 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Loop Bidirectional Prompting for Adversarial Robustness of Vision Language Models
May 25, 2026Vision Language Models adapt well to downstream tasks but are highly vulnerable to adversarial perturbations that disrupt cross-modal semantic alignment. Existing defenses are largely unidirectional or structural, failing to exploit bidirectional cross-modal complementarity and instance-wise adaptive protection. To overcome the limitations of unidirectional and static defenses in adversarial settings, we propose Closed-Loop Bidirectional Prompting, casting robust adaptation as cross-modal agreement recovery via a dynamic feedback loop on frozen encoders. A Semantic Anchor is introduced as a stable prior to constrain cyclic updates and mitigate perturbation-induced feature corruption. Through anchor-based bootstrapping, textual semantics denoise visual representations, while the refined visuals enable instance-adaptive prompt updating, yielding a rectified and robust consensus. Extensive evaluations across 11 datasets validate state-of-the-art robustness and strong base-to-new generalization, while maintaining a favorable trade-off between computational cost and accuracy.
Towards Controllable Low-Light Image Enhancement: A Continuous Multi-illumination Dataset and Efficient State Space Framework
Mar 26, 2026Low-light image enhancement (LLIE) has traditionally been formulated as a deterministic mapping. However, this paradigm often struggles to account for the ill-posed nature of the task, where unknown ambient conditions and sensor parameters create a multimodal solution space. Consequently, state-of-the-art methods frequently encounter luminance discrepancies between predictions and labels, often necessitating "gt-mean" post-processing to align output luminance for evaluation. To address this fundamental limitation, we propose a transition toward Controllable Low-light Enhancement (CLE), explicitly reformulating the task as a well-posed conditional problem. To this end, we introduce CLE-RWKV, a holistic framework supported by Light100, a new benchmark featuring continuous real-world illumination transitions. To resolve the conflict between luminance control and chromatic fidelity, a noise-decoupled supervision strategy in the HVI color space is employed, effectively separating illumination modulation from texture restoration. Architecturally, to adapt efficient State Space Models (SSMs) for dense prediction, we leverage a Space-to-Depth (S2D) strategy. By folding spatial neighborhoods into channel dimensions, this design allows the model to recover local inductive biases and effectively bridge the "scanning gap" inherent in flattened visual sequences without sacrificing linear complexity. Experiments across seven benchmarks demonstrate that our approach achieves competitive performance and robust controllability, providing a real-world multi-illumination alternative that significantly reduces the reliance on gt-mean post-processing.
UDQL: Bridging The Gap between MSE Loss and The Optimal Value Function in Offline Reinforcement Learning
Jun 05, 2024


The Mean Square Error (MSE) is commonly utilized to estimate the solution of the optimal value function in the vast majority of offline reinforcement learning (RL) models and has achieved outstanding performance. However, we find that its principle can lead to overestimation phenomenon for the value function. In this paper, we first theoretically analyze overestimation phenomenon led by MSE and provide the theoretical upper bound of the overestimated error. Furthermore, to address it, we propose a novel Bellman underestimated operator to counteract overestimation phenomenon and then prove its contraction characteristics. At last, we propose the offline RL algorithm based on underestimated operator and diffusion policy model. Extensive experimental results on D4RL tasks show that our method can outperform state-of-the-art offline RL algorithms, which demonstrates that our theoretical analysis and underestimation way are effective for offline RL tasks.
AKConv: Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters
Nov 26, 2023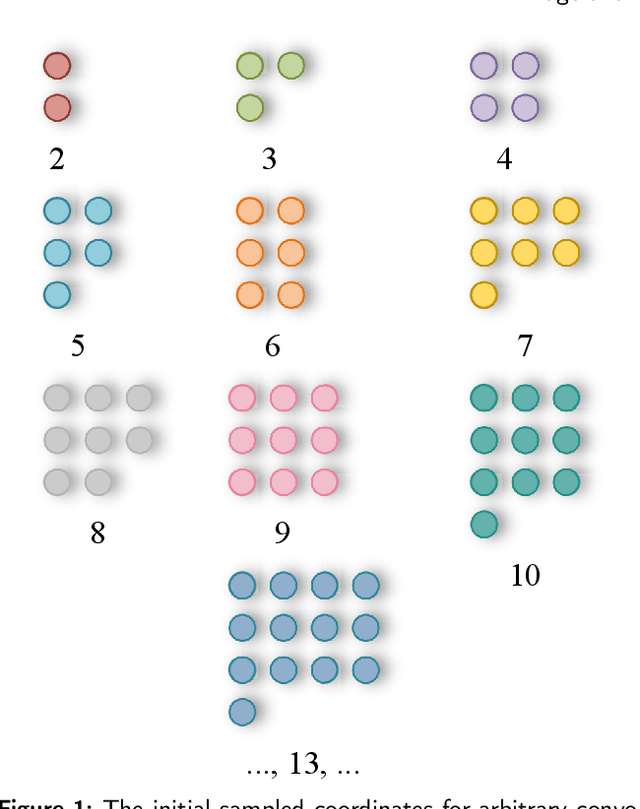



Neural networks based on convolutional operations have achieved remarkable results in the field of deep learning, but there are two inherent flaws in standard convolutional operations. On the one hand, the convolution operation be confined to a local window and cannot capture information from other locations, and its sampled shapes is fixed. On the other hand, the size of the convolutional kernel is fixed to k $\times$ k, which is a fixed square shape, and the number of parameters tends to grow squarely with size. It is obvious that the shape and size of targets are various in different datasets and at different locations. Convolutional kernels with fixed sample shapes and squares do not adapt well to changing targets. In response to the above questions, the Alterable Kernel Convolution (AKConv) is explored in this work, which gives the convolution kernel an arbitrary number of parameters and arbitrary sampled shapes to provide richer options for the trade-off between network overhead and performance. In AKConv, we define initial positions for convolutional kernels of arbitrary size by means of a new coordinate generation algorithm. To adapt to changes for targets, we introduce offsets to adjust the shape of the samples at each position. Moreover, we explore the effect of the neural network by using the AKConv with the same size and different initial sampled shapes. AKConv completes the process of efficient feature extraction by irregular convolutional operations and brings more exploration options for convolutional sampling shapes. Object detection experiments on representative datasets COCO2017, VOC 7+12 and VisDrone-DET2021 fully demonstrate the advantages of AKConv. AKConv can be used as a plug-and-play convolutional operation to replace convolutional operations to improve network performance. The code for the relevant tasks can be found at https://github.com/CV-ZhangXin/AKConv.
A Real-Time Multi-Task Learning System for Joint Detection of Face, Facial Landmark and Head Pose
Sep 21, 2023Extreme head postures pose a common challenge across a spectrum of facial analysis tasks, including face detection, facial landmark detection (FLD), and head pose estimation (HPE). These tasks are interdependent, where accurate FLD relies on robust face detection, and HPE is intricately associated with these key points. This paper focuses on the integration of these tasks, particularly when addressing the complexities posed by large-angle face poses. The primary contribution of this study is the proposal of a real-time multi-task detection system capable of simultaneously performing joint detection of faces, facial landmarks, and head poses. This system builds upon the widely adopted YOLOv8 detection framework. It extends the original object detection head by incorporating additional landmark regression head, enabling efficient localization of crucial facial landmarks. Furthermore, we conduct optimizations and enhancements on various modules within the original YOLOv8 framework. To validate the effectiveness and real-time performance of our proposed model, we conduct extensive experiments on 300W-LP and AFLW2000-3D datasets. The results obtained verify the capability of our model to tackle large-angle face pose challenges while delivering real-time performance across these interconnected tasks.
DeciLS-PBO: an Effective Local Search Method for Pseudo-Boolean Optimization
Jan 28, 2023Local search is an effective method for solving large-scale combinatorial optimization problems, and it has made remarkable progress in recent years through several subtle mechanisms. In this paper, we found two ways to improve the local search algorithms in solving Pseudo-Boolean Optimization(PBO): Firstly, some of those mechanisms such as unit propagation are merely used in solving MaxSAT before, which can be generalized to solve PBO as well; Secondly, the existing local search algorithms utilize the heuristic on variables, so-called score, to mainly guide the search. We attempt to gain more insights into the clause, as it plays the role of a middleman who builds a bridge between variables and the given formula. Hence, we first extended the combination of unit propagation-based decimation algorithm to PBO problem, giving a further generalized definition of unit clause for PBO problem, and apply it to the existing solver LS-PBO for constructing an initial assignment; then, we introduced a new heuristic on clauses, dubbed care, to set a higher priority for the clauses that are less satisfied in current iterations. Experiments on three real-world application benchmarks including minimum-width confidence band, wireless sensor network optimization, and seating arrangement problems show that our algorithm DeciLS-PBO has a promising performance compared to the state-of-the-art algorithms.
Densely Semantic Enhancement for Domain Adaptive Region-free Detectors
Aug 30, 2021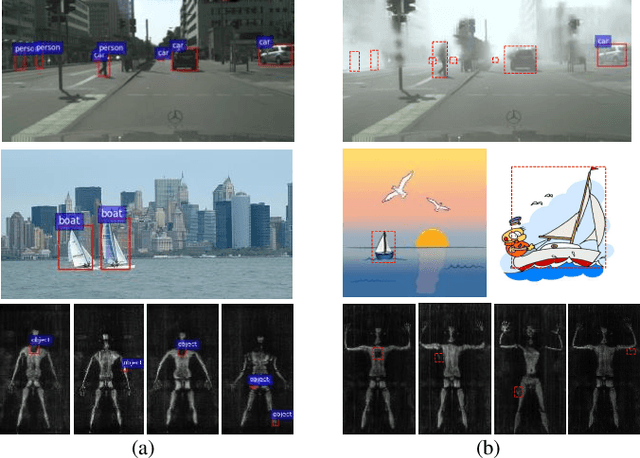

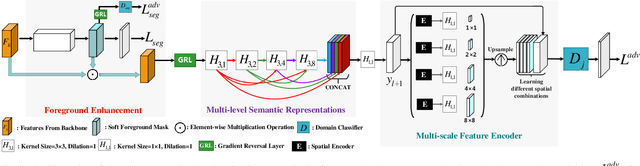
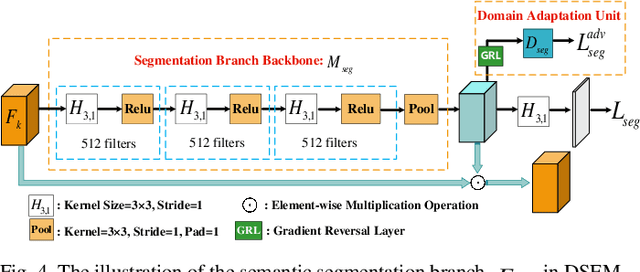
Unsupervised domain adaptive object detection aims to adapt a well-trained detector from its original source domain with rich labeled data to a new target domain with unlabeled data. Previous works focus on improving the domain adaptability of region-based detectors, e.g., Faster-RCNN, through matching cross-domain instance-level features that are explicitly extracted from a region proposal network (RPN). However, this is unsuitable for region-free detectors such as single shot detector (SSD), which perform a dense prediction from all possible locations in an image and do not have the RPN to encode such instance-level features. As a result, they fail to align important image regions and crucial instance-level features between the domains of region-free detectors. In this work, we propose an adversarial module to strengthen the cross-domain matching of instance-level features for region-free detectors. Firstly, to emphasize the important regions of image, the DSEM learns to predict a transferable foreground enhancement mask that can be utilized to suppress the background disturbance in an image. Secondly, considering that region-free detectors recognize objects of different scales using multi-scale feature maps, the DSEM encodes both multi-level semantic representations and multi-instance spatial-contextual relationships across different domains. Finally, the DSEM is pluggable into different region-free detectors, ultimately achieving the densely semantic feature matching via adversarial learning. Extensive experiments have been conducted on PASCAL VOC, Clipart, Comic, Watercolor, and FoggyCityscape benchmarks, and their results well demonstrate that the proposed approach not only improves the domain adaptability of region-free detectors but also outperforms existing domain adaptive region-based detectors under various domain shift settings.
A Granular Sieving Algorithm for Deterministic Global Optimization
Jul 14, 2021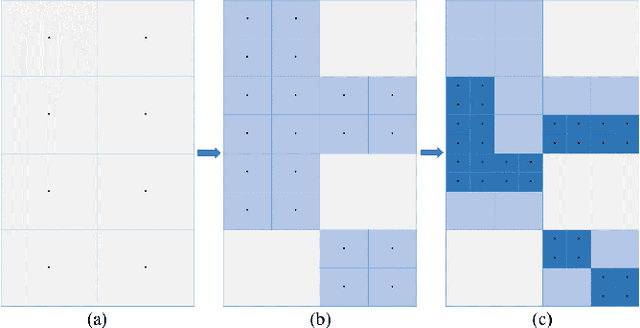

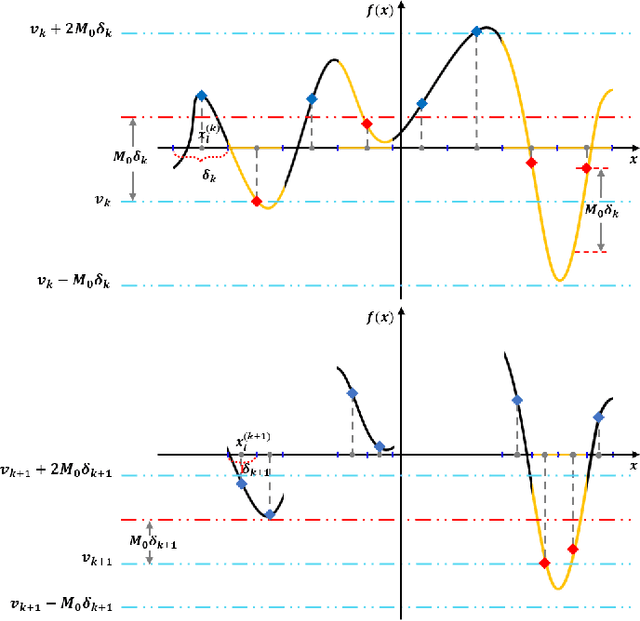
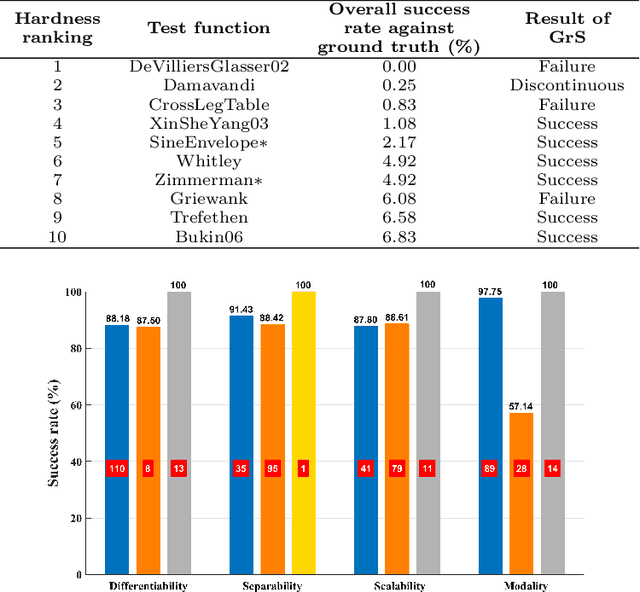
A gradient-free deterministic method is developed to solve global optimization problems for Lipschitz continuous functions defined in arbitrary path-wise connected compact sets in Euclidean spaces. The method can be regarded as granular sieving with synchronous analysis in both the domain and range of the objective function. With straightforward mathematical formulation applicable to both univariate and multivariate objective functions, the global minimum value and all the global minimizers are located through two decreasing sequences of compact sets in, respectively, the domain and range spaces. The algorithm is easy to implement with moderate computational cost. The method is tested against extensive benchmark functions in the literature. The experimental results show remarkable effectiveness and applicability of the algorithm.
Disentangled Dynamic Graph Deep Generation
Oct 14, 2020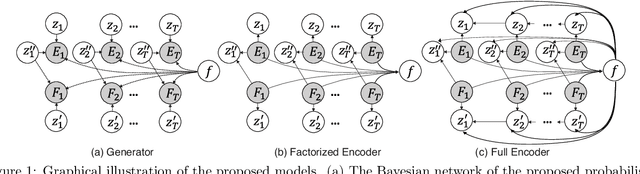
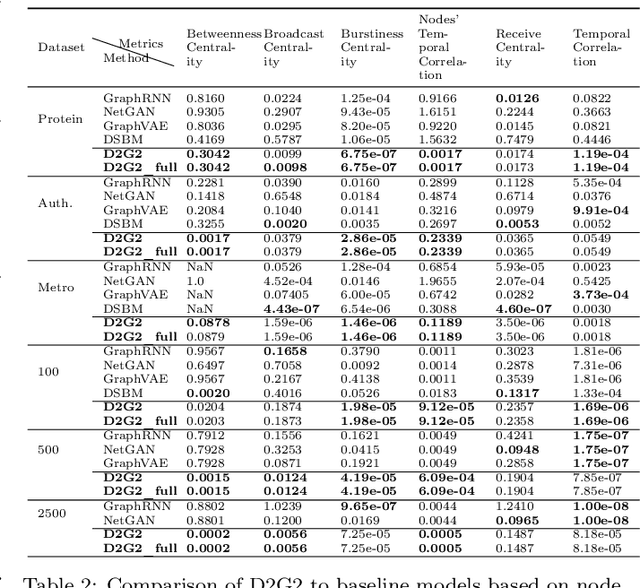
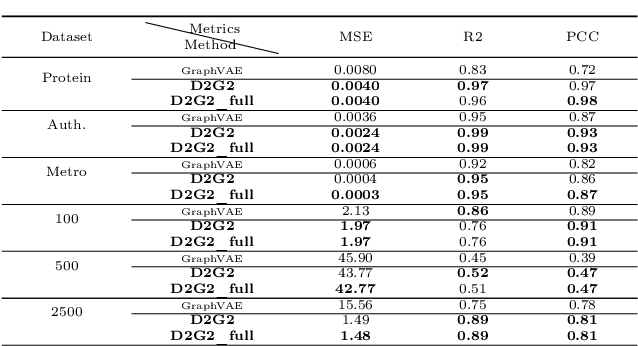
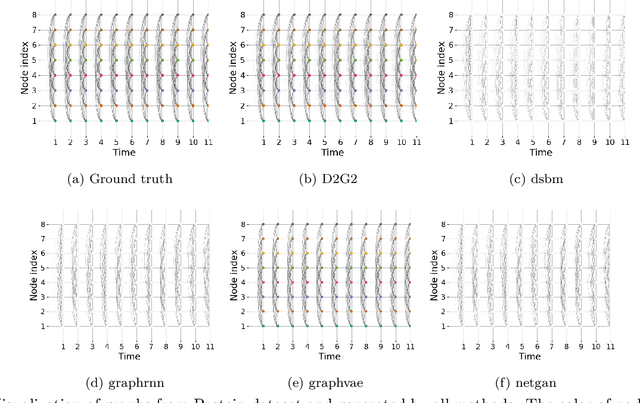
Deep generative models for graphs have exhibited promising performance in ever-increasing domains such as design of molecules (i.e, graph of atoms) and structure prediction of proteins (i.e., graph of amino acids). Existing work typically focuses on static rather than dynamic graphs, which are actually very important in the applications such as protein folding, molecule reactions, and human mobility. Extending existing deep generative models from static to dynamic graphs is a challenging task, which requires to handle the factorization of static and dynamic characteristics as well as mutual interactions among node and edge patterns. Here, this paper proposes a novel framework of factorized deep generative models to achieve interpretable dynamic graph generation. Various generative models are proposed to characterize conditional independence among node, edge, static, and dynamic factors. Then, variational optimization strategies as well as dynamic graph decoders are proposed based on newly designed factorized variational autoencoders and recurrent graph deconvolutions. Extensive experiments on multiple datasets demonstrate the effectiveness of the proposed models.
Factorized Deep Generative Models for Trajectory Generation with Spatiotemporal-Validity Constraints
Sep 20, 2020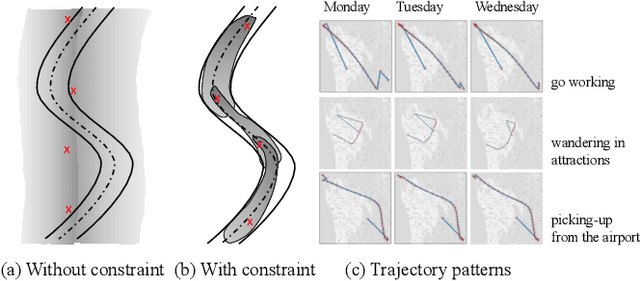
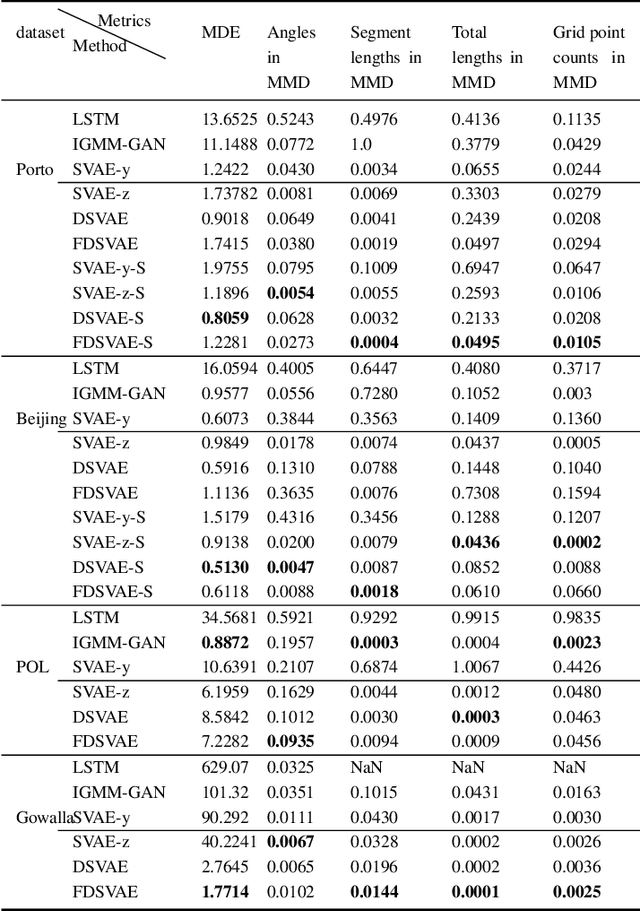
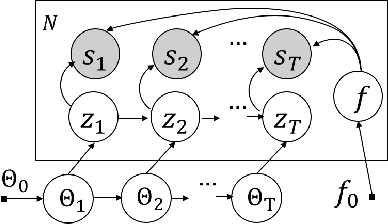
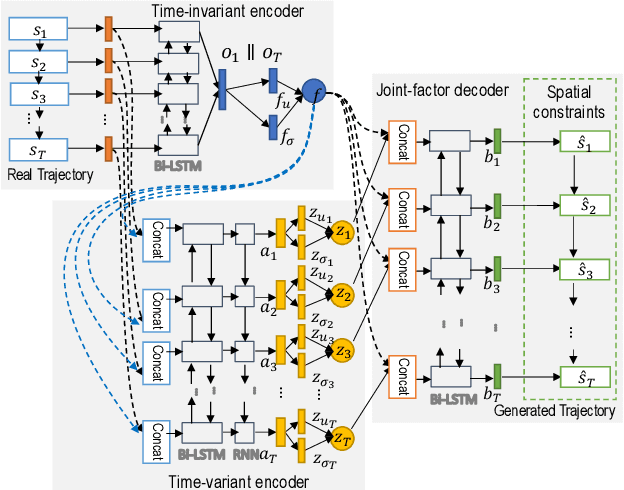
Trajectory data generation is an important domain that characterizes the generative process of mobility data. Traditional methods heavily rely on predefined heuristics and distributions and are weak in learning unknown mechanisms. Inspired by the success of deep generative neural networks for images and texts, a fast-developing research topic is deep generative models for trajectory data which can learn expressively explanatory models for sophisticated latent patterns. This is a nascent yet promising domain for many applications. We first propose novel deep generative models factorizing time-variant and time-invariant latent variables that characterize global and local semantics, respectively. We then develop new inference strategies based on variational inference and constrained optimization to encapsulate the spatiotemporal validity. New deep neural network architectures have been developed to implement the inference and generation models with newly-generalized latent variable priors. The proposed methods achieved significant improvements in quantitative and qualitative evaluations in extensive experiments.