 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Framework for Imputing Genetic Distances in Spatiotemporal Pathogen Models
Jun 10, 2025Pathogen genome data offers valuable structure for spatial models, but its utility is limited by incomplete sequencing coverage. We propose a probabilistic framework for inferring genetic distances between unsequenced cases and known sequences within defined transmission chains, using time-aware evolutionary distance modeling. The method estimates pairwise divergence from collection dates and observed genetic distances, enabling biologically plausible imputation grounded in observed divergence patterns, without requiring sequence alignment or known transmission chains. Applied to highly pathogenic avian influenza A/H5 cases in wild birds in the United States, this approach supports scalable, uncertainty-aware augmentation of genomic datasets and enhances the integration of evolutionary information into spatiotemporal modeling workflows.
Evaluating the Bias in LLMs for Surveying Opinion and Decision Making in Healthcare
Apr 11, 2025Generative agents have been increasingly used to simulate human behaviour in silico, driven by large language models (LLMs). These simulacra serve as sandboxes for studying human behaviour without compromising privacy or safety. However, it remains unclear whether such agents can truly represent real individuals. This work compares survey data from the Understanding America Study (UAS) on healthcare decision-making with simulated responses from generative agents. Using demographic-based prompt engineering, we create digital twins of survey respondents and analyse how well different LLMs reproduce real-world behaviours. Our findings show that some LLMs fail to reflect realistic decision-making, such as predicting universal vaccine acceptance. However, Llama 3 captures variations across race and Income more accurately but also introduces biases not present in the UAS data. This study highlights the potential of generative agents for behavioural research while underscoring the risks of bias from both LLMs and prompting strategies.
Chatting with Logs: An exploratory study on Finetuning LLMs for LogQL
Dec 04, 2024Logging is a critical function in modern distributed applications, but the lack of standardization in log query languages and formats creates significant challenges. Developers currently must write ad hoc queries in platform-specific languages, requiring expertise in both the query language and application-specific log details -- an impractical expectation given the variety of platforms and volume of logs and applications. While generating these queries with large language models (LLMs) seems intuitive, we show that current LLMs struggle with log-specific query generation due to the lack of exposure to domain-specific knowledge. We propose a novel natural language (NL) interface to address these inconsistencies and aide log query generation, enabling developers to create queries in a target log query language by providing NL inputs. We further introduce ~\textbf{NL2QL}, a manually annotated, real-world dataset of natural language questions paired with corresponding LogQL queries spread across three log formats, to promote the training and evaluation of NL-to-loq query systems. Using NL2QL, we subsequently fine-tune and evaluate several state of the art LLMs, and demonstrate their improved capability to generate accurate LogQL queries. We perform further ablation studies to demonstrate the effect of additional training data, and the transferability across different log formats. In our experiments, we find up to 75\% improvement of finetuned models to generate LogQL queries compared to non finetuned models.
Neural Collaborative Filtering to Detect Anomalies in Human Semantic Trajectories
Sep 27, 2024



Human trajectory anomaly detection has become increasingly important across a wide range of applications, including security surveillance and public health. However, existing trajectory anomaly detection methods are primarily focused on vehicle-level traffic, while human-level trajectory anomaly detection remains under-explored. Since human trajectory data is often very sparse, machine learning methods have become the preferred approach for identifying complex patterns. However, concerns regarding potential biases and the robustness of these models have intensified the demand for more transparent and explainable alternatives. In response to these challenges, our research focuses on developing a lightweight anomaly detection model specifically designed to detect anomalies in human trajectories. We propose a Neural Collaborative Filtering approach to model and predict normal mobility. Our method is designed to model users' daily patterns of life without requiring prior knowledge, thereby enhancing performance in scenarios where data is sparse or incomplete, such as in cold start situations. Our algorithm consists of two main modules. The first is the collaborative filtering module, which applies collaborative filtering to model normal mobility of individual humans to places of interest. The second is the neural module, responsible for interpreting the complex spatio-temporal relationships inherent in human trajectory data. To validate our approach, we conducted extensive experiments using simulated and real-world datasets comparing to numerous state-of-the-art trajectory anomaly detection approaches.
Kinematic Detection of Anomalies in Human Trajectory Data
Sep 27, 2024



Historically, much of the research in understanding, modeling, and mining human trajectory data has focused on where an individual stays. Thus, the focus of existing research has been on where a user goes. On the other hand, the study of how a user moves between locations has great potential for new research opportunities. Kinematic features describe how an individual moves between locations and can be used for tasks such as identification of individuals or anomaly detection. Unfortunately, data availability and quality challenges make kinematic trajectory mining difficult. In this paper, we leverage the Geolife dataset of human trajectories to investigate the viability of using kinematic features to identify individuals and detect anomalies. We show that humans have an individual "kinematic profile" which can be used as a strong signal to identify individual humans. We experimentally show that, for the two use-cases of individual identification and anomaly detection, simple kinematic features fed to standard classification and anomaly detection algorithms significantly improve results.
Transfer Learning via Latent Dependency Factor for Estimating PM 2.5
Apr 10, 2024Air pollution, especially particulate matter 2.5 (PM 2.5), is a pressing concern for public health and is difficult to estimate in developing countries (data-poor regions) due to a lack of ground sensors. Transfer learning models can be leveraged to solve this problem, as they use alternate data sources to gain knowledge (i.e., data from data-rich regions). However, current transfer learning methodologies do not account for dependencies between the source and the target domains. We recognize this transfer problem as spatial transfer learning and propose a new feature named Latent Dependency Factor (LDF) that captures spatial and semantic dependencies of both domains and is subsequently added to the datasets. We generate LDF using a novel two-stage autoencoder model that learns from clusters of similar source and target domain data. Our experiments show that transfer models using LDF have a $19.34\%$ improvement over the best-performing baselines. We additionally support our experiments with qualitative results.
Large Language Models for Spatial Trajectory Patterns Mining
Oct 07, 2023


Identifying anomalous human spatial trajectory patterns can indicate dynamic changes in mobility behavior with applications in domains like infectious disease monitoring and elderly care. Recent advancements in large language models (LLMs) have demonstrated their ability to reason in a manner akin to humans. This presents significant potential for analyzing temporal patterns in human mobility. In this paper, we conduct empirical studies to assess the capabilities of leading LLMs like GPT-4 and Claude-2 in detecting anomalous behaviors from mobility data, by comparing to specialized methods. Our key findings demonstrate that LLMs can attain reasonable anomaly detection performance even without any specific cues. In addition, providing contextual clues about potential irregularities could further enhances their prediction efficacy. Moreover, LLMs can provide reasonable explanations for their judgments, thereby improving transparency. Our work provides insights on the strengths and limitations of LLMs for human spatial trajectory analysis.
Riesz-Quincunx-UNet Variational Auto-Encoder for Satellite Image Denoising
Aug 25, 2022


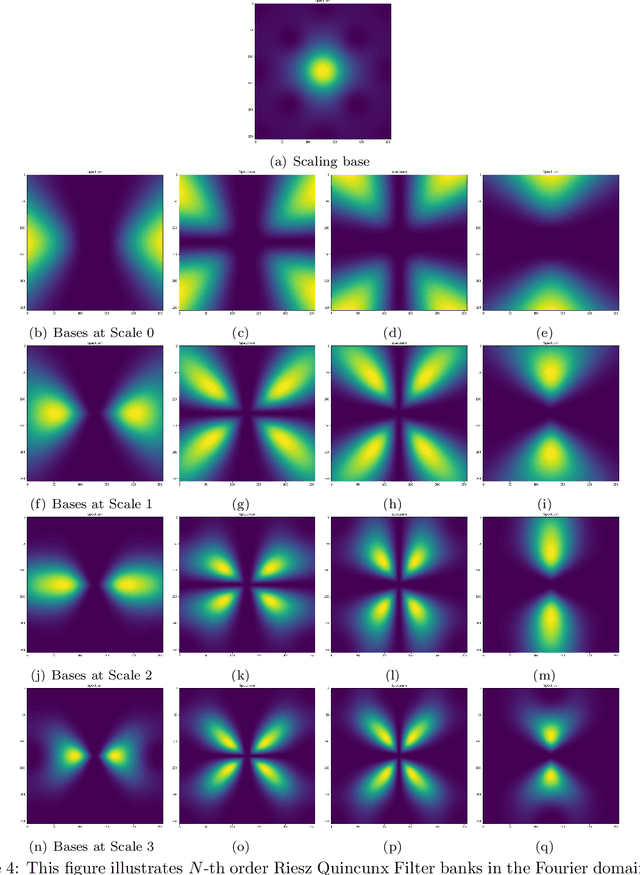
Multiresolution deep learning approaches, such as the U-Net architecture, have achieved high performance in classifying and segmenting images. However, these approaches do not provide a latent image representation and cannot be used to decompose, denoise, and reconstruct image data. The U-Net and other convolutional neural network (CNNs) architectures commonly use pooling to enlarge the receptive field, which usually results in irreversible information loss. This study proposes to include a Riesz-Quincunx (RQ) wavelet transform, which combines 1) higher-order Riesz wavelet transform and 2) orthogonal Quincunx wavelets (which have both been used to reduce blur in medical images) inside the U-net architecture, to reduce noise in satellite images and their time-series. In the transformed feature space, we propose a variational approach to understand how random perturbations of the features affect the image to further reduce noise. Combining both approaches, we introduce a hybrid RQUNet-VAE scheme for image and time series decomposition used to reduce noise in satellite imagery. We present qualitative and quantitative experimental results that demonstrate that our proposed RQUNet-VAE was more effective at reducing noise in satellite imagery compared to other state-of-the-art methods. We also apply our scheme to several applications for multi-band satellite images, including: image denoising, image and time-series decomposition by diffusion and image segmentation.
Change of human mobility during COVID-19: A United States case study
Sep 18, 2021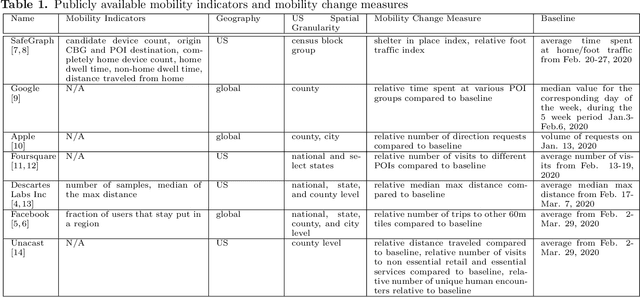
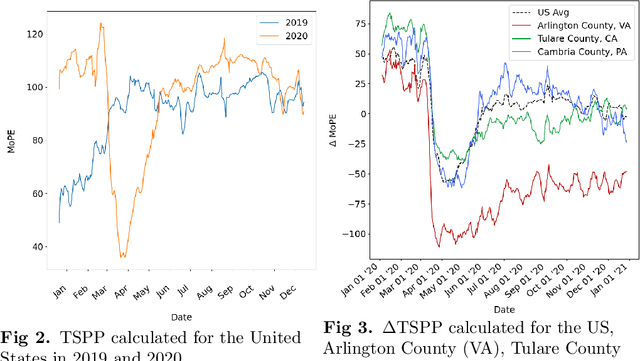
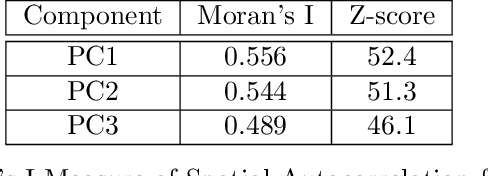
With the onset of COVID-19 and the resulting shelter in place guidelines combined with remote working practices, human mobility in 2020 has been dramatically impacted. Existing studies typically examine whether mobility in specific localities increases or decreases at specific points in time and relate these changes to certain pandemic and policy events. In this paper, we study mobility change in the US through a five-step process using mobility footprint data. (Step 1) Propose the delta Time Spent in Public Places (Delta-TSPP) as a measure to quantify daily changes in mobility for each US county from 2019-2020. (Step 2) Conduct Principal Component Analysis (PCA) to reduce the Delta-TSPP time series of each county to lower-dimensional latent components of change in mobility. (Step 3) Conduct clustering analysis to find counties that exhibit similar latent components. (Step 4) Investigate local and global spatial autocorrelation for each component. (Step 5) Conduct correlation analysis to investigate how various population characteristics and behavior correlate with mobility patterns. Results show that by describing each county as a linear combination of the three latent components, we can explain 59% of the variation in mobility trends across all US counties. Specifically, change in mobility in 2020 for US counties can be explained as a combination of three latent components: 1) long-term reduction in mobility, 2) no change in mobility, and 3) short-term reduction in mobility. We observe significant correlations between the three latent components of mobility change and various population characteristics, including political leaning, population, COVID-19 cases and deaths, and unemployment. We find that our analysis provides a comprehensive understanding of mobility change in response to the COVID-19 pandemic.
Station-to-User Transfer Learning: Towards Explainable User Clustering Through Latent Trip Signatures Using Tidal-Regularized Non-Negative Matrix Factorization
Apr 27, 2020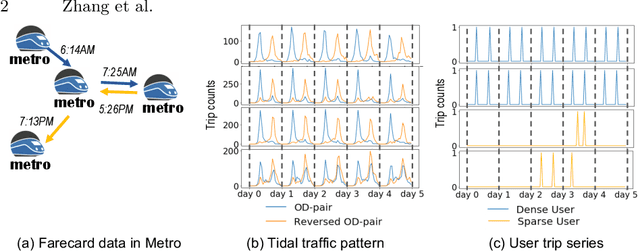

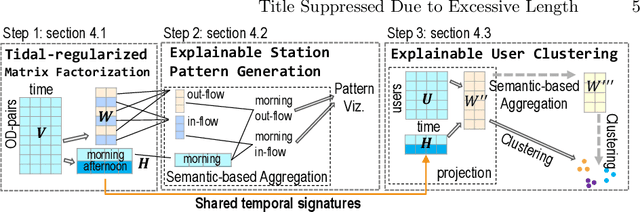
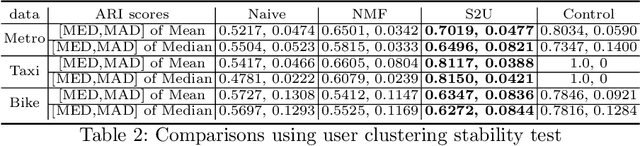
Urban areas provide us with a treasure trove of available data capturing almost every aspect of a population's life. This work focuses on mobility data and how it will help improve our understanding of urban mobility patterns. Readily available and sizable farecard data captures trips in a public transportation network. However, such data typically lacks temporal modalities and as such the task of inferring trip semantic, station function, and user profile is quite challenging. As existing approaches either focus on station-level or user-level signals, they are prone to overfitting and generate less credible and insightful results. To properly learn such characteristics from trip data, we propose a Collective Learning Framework through Latent Representation, which augments user-level learning with collective patterns learned from station-level signals. This framework uses a novel, so-called Tidal-Regularized Non-negative Matrix Factorization method, which incorporates domain knowledge in the form of temporal passenger flow patterns in generic Non-negative Matrix Factorization. To evaluate our model performance, a user stability test based on the classical Rand Index is introduced as a metric to benchmark different unsupervised learning models. We provide a qualitative analysis of the station functions and user profiles for the Washington D.C. metro and show how our method supports spatiotemporal intra-city mobility exploration.