 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal Processing Meets SGD: From Momentum to Filter
Nov 17, 2023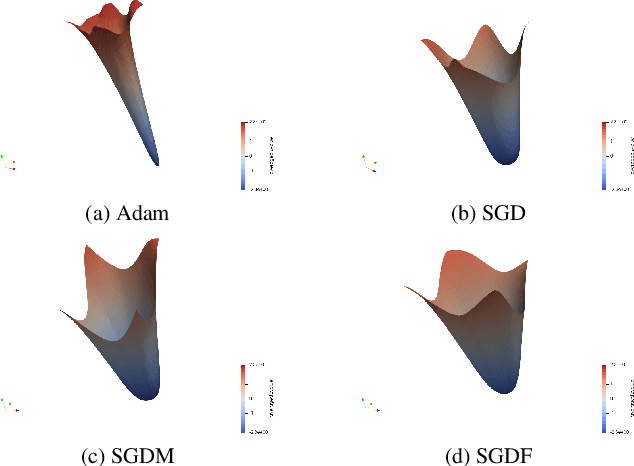


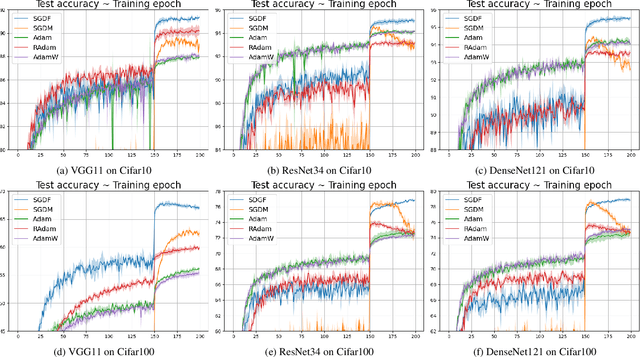
In the field of deep learning, Stochastic Gradient Descent (SGD) and its momentum-based variants are the predominant choices for optimization algorithms. Despite all that, these momentum strategies, which accumulate historical gradients by using a fixed $\beta$ hyperparameter to smooth the optimization processing, often neglect the potential impact of the variance of historical gradients on the current gradient estimation. In the gradient variance during training, fluctuation indicates the objective function does not meet the Lipschitz continuity condition at all time, which raises the troublesome optimization problem. This paper aims to explore the potential benefits of reducing the variance of historical gradients to make optimizer converge to flat solutions. Moreover, we proposed a new optimization method based on reducing the variance. We employed the Wiener filter theory to enhance the first moment estimation of SGD, notably introducing an adaptive weight to optimizer. Specifically, the adaptive weight dynamically changes along with temporal fluctuation of gradient variance during deep learning model training. Experimental results demonstrated our proposed adaptive weight optimizer, SGDF (Stochastic Gradient Descent With Filter), can achieve satisfactory performance compared with state-of-the-art optimizers.