 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Volume Drives Performance: Tackling Domain Shift in Extremely Low-Resource Translation via RAG
Jan 15, 2026Neural Machine Translation (NMT) models for low-resource languages suffer significant performance degradation under domain shift. We quantify this challenge using Dhao, an indigenous language of Eastern Indonesia with no digital footprint beyond the New Testament (NT). When applied to the unseen Old Testament (OT), a standard NMT model fine-tuned on the NT drops from an in-domain score of 36.17 chrF++ to 27.11 chrF++. To recover this loss, we introduce a hybrid framework where a fine-tuned NMT model generates an initial draft, which is then refined by a Large Language Model (LLM) using Retrieval-Augmented Generation (RAG). The final system achieves 35.21 chrF++ (+8.10 recovery), effectively matching the original in-domain quality. Our analysis reveals that this performance is driven primarily by the number of retrieved examples rather than the choice of retrieval algorithm. Qualitative analysis confirms the LLM acts as a robust "safety net," repairing severe failures in zero-shot domains.
TULUN: Transparent and Adaptable Low-resource Machine Translation
May 24, 2025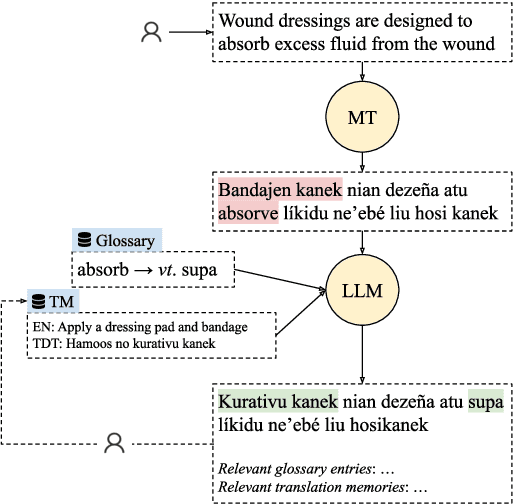
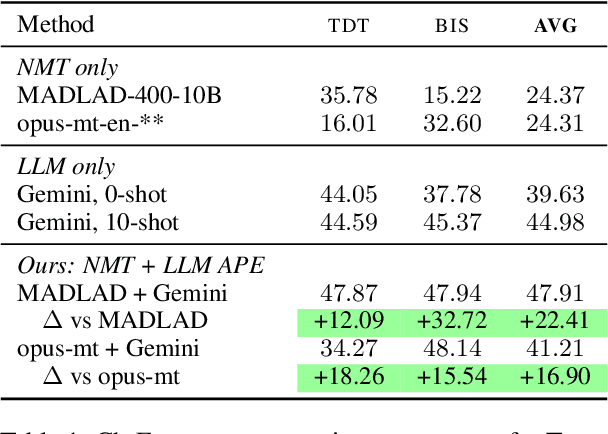
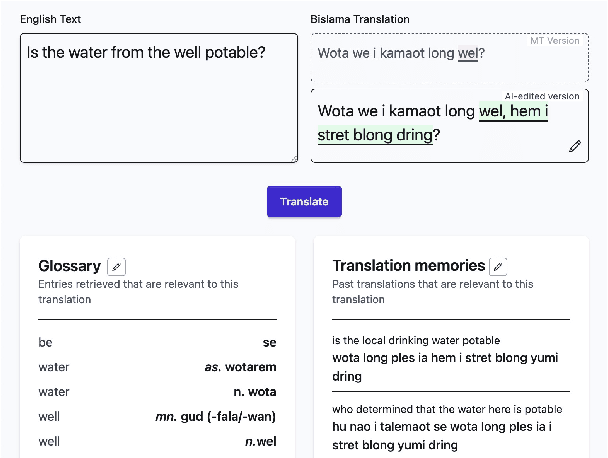
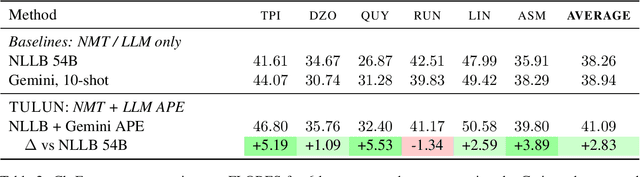
Machine translation (MT) systems that support low-resource languages often struggle on specialized domains. While researchers have proposed various techniques for domain adaptation, these approaches typically require model fine-tuning, making them impractical for non-technical users and small organizations. To address this gap, we propose Tulun, a versatile solution for terminology-aware translation, combining neural MT with large language model (LLM)-based post-editing guided by existing glossaries and translation memories. Our open-source web-based platform enables users to easily create, edit, and leverage terminology resources, fostering a collaborative human-machine translation process that respects and incorporates domain expertise while increasing MT accuracy. Evaluations show effectiveness in both real-world and benchmark scenarios: on medical and disaster relief translation tasks for Tetun and Bislama, our system achieves improvements of 16.90-22.41 ChrF++ points over baseline MT systems. Across six low-resource languages on the FLORES dataset, Tulun outperforms both standalone MT and LLM approaches, achieving an average improvement of 2.8 ChrF points over NLLB-54B.
A General Framework to Evaluate Methods for Assessing Dimensions of Lexical Semantic Change Using LLM-Generated Synthetic Data
Mar 11, 2025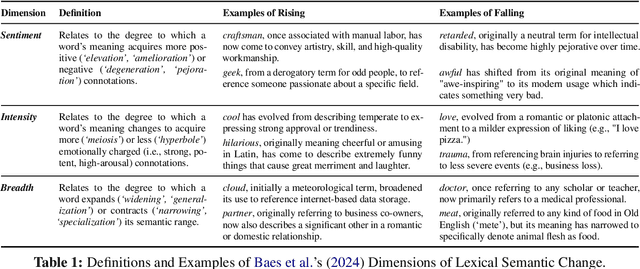

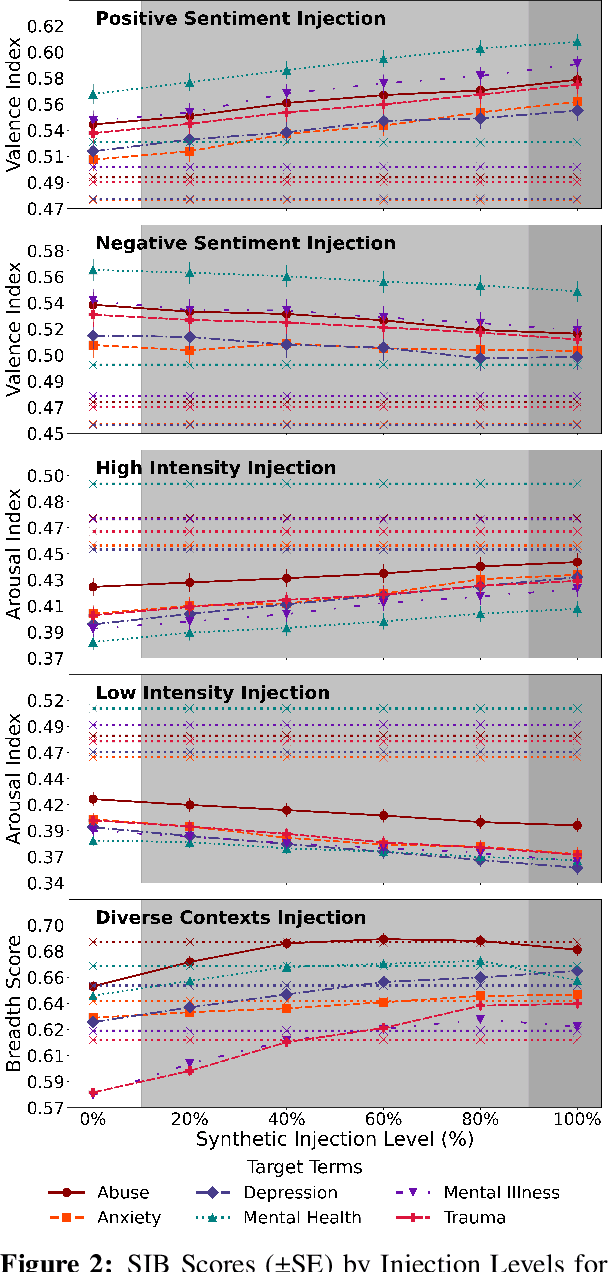

Lexical Semantic Change (LSC) offers insights into cultural and social dynamics. Yet, the validity of methods for measuring kinds of LSC has yet to be established due to the absence of historical benchmark datasets. To address this gap, we develop a novel three-stage evaluation framework that involves: 1) creating a scalable, domain-general methodology for generating synthetic datasets that simulate theory-driven LSC across time, leveraging In-Context Learning and a lexical database; 2) using these datasets to evaluate the effectiveness of various methods; and 3) assessing their suitability for specific dimensions and domains. We apply this framework to simulate changes across key dimensions of LSC (SIB: Sentiment, Intensity, and Breadth) using examples from psychology, and evaluate the sensitivity of selected methods to detect these artificially induced changes. Our findings support the utility of the synthetic data approach, validate the efficacy of tailored methods for detecting synthetic changes in SIB, and reveal that a state-of-the-art LSC model faces challenges in detecting affective dimensions of LSC. This framework provides a valuable tool for dimension- and domain-specific bench-marking and evaluation of LSC methods, with particular benefits for the social sciences.
Low-Resource Machine Translation through Retrieval-Augmented LLM Prompting: A Study on the Mambai Language
Apr 07, 2024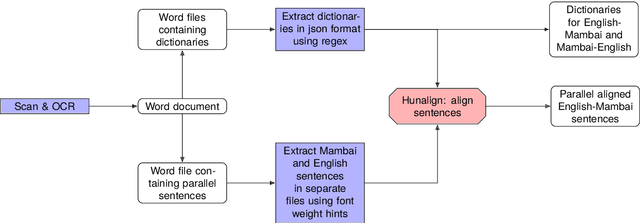
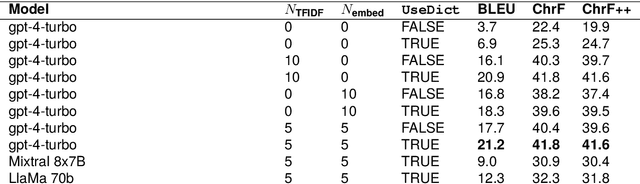
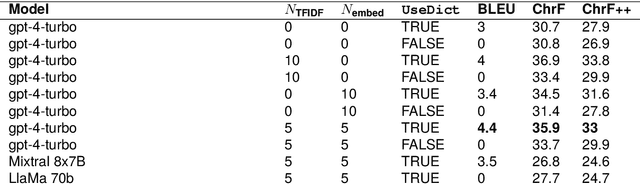
This study explores the use of large language models (LLMs) for translating English into Mambai, a low-resource Austronesian language spoken in Timor-Leste, with approximately 200,000 native speakers. Leveraging a novel corpus derived from a Mambai language manual and additional sentences translated by a native speaker, we examine the efficacy of few-shot LLM prompting for machine translation (MT) in this low-resource context. Our methodology involves the strategic selection of parallel sentences and dictionary entries for prompting, aiming to enhance translation accuracy, using open-source and proprietary LLMs (LlaMa 2 70b, Mixtral 8x7B, GPT-4). We find that including dictionary entries in prompts and a mix of sentences retrieved through TF-IDF and semantic embeddings significantly improves translation quality. However, our findings reveal stark disparities in translation performance across test sets, with BLEU scores reaching as high as 21.2 on materials from the language manual, in contrast to a maximum of 4.4 on a test set provided by a native speaker. These results underscore the importance of diverse and representative corpora in assessing MT for low-resource languages. Our research provides insights into few-shot LLM prompting for low-resource MT, and makes available an initial corpus for the Mambai language.