 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUDIDI: A Two-Stage Framework for Multilingual Dictionary Digitization with Language Models
Jun 08, 2026Multilingual dictionaries are among the most valuable documentary resources for low-resource and endangered languages, yet many remain available only as scans. For many decades, their digitization and conversion into a machine-readable format was nearly impossible due to language-specific scripts, complex multi-column layouts full of entries with abbreviations and cross-references. Recent vision-language models offer a promising solution, but it is unclear how well they preserve characters, markup, and process lexicographic structure. We introduce MUDIDI, a two-stage framework for multi-lingual dictionary digitization. Stage One evaluates the quality of character recognition and markup preservation; Stage Two focuses on dictionary entry segmentation with subsequent mapping into a machine-readable lexicographic schema, SIL's Multi-Dictionary Formatter. We also release a dataset that consists of human-annotated lexicographic entries collected from 30 public-domain dictionaries featuring diverse writing systems, language families, and formats. We benchmark OCR systems, general-purpose Large Language Models (LLMs), and Vision Language Models (VLMs) on the dataset, demonstrating superior performance of LLMs across most writing systems and languages in both stages, and provide practical guidelines on improving the results for more challenging scenarios. Finally, we show that supplementing additional information, such as dictionary introduction, to the LLMs can improve the quality of the digitized dictionary. Github: https://github.com/DavidSamuell/MUDIDI-Pipeline-for-Digitization-of-Multilingual-Dictionary/
Beyond "To whom it may concern": Tailoring Machine Translation to Audience and Intent
Jun 02, 2026Translation quality depends on purpose: the same source text demands different translations depending on audience, tone, and communicative intent. Yet MT models and metrics treat translation as a fixed mapping from source to target. LLMs enable users to explicitly specify purpose alongside source text, yet this capability has not been evaluated at scale. We introduce a systematic evaluation of purpose-driven MT across 50 languages, 5 model sizes and 8 text domains. We find that (1) explicit instructions substantially improve translation adaptedness, with larger gains on informal domains (conversation, social media), for larger model sizes and for higher-resource languages; (2) instructions outperform semantically-matched few-shot examples and paragraph-level context; (3) traditional MT metrics fail to capture adaptation quality, often penalizing adapted translations; (4) when curated instructions are unavailable, models can self-generate them from surrounding document context, closing up to 80% of the adaptedness gap to curated instructions. Our results establish that purpose-adapted MT is a viable and measurable capability of LLMs, while highlighting the need for purpose-aware metrics.
CommonMorph: Participatory Morphological Documentation Platform
Apr 06, 2026Collecting and annotating morphological data present significant challenges, requiring linguistic expertise, methodological rigour, and substantial resources. These barriers are particularly acute for low-resource languages and varieties. To accelerate this process, we introduce \texttt{CommonMorph}, a comprehensive platform that streamlines morphological data collection development through a three-tiered approach: expert linguistic definition, contributor elicitation, and community validation. The platform minimises manual work by incorporating active learning, annotation suggestions, and tools to import and adapt materials from related languages. It accommodates diverse morphological systems, including fusional, agglutinative, and root-and-pattern morphologies. Its open-source design and UniMorph-compatible outputs ensure accessibility and interoperability with NLP tools. Our platform is accessible at https://common-morph.com, offering a replicable model for preserving linguistic diversity through collaborative technology.
Vavanagi: a Community-run Platform for Documentation of the Hula Language in Papua New Guinea
Mar 15, 2026We present Vavanagi, a community-run platform for Hula (Vula'a), an Austronesian language of Papua New Guinea with approximately 10,000 speakers. Vavanagi supports crowdsourced English-Hula text translation and voice recording, with elder-led review and community-governed data infrastructure. To date, 77 translators and 4 reviewers have produced over 12k parallel sentence pairs covering 9k unique Hula words. We also propose a multi-level framework for measuring community involvement, from consultation to fully community-initiated and governed projects. We position Vavanagi at Level 5: initiative, design, implementation, and data governance all sit within the Hula community, making it, to our knowledge, the first community-led language technology initiative for a language of this size. Vavanagi shows how language technology can bridge village-based and urban members, connect generations, and support cultural heritage on the community's own terms.
A Joint Multitask Model for Morpho-Syntactic Parsing
Aug 19, 2025



We present a joint multitask model for the UniDive 2025 Morpho-Syntactic Parsing shared task, where systems predict both morphological and syntactic analyses following novel UD annotation scheme. Our system uses a shared XLM-RoBERTa encoder with three specialized decoders for content word identification, dependency parsing, and morphosyntactic feature prediction. Our model achieves the best overall performance on the shared task's leaderboard covering nine typologically diverse languages, with an average MSLAS score of 78.7 percent, LAS of 80.1 percent, and Feats F1 of 90.3 percent. Our ablation studies show that matching the task's gold tokenization and content word identification are crucial to model performance. Error analysis reveals that our model struggles with core grammatical cases (particularly Nom-Acc) and nominal features across languages.
TULUN: Transparent and Adaptable Low-resource Machine Translation
May 24, 2025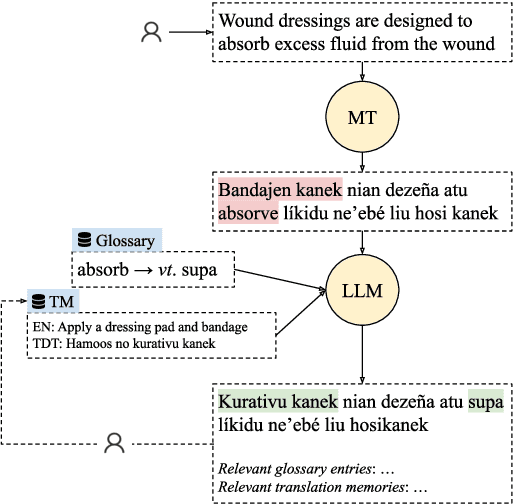
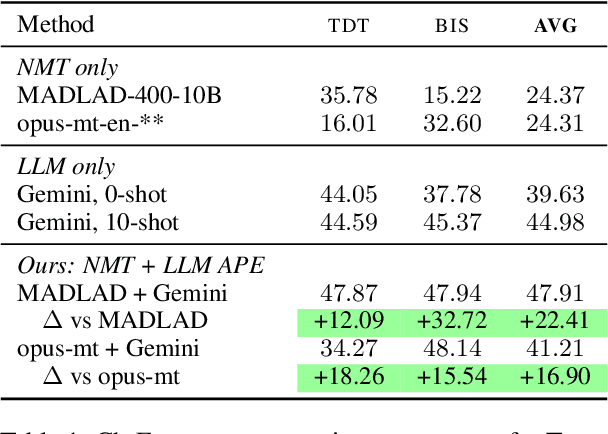
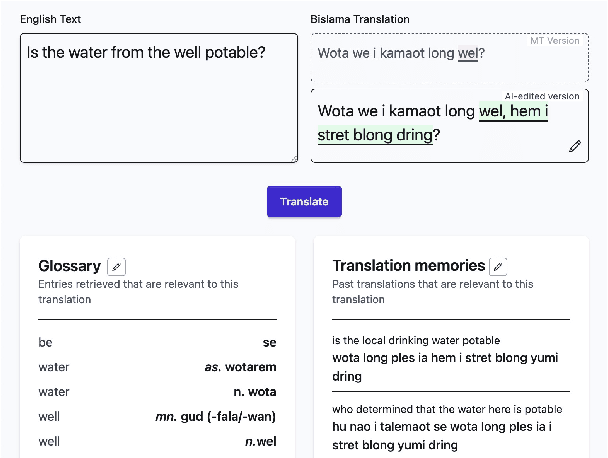
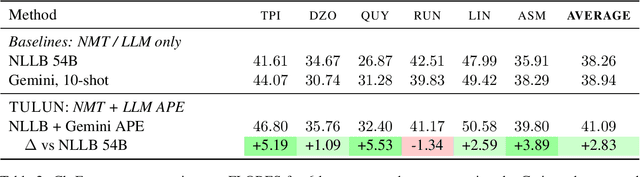
Machine translation (MT) systems that support low-resource languages often struggle on specialized domains. While researchers have proposed various techniques for domain adaptation, these approaches typically require model fine-tuning, making them impractical for non-technical users and small organizations. To address this gap, we propose Tulun, a versatile solution for terminology-aware translation, combining neural MT with large language model (LLM)-based post-editing guided by existing glossaries and translation memories. Our open-source web-based platform enables users to easily create, edit, and leverage terminology resources, fostering a collaborative human-machine translation process that respects and incorporates domain expertise while increasing MT accuracy. Evaluations show effectiveness in both real-world and benchmark scenarios: on medical and disaster relief translation tasks for Tetun and Bislama, our system achieves improvements of 16.90-22.41 ChrF++ points over baseline MT systems. Across six low-resource languages on the FLORES dataset, Tulun outperforms both standalone MT and LLM approaches, achieving an average improvement of 2.8 ChrF points over NLLB-54B.
A General Framework to Evaluate Methods for Assessing Dimensions of Lexical Semantic Change Using LLM-Generated Synthetic Data
Mar 11, 2025

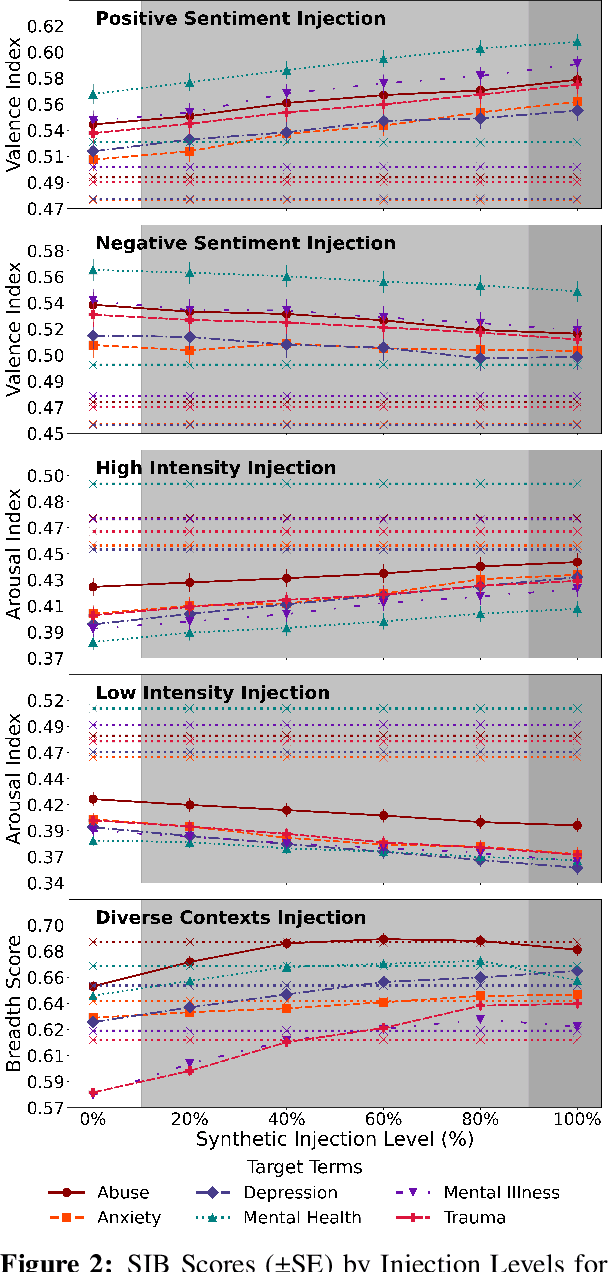

Lexical Semantic Change (LSC) offers insights into cultural and social dynamics. Yet, the validity of methods for measuring kinds of LSC has yet to be established due to the absence of historical benchmark datasets. To address this gap, we develop a novel three-stage evaluation framework that involves: 1) creating a scalable, domain-general methodology for generating synthetic datasets that simulate theory-driven LSC across time, leveraging In-Context Learning and a lexical database; 2) using these datasets to evaluate the effectiveness of various methods; and 3) assessing their suitability for specific dimensions and domains. We apply this framework to simulate changes across key dimensions of LSC (SIB: Sentiment, Intensity, and Breadth) using examples from psychology, and evaluate the sensitivity of selected methods to detect these artificially induced changes. Our findings support the utility of the synthetic data approach, validate the efficacy of tailored methods for detecting synthetic changes in SIB, and reveal that a state-of-the-art LSC model faces challenges in detecting affective dimensions of LSC. This framework provides a valuable tool for dimension- and domain-specific bench-marking and evaluation of LSC methods, with particular benefits for the social sciences.
Low-resource Machine Translation: what for? who for? An observational study on a dedicated Tetun language translation service
Nov 19, 2024The impact of machine translation (MT) on low-resource languages remains poorly understood. In particular, observational studies of actual usage patterns are scarce. Such studies could provide valuable insights into user needs and behaviours, complementing survey-based methods. Here we present an observational analysis of real-world MT usage for Tetun, the lingua franca of Timor-Leste, using server logs from a widely-used MT service with over $70,000$ monthly active users. Our analysis of $100,000$ translation requests reveals patterns that challenge assumptions based on existing corpora. We find that users, many of them students on mobile devices, typically translate short texts into Tetun across diverse domains including science, healthcare, and daily life. This contrasts sharply with available Tetun corpora, which are dominated by news articles covering government and social issues. Our results suggest that MT systems for languages like Tetun should prioritise translating into the low-resource language, handling brief inputs effectively, and covering a wide range of domains relevant to educational contexts. More broadly, this study demonstrates how observational analysis can inform low-resource language technology development, by grounding research in practical community needs.
Generating bilingual example sentences with large language models as lexicography assistants
Oct 04, 2024



We present a study of LLMs' performance in generating and rating example sentences for bilingual dictionaries across languages with varying resource levels: French (high-resource), Indonesian (mid-resource), and Tetun (low-resource), with English as the target language. We evaluate the quality of LLM-generated examples against the GDEX (Good Dictionary EXample) criteria: typicality, informativeness, and intelligibility. Our findings reveal that while LLMs can generate reasonably good dictionary examples, their performance degrades significantly for lower-resourced languages. We also observe high variability in human preferences for example quality, reflected in low inter-annotator agreement rates. To address this, we demonstrate that in-context learning can successfully align LLMs with individual annotator preferences. Additionally, we explore the use of pre-trained language models for automated rating of examples, finding that sentence perplexity serves as a good proxy for typicality and intelligibility in higher-resourced languages. Our study also contributes a novel dataset of 600 ratings for LLM-generated sentence pairs, and provides insights into the potential of LLMs in reducing the cost of lexicographic work, particularly for low-resource languages.
Can a Neural Model Guide Fieldwork? A Case Study on Morphological Inflection
Sep 22, 2024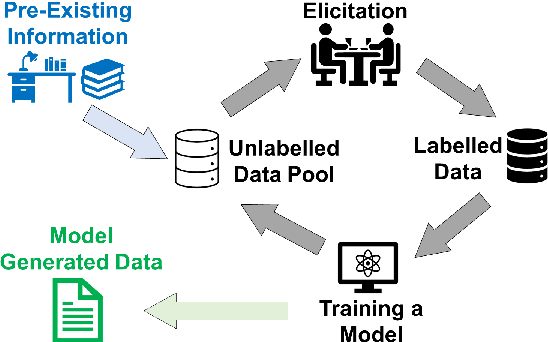
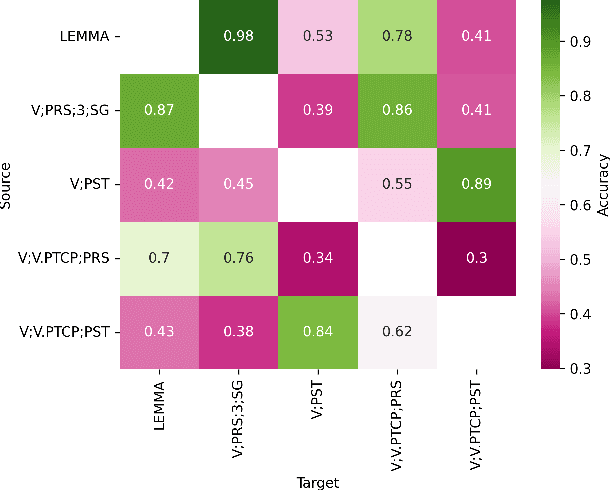
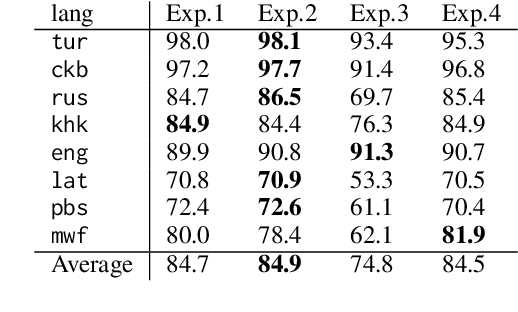
Linguistic fieldwork is an important component in language documentation and preservation. However, it is a long, exhaustive, and time-consuming process. This paper presents a novel model that guides a linguist during the fieldwork and accounts for the dynamics of linguist-speaker interactions. We introduce a novel framework that evaluates the efficiency of various sampling strategies for obtaining morphological data and assesses the effectiveness of state-of-the-art neural models in generalising morphological structures. Our experiments highlight two key strategies for improving the efficiency: (1) increasing the diversity of annotated data by uniform sampling among the cells of the paradigm tables, and (2) using model confidence as a guide to enhance positive interaction by providing reliable predictions during annotation.