 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMo: Geometry-Aware Setup-Agnostic Modeling of Human Motion in the Wild
May 21, 2026As wearable and mobile devices become increasingly embedded in daily life, they offer a practical way to continuously sense human motion in the wild. But inertial signals are highly dependent on the sensing setup, including body location, mounting position, sensor orientation, device hardware, and sampling protocol. This setup dependence makes it difficult to learn motion representations that transfer across devices and datasets, and limits the broader use of wearable IMUs beyond closed-set recognition. We introduce AnyMo, a geometry-aware framework for setup-agnostic human motion modeling. AnyMo uses physics-grounded IMU simulation over dense body-surface placements to generate diverse and plausible synthetic signals, pre-trains a graph encoder from paired synthetic placement views and masked partial observations, tokenizes multi-position IMU into full-body motion tokens, and aligns these tokens with an LLM for motion-language understanding. We evaluate AnyMo on three complementary tasks: zero-shot activity recognition across 14 unseen downstream datasets, cross-modal retrieval, and wearable IMU motion captioning, where it improves average Accuracy/F1/R@2 by 11.7\%/11.6\%/22.6\% on HAR, increases zero-shot IMU-to-text and text-to-IMU retrieval MRR by 15.9\% and 28.6\%, respectively, and improves zero-shot captioning BERT-F1 by 18.8\%. These results support AnyMo as a generalist model for wearable motion understanding in the wild. Project page: https://baiyuchen.com/project/AnyMo.
TrajPrism: A Multi-Task Benchmark for Language-Grounded Urban Trajectory Understanding
May 11, 2026Urban mobility is naturally expressed both as trajectories in space and as natural-language descriptions of travel intent, constraints, and preferences. However, prior work rarely evaluates these two modalities together on the same real-world trajectories: trajectory modeling often stays geometry-centric, while language-centric mobility benchmarks frequently target route planning and tool use rather than fine-grained, verifiable alignment between text and the underlying route. We introduce TrajPrism, a multi-task benchmark for language-trajectory alignment that unifies (i) instruction-conditioned trajectory generation, (ii) language-driven semantic trajectory retrieval, and (iii) trajectory captioning, together with an evaluation protocol that measures trajectory fidelity, retrieval quality, and language groundedness. We construct TrajPrism by pairing real urban trajectories with judge-filtered language annotations generated under a four-dimensional travel-intent taxonomy. The benchmark contains 300K selected trajectories across Porto, San Francisco, and Beijing, yielding 2.1M task instances from three instruction variants, three retrieval queries, and one caption per trajectory. We further develop proof-of-concept models for each task: TrajAnchor for instruction-conditioned trajectory generation, TrajFuse for semantic trajectory retrieval, and TrajRap for trajectory captioning. These models instantiate the proposed tasks and show that geometry-only trajectory baselines leave a large gap on our protocol, especially where language is part of the input-output interface. We release TrajPrism with code and a reproducible annotation pipeline that is designed to be portable across cities, given compatible trajectory inputs and map resources.
TrajDLM: Topology-Aware Block Diffusion Language Model for Trajectory Generation
May 11, 2026Generating high-fidelity synthetic GPS trajectories is increasingly important for applications in transportation, urban planning, and what-if scenario simulation, especially as privacy concerns limit access to real-world mobility data. Existing trajectory generation models face a trade-off between efficiency and faithfulness to road network topology: continuous-space methods enable fast generation but ignore the road network, while topology-aware approaches rely on search-based autoregressive decoding that limits generation speed. We propose TrajDLM, a topology-aware trajectory generation framework based on block diffusion language models that bridges this gap. TrajDLM models trajectories as sequences of discrete road segments, combining a block diffusion backbone for efficient denoising, topology-aware embeddings from a road network encoder, and topology-constrained sampling to ensure coherent and realistic trajectories. Across three city-scale datasets, TrajDLM achieves strong performance on fine-grained local similarity metrics while being up to $2.8\times$ faster than prior work, and demonstrates strong zero-shot transfer across domains, including unseen transportation modes. These results highlight the effectiveness of block-wise discrete diffusion as a scalable approach to accurate and efficient trajectory generation. Our code is available at https://github.com/cruiseresearchgroup/TrajDLM/
Multi-Stage Verification-Centric Framework for Mitigating Hallucination in Multi-Modal RAG
Jul 27, 2025


This paper presents the technical solution developed by team CRUISE for the KDD Cup 2025 Meta Comprehensive RAG Benchmark for Multi-modal, Multi-turn (CRAG-MM) challenge. The challenge aims to address a critical limitation of modern Vision Language Models (VLMs): their propensity to hallucinate, especially when faced with egocentric imagery, long-tail entities, and complex, multi-hop questions. This issue is particularly problematic in real-world applications where users pose fact-seeking queries that demand high factual accuracy across diverse modalities. To tackle this, we propose a robust, multi-stage framework that prioritizes factual accuracy and truthfulness over completeness. Our solution integrates a lightweight query router for efficiency, a query-aware retrieval and summarization pipeline, a dual-pathways generation and a post-hoc verification. This conservative strategy is designed to minimize hallucinations, which incur a severe penalty in the competition's scoring metric. Our approach achieved 3rd place in Task 1, demonstrating the effectiveness of prioritizing answer reliability in complex multi-modal RAG systems. Our implementation is available at https://github.com/Breezelled/KDD-Cup-2025-Meta-CRAG-MM .
Massive-STEPS: Massive Semantic Trajectories for Understanding POI Check-ins -- Dataset and Benchmarks
May 19, 2025Understanding human mobility through Point-of-Interest (POI) recommendation is increasingly important for applications such as urban planning, personalized services, and generative agent simulation. However, progress in this field is hindered by two key challenges: the over-reliance on older datasets from 2012-2013 and the lack of reproducible, city-level check-in datasets that reflect diverse global regions. To address these gaps, we present Massive-STEPS (Massive Semantic Trajectories for Understanding POI Check-ins), a large-scale, publicly available benchmark dataset built upon the Semantic Trails dataset and enriched with semantic POI metadata. Massive-STEPS spans 12 geographically and culturally diverse cities and features more recent (2017-2018) and longer-duration (24 months) check-in data than prior datasets. We benchmarked a wide range of POI recommendation models on Massive-STEPS using both supervised and zero-shot approaches, and evaluated their performance across multiple urban contexts. By releasing Massive-STEPS, we aim to facilitate reproducible and equitable research in human mobility and POI recommendation. The dataset and benchmarking code are available at: https://github.com/cruiseresearchgroup/Massive-STEPS
COMODO: Cross-Modal Video-to-IMU Distillation for Efficient Egocentric Human Activity Recognition
Mar 10, 2025Egocentric video-based models capture rich semantic information and have demonstrated strong performance in human activity recognition (HAR). However, their high power consumption, privacy concerns, and dependence on lighting conditions limit their feasibility for continuous on-device recognition. In contrast, inertial measurement unit (IMU) sensors offer an energy-efficient and privacy-preserving alternative, yet they suffer from limited large-scale annotated datasets, leading to weaker generalization in downstream tasks. To bridge this gap, we propose COMODO, a cross-modal self-supervised distillation framework that transfers rich semantic knowledge from the video modality to the IMU modality without requiring labeled annotations. COMODO leverages a pretrained and frozen video encoder to construct a dynamic instance queue, aligning the feature distributions of video and IMU embeddings. By distilling knowledge from video representations, our approach enables the IMU encoder to inherit rich semantic information from video while preserving its efficiency for real-world applications. Experiments on multiple egocentric HAR datasets demonstrate that COMODO consistently improves downstream classification performance, achieving results comparable to or exceeding fully supervised fine-tuned models. Moreover, COMODO exhibits strong cross-dataset generalization. Benefiting from its simplicity, our method is also generally applicable to various video and time-series pre-trained models, offering the potential to leverage more powerful teacher and student foundation models in future research. The code is available at https://github.com/Breezelled/COMODO .
GenUP: Generative User Profilers as In-Context Learners for Next POI Recommender Systems
Oct 28, 2024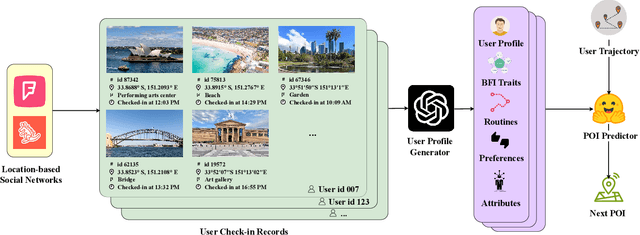


Traditional POI recommendation systems often lack transparency, interpretability, and scrutability due to their reliance on dense vector-based user embeddings. Furthermore, the cold-start problem -- where systems have insufficient data for new users -- limits their ability to generate accurate recommendations. Existing methods often address this by leveraging similar trajectories from other users, but this approach can be computationally expensive and increases the context length for LLM-based methods, making them difficult to scale. To address these limitations, we propose a method that generates natural language (NL) user profiles from large-scale, location-based social network (LBSN) check-ins, utilizing robust personality assessments and behavioral theories. These NL profiles capture user preferences, routines, and behaviors, improving POI prediction accuracy while offering enhanced transparency. By incorporating NL profiles as system prompts to LLMs, our approach reduces reliance on extensive historical data, while remaining flexible, easily updated, and computationally efficient. Our method is not only competitive with other LLM-based and complex agentic frameworks but is also more scalable for real-world scenarios and on-device POI recommendations. Results demonstrate that our approach consistently outperforms baseline methods, offering a more interpretable and resource-efficient solution for POI recommendation systems. Our source code is available at: \url{https://github.com/w11wo/GenUP}.
NusaBERT: Teaching IndoBERT to be Multilingual and Multicultural
Mar 04, 2024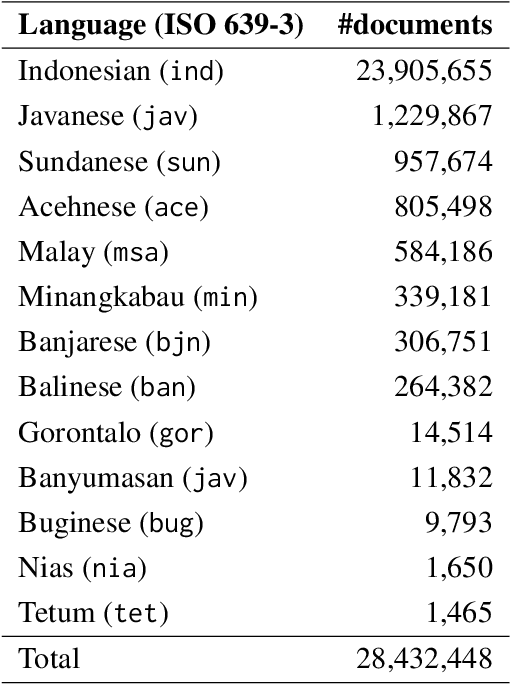
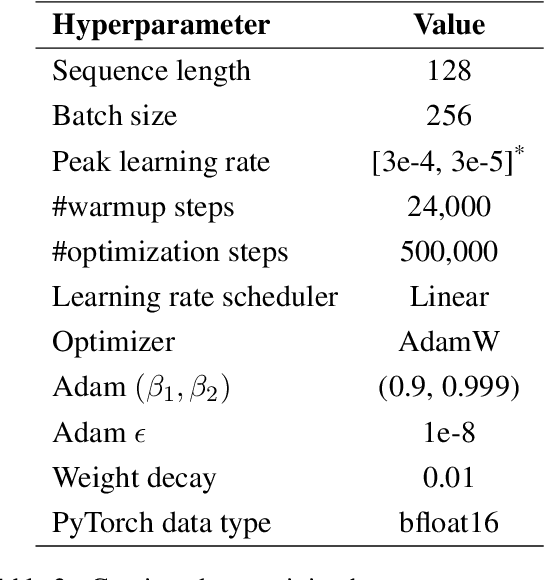
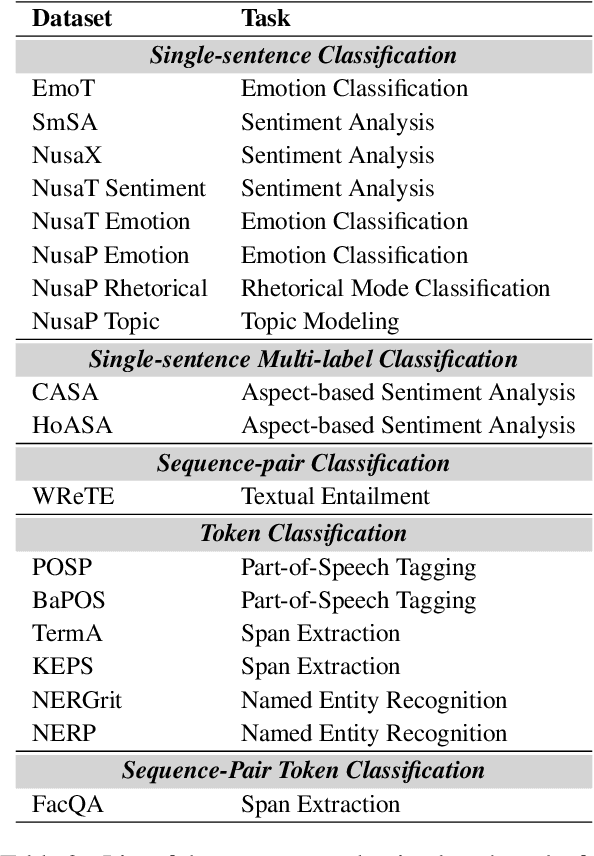

Indonesia's linguistic landscape is remarkably diverse, encompassing over 700 languages and dialects, making it one of the world's most linguistically rich nations. This diversity, coupled with the widespread practice of code-switching and the presence of low-resource regional languages, presents unique challenges for modern pre-trained language models. In response to these challenges, we developed NusaBERT, building upon IndoBERT by incorporating vocabulary expansion and leveraging a diverse multilingual corpus that includes regional languages and dialects. Through rigorous evaluation across a range of benchmarks, NusaBERT demonstrates state-of-the-art performance in tasks involving multiple languages of Indonesia, paving the way for future natural language understanding research for under-represented languages.