 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Symmetry Bottlenecks in GNN Readouts
Feb 05, 2026Graph neural networks (GNNs) are widely used for learning on structured data, yet their ability to distinguish non-isomorphic graphs is fundamentally limited. These limitations are usually attributed to message passing; in this work we show that an independent bottleneck arises at the readout stage. Using finite-dimensional representation theory, we prove that all linear permutation-invariant readouts, including sum and mean pooling, factor through the Reynolds (group-averaging) operator and therefore project node embeddings onto the fixed subspace of the permutation action, erasing all non-trivial symmetry-aware components regardless of encoder expressivity. This yields both a new expressivity barrier and an interpretable characterization of what global pooling preserves or destroys. To overcome this collapse, we introduce projector-based invariant readouts that decompose node representations into symmetry-aware channels and summarize them with nonlinear invariant statistics, preserving permutation invariance while retaining information provably invisible to averaging. Empirically, swapping only the readout enables fixed encoders to separate WL-hard graph pairs and improves performance across multiple benchmarks, demonstrating that readout design is a decisive and under-appreciated factor in GNN expressivity.
Riemannian Neural Optimal Transport
Feb 03, 2026Computational optimal transport (OT) offers a principled framework for generative modeling. Neural OT methods, which use neural networks to learn an OT map (or potential) from data in an amortized way, can be evaluated out of sample after training, but existing approaches are tailored to Euclidean geometry. Extending neural OT to high-dimensional Riemannian manifolds remains an open challenge. In this paper, we prove that any method for OT on manifolds that produces discrete approximations of transport maps necessarily suffers from the curse of dimensionality: achieving a fixed accuracy requires a number of parameters that grows exponentially with the manifold dimension. Motivated by this limitation, we introduce Riemannian Neural OT (RNOT) maps, which are continuous neural-network parameterizations of OT maps on manifolds that avoid discretization and incorporate geometric structure by construction. Under mild regularity assumptions, we prove that RNOT maps approximate Riemannian OT maps with sub-exponential complexity in the dimension. Experiments on synthetic and real datasets demonstrate improved scalability and competitive performance relative to discretization-based baselines.
Holes in Latent Space: Topological Signatures Under Adversarial Influence
May 26, 2025Understanding how adversarial conditions affect language models requires techniques that capture both global structure and local detail within high-dimensional activation spaces. We propose persistent homology (PH), a tool from topological data analysis, to systematically characterize multiscale latent space dynamics in LLMs under two distinct attack modes -- backdoor fine-tuning and indirect prompt injection. By analyzing six state-of-the-art LLMs, we show that adversarial conditions consistently compress latent topologies, reducing structural diversity at smaller scales while amplifying dominant features at coarser ones. These topological signatures are statistically robust across layers, architectures, model sizes, and align with the emergence of adversarial effects deeper in the network. To capture finer-grained mechanisms underlying these shifts, we introduce a neuron-level PH framework that quantifies how information flows and transforms within and across layers. Together, our findings demonstrate that PH offers a principled and unifying approach to interpreting representational dynamics in LLMs, particularly under distributional shift.
Metric Graph Kernels via the Tropical Torelli Map
May 17, 2025We propose new graph kernels grounded in the study of metric graphs via tropical algebraic geometry. In contrast to conventional graph kernels that are based on graph combinatorics such as nodes, edges, and subgraphs, our graph kernels are purely based on the geometry and topology of the underlying metric space. A key characterizing property of our construction is its invariance under edge subdivision, making the kernels intrinsically well-suited for comparing graphs that represent different underlying spaces. We develop efficient algorithms for computing these kernels and analyze their complexity, showing that it depends primarily on the genus of the input graphs. Empirically, our kernels outperform existing methods in label-free settings, as demonstrated on both synthetic and real-world benchmark datasets. We further highlight their practical utility through an urban road network classification task.
On the Limitations of Fractal Dimension as a Measure of Generalization
Jun 04, 2024Bounding and predicting the generalization gap of overparameterized neural networks remains a central open problem in theoretical machine learning. Neural network optimization trajectories have been proposed to possess fractal structure, leading to bounds and generalization measures based on notions of fractal dimension on these trajectories. Prominently, both the Hausdorff dimension and the persistent homology dimension have been proposed to correlate with generalization gap, thus serving as a measure of generalization. This work performs an extended evaluation of these topological generalization measures. We demonstrate that fractal dimension fails to predict generalization of models trained from poor initializations. We further identify that the $\ell^2$ norm of the final parameter iterate, one of the simplest complexity measures in learning theory, correlates more strongly with the generalization gap than these notions of fractal dimension. Finally, our study reveals the intriguing manifestation of model-wise double descent in persistent homology-based generalization measures. This work lays the ground for a deeper investigation of the causal relationships between fractal geometry, topological data analysis, and neural network optimization.
Tropical Expressivity of Neural Networks
May 30, 2024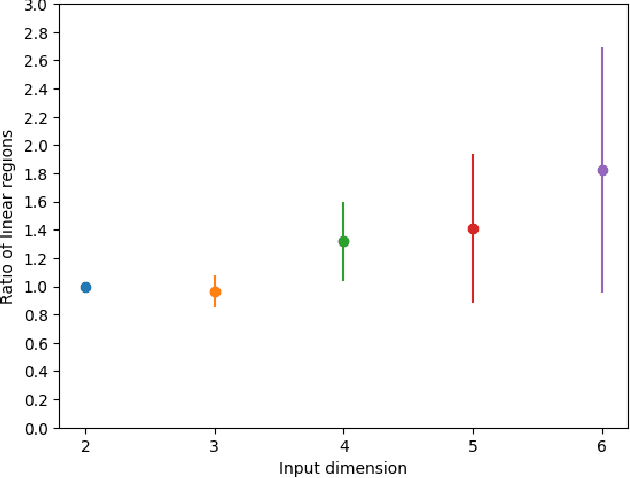

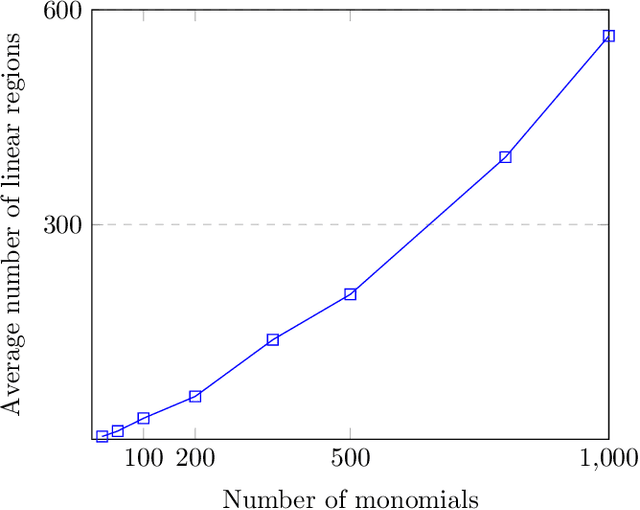

We propose an algebraic geometric framework to study the expressivity of linear activation neural networks. A particular quantity that has been actively studied in the field of deep learning is the number of linear regions, which gives an estimate of the information capacity of the architecture. To study and evaluate information capacity and expressivity, we work in the setting of tropical geometry -- a combinatorial and polyhedral variant of algebraic geometry -- where there are known connections between tropical rational maps and feedforward neural networks. Our work builds on and expands this connection to capitalize on the rich theory of tropical geometry to characterize and study various architectural aspects of neural networks. Our contributions are threefold: we provide a novel tropical geometric approach to selecting sampling domains among linear regions; an algebraic result allowing for a guided restriction of the sampling domain for network architectures with symmetries; and an open source library to analyze neural networks as tropical Puiseux rational maps. We provide a comprehensive set of proof-of-concept numerical experiments demonstrating the breadth of neural network architectures to which tropical geometric theory can be applied to reveal insights on expressivity characteristics of a network. Our work provides the foundations for the adaptation of both theory and existing software from computational tropical geometry and symbolic computation to deep learning.
Computable Stability for Persistence Rank Function Machine Learning
Jul 06, 2023Persistent homology barcodes and diagrams are a cornerstone of topological data analysis. Widely used in many real data settings, they relate variation in topological information (as measured by cellular homology) with variation in data, however, they are challenging to use in statistical settings due to their complex geometric structure. In this paper, we revisit the persistent homology rank function -- an invariant measure of ``shape" that was introduced before barcodes and persistence diagrams and captures the same information in a form that is more amenable to data and computation. In particular, since they are functions, techniques from functional data analysis -- a domain of statistics adapted for functions -- apply directly to persistent homology when represented by rank functions. Rank functions, however, have been less popular than barcodes because they face the challenge that stability -- a property that is crucial to validate their use in data analysis -- is difficult to guarantee, mainly due to metric concerns on rank function space. However, rank functions extend more naturally to the increasingly popular and important case of multiparameter persistent homology. In this paper, we study the performance of rank functions in functional inferential statistics and machine learning on both simulated and real data, and in both single and multiparameter persistent homology. We find that the use of persistent homology captured by rank functions offers a clear improvement over existing approaches. We then provide theoretical justification for our numerical experiments and applications to data by deriving several stability results for single- and multiparameter persistence rank functions under various metrics with the underlying aim of computational feasibility and interpretability.
$k$-Means Clustering for Persistent Homology
Oct 18, 2022



Persistent homology is a fundamental methodology from topological data analysis that summarizes the lifetimes of topological features within a dataset as a persistence diagram; it has recently gained much popularity from its myriad successful applications to many domains. However, a significant challenge to its widespread implementation, especially in statistical methodology and machine learning algorithms, is the format of the persistence diagram as a multiset of half-open intervals. In this paper, we comprehensively study $k$-means clustering where the input is various embeddings of persistence diagrams, as well as persistence diagrams themselves and their generalizations as persistence measures. We show that the clustering performance directly on persistence diagrams and measures far outperform their vectorized representations, despite their more complex representations. Moreover, we prove convergence of the algorithm on persistence diagram space and establish theoretical properties of the solution to the optimization problem in the Karush--Kuhn--Tucker framework.
Fast Topological Signal Identification and Persistent Cohomological Cycle Matching
Sep 30, 2022



Within the context of topological data analysis, the problems of identifying topological significance and matching signals across datasets are important and useful inferential tasks in many applications. The limitation of existing solutions to these problems, however, is computational speed. In this paper, we harness the state-of-the-art for persistent homology computation by studying the problem of determining topological prevalence and cycle matching using a cohomological approach, which increases their feasibility and applicability to a wider variety of applications and contexts. We demonstrate this on a wide range of real-life, large-scale, and complex datasets. We extend existing notions of topological prevalence and cycle matching to include general non-Morse filtrations. This provides the most general and flexible state-of-the-art adaptation of topological signal identification and persistent cycle matching, which performs comparisons of orders of ten for thousands of sampled points in a matter of minutes on standard institutional HPC CPU facilities.
Learning Linear Non-Gaussian Polytree Models
Aug 13, 2022

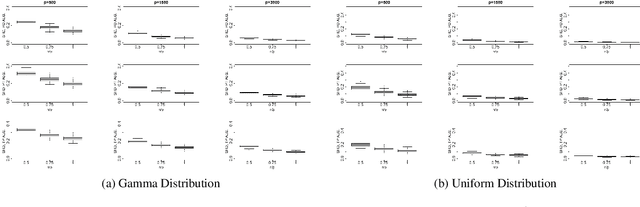
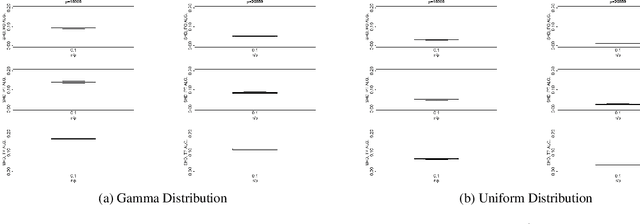
In the context of graphical causal discovery, we adapt the versatile framework of linear non-Gaussian acyclic models (LiNGAMs) to propose new algorithms to efficiently learn graphs that are polytrees. Our approach combines the Chow--Liu algorithm, which first learns the undirected tree structure, with novel schemes to orient the edges. The orientation schemes assess algebraic relations among moments of the data-generating distribution and are computationally inexpensive. We establish high-dimensional consistency results for our approach and compare different algorithmic versions in numerical experiments.