Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages
Paper and Code


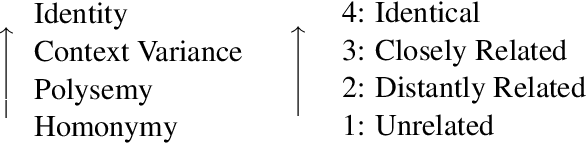

Word meaning is notoriously difficult to capture, both synchronically and diachronically. In this paper, we describe the creation of the largest resource of graded contextualized, diachronic word meaning annotation in four different languages, based on 100,000 human semantic proximity judgments. We thoroughly describe the multi-round incremental annotation process, the choice for a clustering algorithm to group usages into senses, and possible - diachronic and synchronic - uses for this dataset.
* 8 pages
View paper on