 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Metrics for Lexical Semantic Change Detection
Feb 17, 2026Lexical semantic change detection (LSCD) increasingly relies on contextualised language model embeddings, yet most approaches still quantify change using a small set of semantic change metrics, primarily Average Pairwise Distance (APD) and cosine distance over word prototypes (PRT). We introduce Average Minimum Distance (AMD) and Symmetric Average Minimum Distance (SAMD), new measures that quantify semantic change via local correspondence between word usages across time periods. Across multiple languages, encoder models, and representation spaces, we show that AMD often provides more robust performance, particularly under dimensionality reduction and with non-specialised encoders, while SAMD excels with specialised encoders. We suggest that LSCD may benefit from considering alternative semantic change metrics beyond APD and PRT, with AMD offering a robust option for contextualised embedding-based analysis.
Estranged Predictions: Measuring Semantic Category Disruption with Masked Language Modelling
Nov 11, 2025This paper examines how science fiction destabilises ontological categories by measuring conceptual permeability across the terms human, animal, and machine using masked language modelling (MLM). Drawing on corpora of science fiction (Gollancz SF Masterworks) and general fiction (NovelTM), we operationalise Darko Suvin's theory of estrangement as computationally measurable deviation in token prediction, using RoBERTa to generate lexical substitutes for masked referents and classifying them via Gemini. We quantify conceptual slippage through three metrics: retention rate, replacement rate, and entropy, mapping the stability or disruption of category boundaries across genres. Our findings reveal that science fiction exhibits heightened conceptual permeability, particularly around machine referents, which show significant cross-category substitution and dispersion. Human terms, by contrast, maintain semantic coherence and often anchor substitutional hierarchies. These patterns suggest a genre-specific restructuring within anthropocentric logics. We argue that estrangement in science fiction operates as a controlled perturbation of semantic norms, detectable through probabilistic modelling, and that MLMs, when used critically, serve as interpretive instruments capable of surfacing genre-conditioned ontological assumptions. This study contributes to the methodological repertoire of computational literary studies and offers new insights into the linguistic infrastructure of science fiction.
Multilinguality Does not Make Sense: Investigating Factors Behind Zero-Shot Transfer in Sense-Aware Tasks
May 30, 2025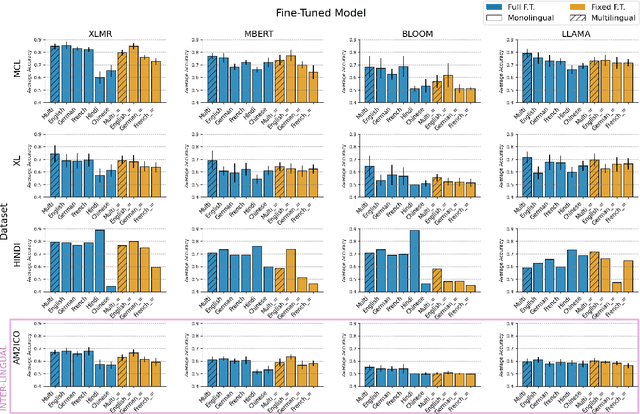
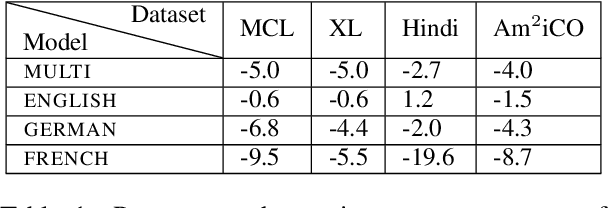
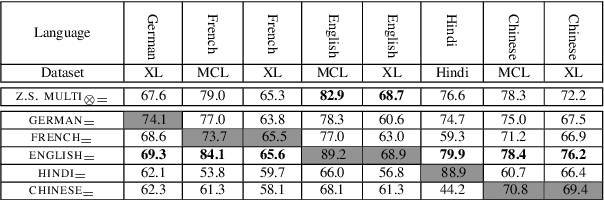
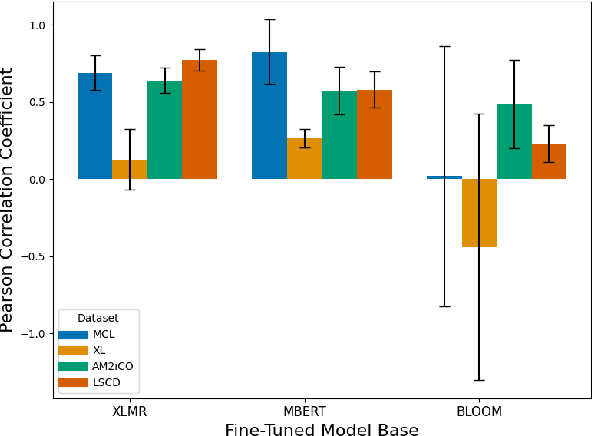
Cross-lingual transfer allows models to perform tasks in languages unseen during training and is often assumed to benefit from increased multilinguality. In this work, we challenge this assumption in the context of two underexplored, sense-aware tasks: polysemy disambiguation and lexical semantic change. Through a large-scale analysis across 28 languages, we show that multilingual training is neither necessary nor inherently beneficial for effective transfer. Instead, we find that confounding factors - such as fine-tuning data composition and evaluation artifacts - better account for the perceived advantages of multilinguality. Our findings call for more rigorous evaluations in multilingual NLP. We release fine-tuned models and benchmarks to support further research, with implications extending to low-resource and typologically diverse languages.
SenWiCh: Sense-Annotation of Low-Resource Languages for WiC using Hybrid Methods
May 29, 2025This paper addresses the critical need for high-quality evaluation datasets in low-resource languages to advance cross-lingual transfer. While cross-lingual transfer offers a key strategy for leveraging multilingual pretraining to expand language technologies to understudied and typologically diverse languages, its effectiveness is dependent on quality and suitable benchmarks. We release new sense-annotated datasets of sentences containing polysemous words, spanning nine low-resource languages across diverse language families and scripts. To facilitate dataset creation, the paper presents a demonstrably beneficial semi-automatic annotation method. The utility of the datasets is demonstrated through Word-in-Context (WiC) formatted experiments that evaluate transfer on these low-resource languages. Results highlight the importance of targeted dataset creation and evaluation for effective polysemy disambiguation in low-resource settings and transfer studies. The released datasets and code aim to support further research into fair, robust, and truly multilingual NLP.
Holes in Latent Space: Topological Signatures Under Adversarial Influence
May 26, 2025Understanding how adversarial conditions affect language models requires techniques that capture both global structure and local detail within high-dimensional activation spaces. We propose persistent homology (PH), a tool from topological data analysis, to systematically characterize multiscale latent space dynamics in LLMs under two distinct attack modes -- backdoor fine-tuning and indirect prompt injection. By analyzing six state-of-the-art LLMs, we show that adversarial conditions consistently compress latent topologies, reducing structural diversity at smaller scales while amplifying dominant features at coarser ones. These topological signatures are statistically robust across layers, architectures, model sizes, and align with the emergence of adversarial effects deeper in the network. To capture finer-grained mechanisms underlying these shifts, we introduce a neuron-level PH framework that quantifies how information flows and transforms within and across layers. Together, our findings demonstrate that PH offers a principled and unifying approach to interpreting representational dynamics in LLMs, particularly under distributional shift.
A General Framework to Evaluate Methods for Assessing Dimensions of Lexical Semantic Change Using LLM-Generated Synthetic Data
Mar 11, 2025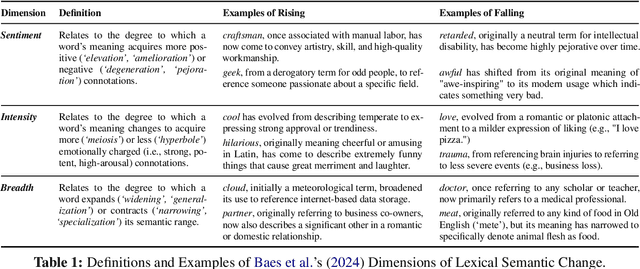

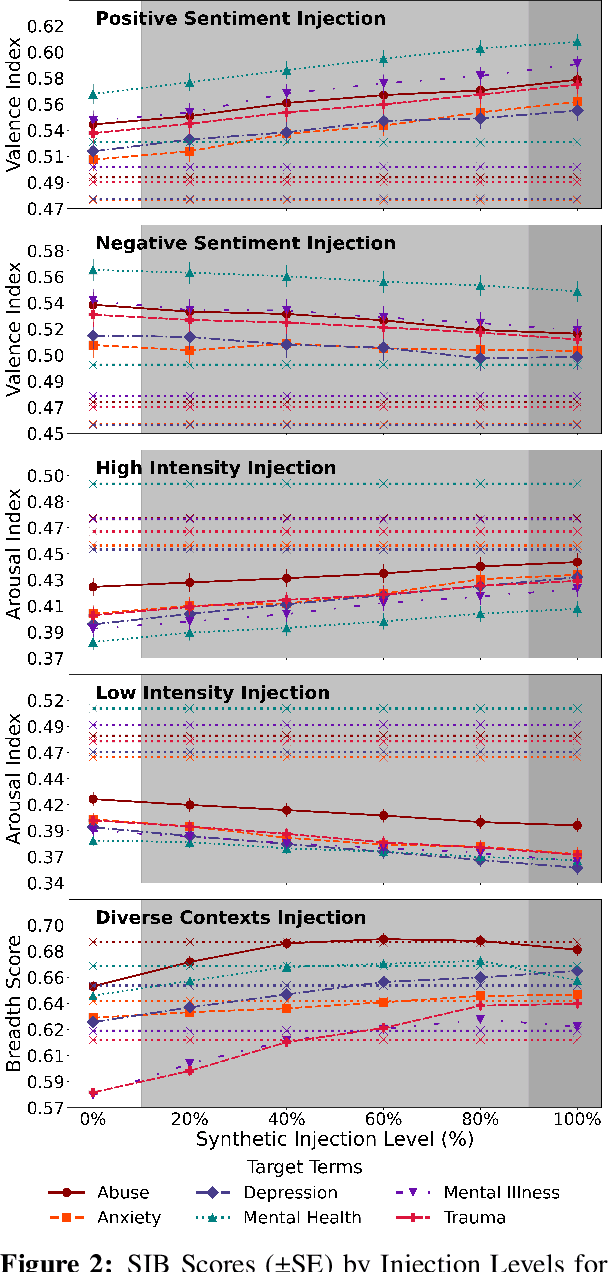

Lexical Semantic Change (LSC) offers insights into cultural and social dynamics. Yet, the validity of methods for measuring kinds of LSC has yet to be established due to the absence of historical benchmark datasets. To address this gap, we develop a novel three-stage evaluation framework that involves: 1) creating a scalable, domain-general methodology for generating synthetic datasets that simulate theory-driven LSC across time, leveraging In-Context Learning and a lexical database; 2) using these datasets to evaluate the effectiveness of various methods; and 3) assessing their suitability for specific dimensions and domains. We apply this framework to simulate changes across key dimensions of LSC (SIB: Sentiment, Intensity, and Breadth) using examples from psychology, and evaluate the sensitivity of selected methods to detect these artificially induced changes. Our findings support the utility of the synthetic data approach, validate the efficacy of tailored methods for detecting synthetic changes in SIB, and reveal that a state-of-the-art LSC model faces challenges in detecting affective dimensions of LSC. This framework provides a valuable tool for dimension- and domain-specific bench-marking and evaluation of LSC methods, with particular benefits for the social sciences.
Analyzing Semantic Change through Lexical Replacements
Apr 29, 2024Modern language models are capable of contextualizing words based on their surrounding context. However, this capability is often compromised due to semantic change that leads to words being used in new, unexpected contexts not encountered during pre-training. In this paper, we model \textit{semantic change} by studying the effect of unexpected contexts introduced by \textit{lexical replacements}. We propose a \textit{replacement schema} where a target word is substituted with lexical replacements of varying relatedness, thus simulating different kinds of semantic change. Furthermore, we leverage the replacement schema as a basis for a novel \textit{interpretable} model for semantic change. We are also the first to evaluate the use of LLaMa for semantic change detection.
GPT v BERT: Dawn of Justice for Semantic Change Detection
Jan 25, 2024In the universe of Natural Language Processing, Transformer-based language models like BERT and (Chat)GPT have emerged as lexical superheroes with great power to solve open research problems. In this paper, we specifically focus on the temporal problem of semantic change, and evaluate their ability to solve two diachronic extensions of the Word-in-Context (WiC) task: TempoWiC and HistoWiC. In particular, we investigate the potential of a novel, off-the-shelf technology like ChatGPT (and GPT) 3.5 compared to BERT, which represents a family of models that currently stand as the state-of-the-art for modeling semantic change. Our experiments represent the first attempt to assess the use of (Chat)GPT for studying semantic change. Our results indicate that ChatGPT performs significantly worse than the foundational GPT version. Furthermore, our results demonstrate that (Chat)GPT achieves slightly lower performance than BERT in detecting long-term changes but performs significantly worse in detecting short-term changes.
Logical Reasoning for Natural Language Inference Using Generated Facts as Atoms
May 22, 2023
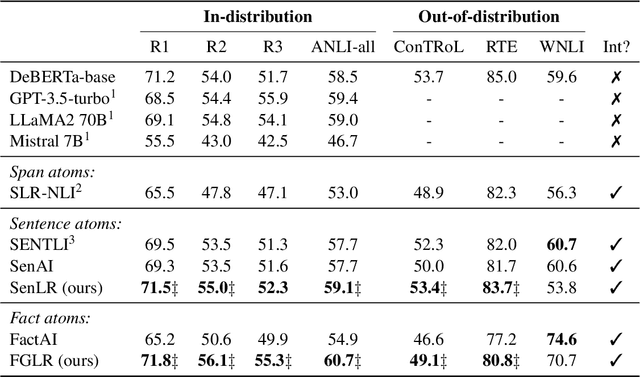


State-of-the-art neural models can now reach human performance levels across various natural language understanding tasks. However, despite this impressive performance, models are known to learn from annotation artefacts at the expense of the underlying task. While interpretability methods can identify influential features for each prediction, there are no guarantees that these features are responsible for the model decisions. Instead, we introduce a model-agnostic logical framework to determine the specific information in an input responsible for each model decision. This method creates interpretable Natural Language Inference (NLI) models that maintain their predictive power. We achieve this by generating facts that decompose complex NLI observations into individual logical atoms. Our model makes predictions for each atom and uses logical rules to decide the class of the observation based on the predictions for each atom. We apply our method to the highly challenging ANLI dataset, where our framework improves the performance of both a DeBERTa-base and BERT baseline. Our method performs best on the most challenging examples, achieving a new state-of-the-art for the ANLI round 3 test set. We outperform every baseline in a reduced-data setting, and despite using no annotations for the generated facts, our model predictions for individual facts align with human expectations.
Computational modeling of semantic change
Apr 13, 2023In this chapter we provide an overview of computational modeling for semantic change using large and semi-large textual corpora. We aim to provide a key for the interpretation of relevant methods and evaluation techniques, and also provide insights into important aspects of the computational study of semantic change. We discuss the pros and cons of different classes of models with respect to the properties of the data from which one wishes to model semantic change, and which avenues are available to evaluate the results.