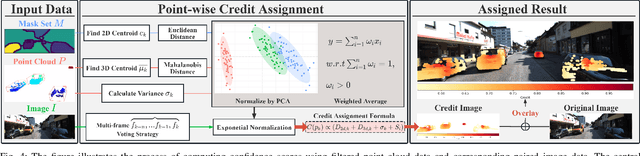
Vision-language models (VLMs) have achieved remarkable success in scene understanding and perception tasks, enabling robots to plan and execute actions adaptively in dynamic environments. However, most multimodal large language models lack robust 3D scene localization capabilities, limiting their effectiveness in fine-grained robotic operations. Additionally, challenges such as low recognition accuracy, inefficiency, poor transferability, and reliability hinder their use in precision tasks. To address these limitations, we propose a novel framework that integrates a 2D prompt synthesis module by mapping 2D images to point clouds, and incorporates a small language model (SLM) for supervising VLM outputs. The 2D prompt synthesis module enables VLMs, trained on 2D images and text, to autonomously extract precise 3D spatial information without manual intervention, significantly enhancing 3D scene understanding. Meanwhile, the SLM supervises VLM outputs, mitigating hallucinations and ensuring reliable, executable robotic control code generation. Our framework eliminates the need for retraining in new environments, thereby improving cost efficiency and operational robustness. Experimental results that the proposed framework achieved a 96.0\% Task Success Rate (TSR), outperforming other methods. Ablation studies demonstrated the critical role of both the 2D prompt synthesis module and the output supervision module (which, when removed, caused a 67\% TSR drop). These findings validate the framework's effectiveness in improving 3D recognition, task planning, and robotic task execution.