 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Bias in LLMs for Surveying Opinion and Decision Making in Healthcare
Apr 11, 2025Generative agents have been increasingly used to simulate human behaviour in silico, driven by large language models (LLMs). These simulacra serve as sandboxes for studying human behaviour without compromising privacy or safety. However, it remains unclear whether such agents can truly represent real individuals. This work compares survey data from the Understanding America Study (UAS) on healthcare decision-making with simulated responses from generative agents. Using demographic-based prompt engineering, we create digital twins of survey respondents and analyse how well different LLMs reproduce real-world behaviours. Our findings show that some LLMs fail to reflect realistic decision-making, such as predicting universal vaccine acceptance. However, Llama 3 captures variations across race and Income more accurately but also introduces biases not present in the UAS data. This study highlights the potential of generative agents for behavioural research while underscoring the risks of bias from both LLMs and prompting strategies.
COMODO: Cross-Modal Video-to-IMU Distillation for Efficient Egocentric Human Activity Recognition
Mar 10, 2025Egocentric video-based models capture rich semantic information and have demonstrated strong performance in human activity recognition (HAR). However, their high power consumption, privacy concerns, and dependence on lighting conditions limit their feasibility for continuous on-device recognition. In contrast, inertial measurement unit (IMU) sensors offer an energy-efficient and privacy-preserving alternative, yet they suffer from limited large-scale annotated datasets, leading to weaker generalization in downstream tasks. To bridge this gap, we propose COMODO, a cross-modal self-supervised distillation framework that transfers rich semantic knowledge from the video modality to the IMU modality without requiring labeled annotations. COMODO leverages a pretrained and frozen video encoder to construct a dynamic instance queue, aligning the feature distributions of video and IMU embeddings. By distilling knowledge from video representations, our approach enables the IMU encoder to inherit rich semantic information from video while preserving its efficiency for real-world applications. Experiments on multiple egocentric HAR datasets demonstrate that COMODO consistently improves downstream classification performance, achieving results comparable to or exceeding fully supervised fine-tuned models. Moreover, COMODO exhibits strong cross-dataset generalization. Benefiting from its simplicity, our method is also generally applicable to various video and time-series pre-trained models, offering the potential to leverage more powerful teacher and student foundation models in future research. The code is available at https://github.com/Breezelled/COMODO .
WorkR: Occupation Inference for Intelligent Task Assistance
Jul 26, 2024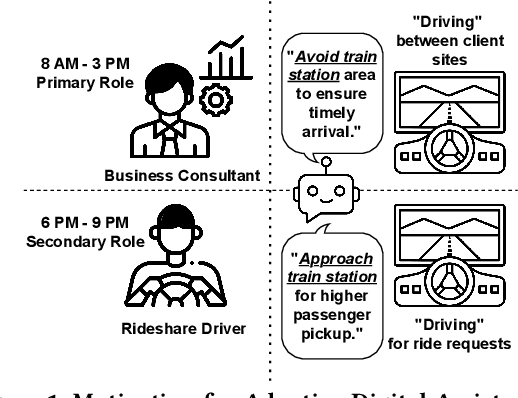


Occupation information can be utilized by digital assistants to provide occupation-specific personalized task support, including interruption management, task planning, and recommendations. Prior research in the digital workplace assistant domain requires users to input their occupation information for effective support. However, as many individuals switch between multiple occupations daily, current solutions falter without continuous user input. To address this, this study introduces WorkR, a framework that leverages passive sensing to capture pervasive signals from various task activities, addressing three challenges: the lack of a passive sensing architecture, personalization of occupation characteristics, and discovering latent relationships among occupation variables. We argue that signals from application usage, movements, social interactions, and the environment can inform a user's occupation. WorkR uses a Variational Autoencoder (VAE) to derive latent features for training models to infer occupations. Our experiments with an anonymized, context-rich activity and task log dataset demonstrate that our models can accurately infer occupations with more than 91% accuracy across six ISO occupation categories.
CAPRI-FAIR: Integration of Multi-sided Fairness in Contextual POI Recommendation Framework
Jun 05, 2024



Point-of-interest (POI) recommendation, a form of context-aware recommendation, takes into account spatio-temporal constraints and contexts like distance, peak business hours, and previous user check-ins. Given the ability of these kinds of systems to influence not just the consumer's travel experience, but also the POI's business, it is important to consider fairness from multiple perspectives. Unfortunately, these systems tend to provide less accurate recommendations to inactive users, and less exposure to unpopular POIs. The goal of this paper is to develop a post-filter methodology that incorporates provider and consumer fairness factors into pre-existing recommendation models, to satisfy fairness metrics like item exposure, and performance metrics like precision and distance, making the system more sustainable to both consumers and providers. Experiments have shown that using a linear scoring model for provider fairness in re-scoring recommended items yields the best tradeoff between performance and long-tail exposure, in some cases without a significant decrease in precision. When attempting to address consumer fairness by recommending more popular POIs to inactive users, the result was an increase in precision for only some recommendation models and datasets. Finally, when considering the tradeoff between both parameters, the combinations that reached the Pareto front of consumer and provider fairness, unfortunately, achieved the lowest precision values. We find that the nature of this tradeoff depends heavily on the model and the dataset.
ZzzGPT: An Interactive GPT Approach to Enhance Sleep Quality
Oct 24, 2023
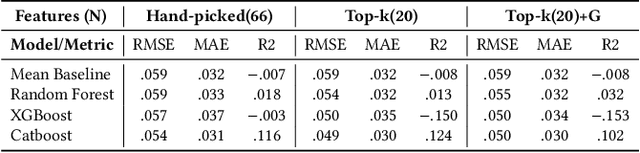
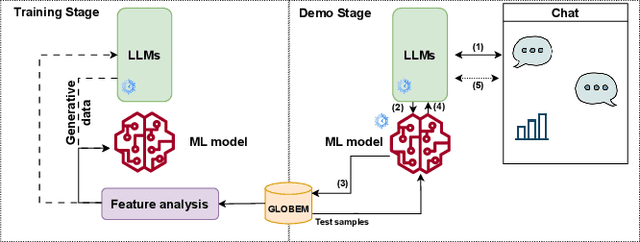
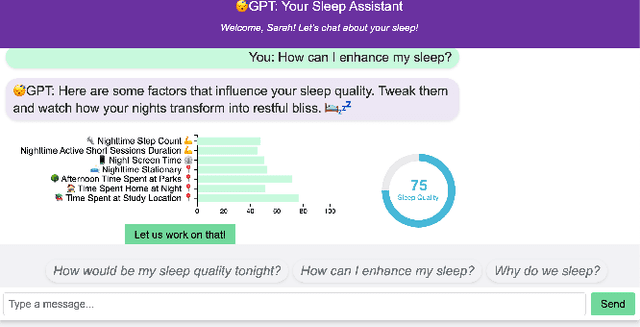
In today's world, sleep quality is pivotal for overall well-being. While wearable sensors offer real-time monitoring, they often lack actionable insights, leading to user abandonment. This paper delves into the role of technology in understanding sleep patterns. We introduce a two-stage framework, utilizing Large Language Models (LLMs), aiming to provide accurate sleep predictions with actionable feedback. Leveraging the GLOBEM dataset and synthetic data from LLMs, we highlight enhanced results with models like XGBoost. Our approach merges advanced machine learning with user-centric design, blending scientific accuracy with practicality.
MAPLE: Mobile App Prediction Leveraging Large Language model Embeddings
Sep 15, 2023Despite the rapid advancement of mobile applications, predicting app usage remains a formidable challenge due to intricate user behaviours and ever-evolving contexts. To address these issues, this paper introduces the Mobile App Prediction Leveraging Large Language Model Embeddings (MAPLE) model. This innovative approach utilizes Large Language Models (LLMs) to predict app usage accurately. Rigorous testing on two public datasets highlights MAPLE's capability to decipher intricate patterns and comprehend user contexts. These robust results confirm MAPLE's versatility and resilience across various scenarios. While its primary design caters to app prediction, the outcomes also emphasize the broader applicability of LLMs in different domains. Through this research, we emphasize the potential of LLMs in app usage prediction and suggest their transformative capacity in modelling human behaviours across diverse fields.
CoSEM: Contextual and Semantic Embedding for App Usage Prediction
Aug 26, 2021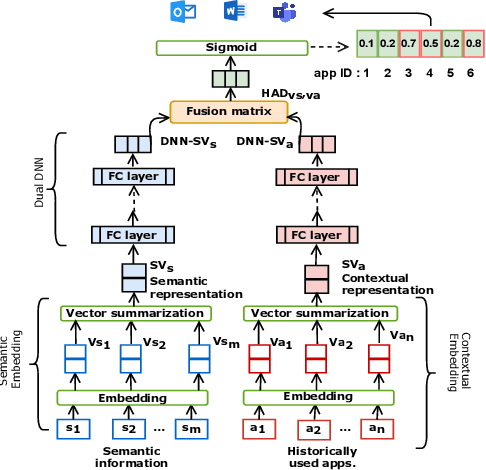
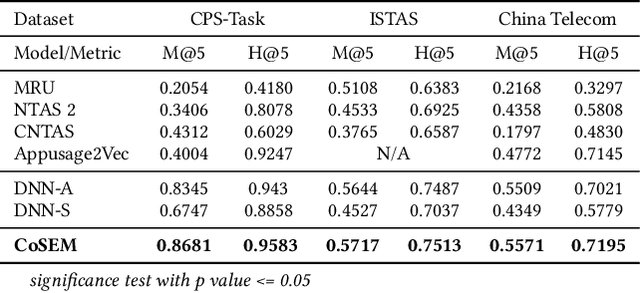
App usage prediction is important for smartphone system optimization to enhance user experience. Existing modeling approaches utilize historical app usage logs along with a wide range of semantic information to predict the app usage; however, they are only effective in certain scenarios and cannot be generalized across different situations. This paper address this problem by developing a model called Contextual and Semantic Embedding model for App Usage Prediction (CoSEM) for app usage prediction that leverages integration of 1) semantic information embedding and 2) contextual information embedding based on historical app usage of individuals. Extensive experiments show that the combination of semantic information and history app usage information enables our model to outperform the baselines on three real-world datasets, achieving an MRR score over 0.55,0.57,0.86 and Hit rate scores of more than 0.71, 0.75, and 0.95, respectively.