 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Volume Drives Performance: Tackling Domain Shift in Extremely Low-Resource Translation via RAG
Jan 15, 2026Neural Machine Translation (NMT) models for low-resource languages suffer significant performance degradation under domain shift. We quantify this challenge using Dhao, an indigenous language of Eastern Indonesia with no digital footprint beyond the New Testament (NT). When applied to the unseen Old Testament (OT), a standard NMT model fine-tuned on the NT drops from an in-domain score of 36.17 chrF++ to 27.11 chrF++. To recover this loss, we introduce a hybrid framework where a fine-tuned NMT model generates an initial draft, which is then refined by a Large Language Model (LLM) using Retrieval-Augmented Generation (RAG). The final system achieves 35.21 chrF++ (+8.10 recovery), effectively matching the original in-domain quality. Our analysis reveals that this performance is driven primarily by the number of retrieved examples rather than the choice of retrieval algorithm. Qualitative analysis confirms the LLM acts as a robust "safety net," repairing severe failures in zero-shot domains.
NusaBERT: Teaching IndoBERT to be Multilingual and Multicultural
Mar 04, 2024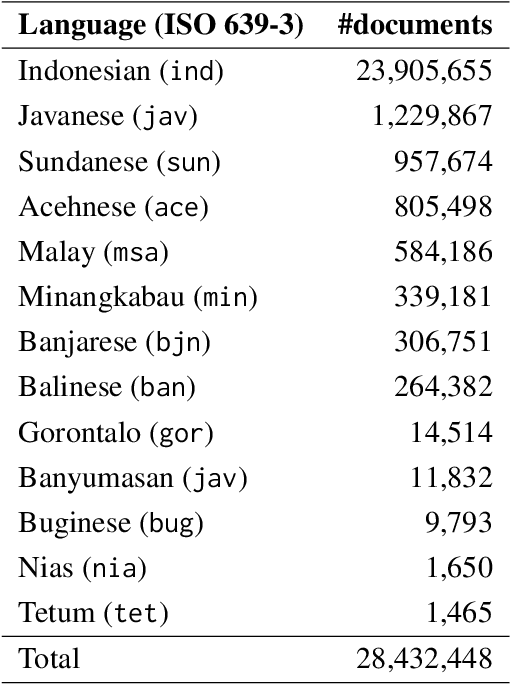
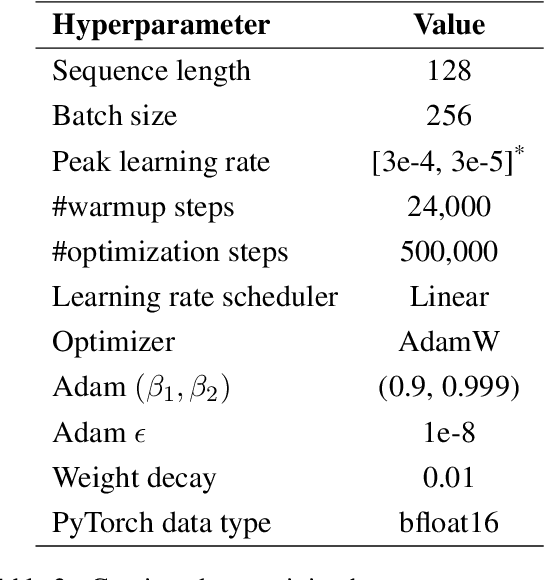
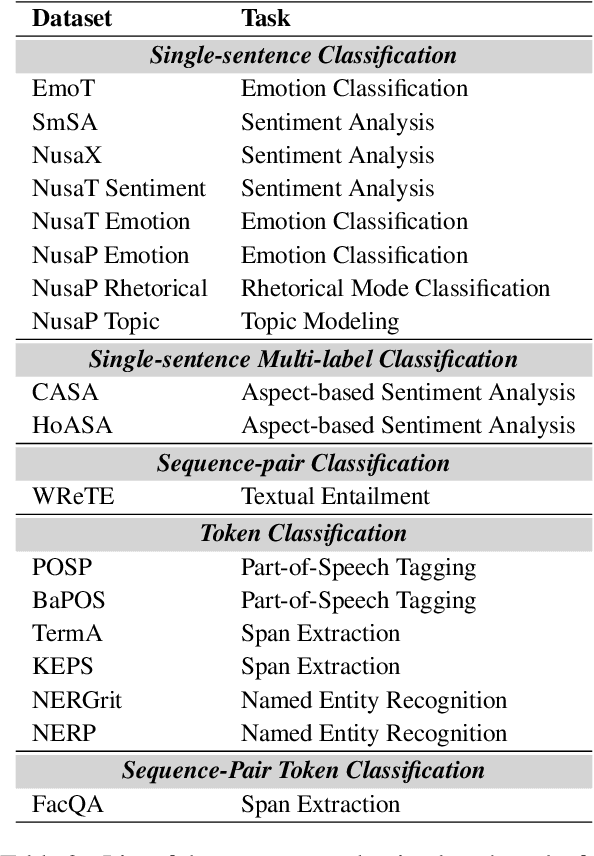

Indonesia's linguistic landscape is remarkably diverse, encompassing over 700 languages and dialects, making it one of the world's most linguistically rich nations. This diversity, coupled with the widespread practice of code-switching and the presence of low-resource regional languages, presents unique challenges for modern pre-trained language models. In response to these challenges, we developed NusaBERT, building upon IndoBERT by incorporating vocabulary expansion and leveraging a diverse multilingual corpus that includes regional languages and dialects. Through rigorous evaluation across a range of benchmarks, NusaBERT demonstrates state-of-the-art performance in tasks involving multiple languages of Indonesia, paving the way for future natural language understanding research for under-represented languages.