 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHatevolution: What Static Benchmarks Don't Tell Us
Jun 13, 2025Language changes over time, including in the hate speech domain, which evolves quickly following social dynamics and cultural shifts. While NLP research has investigated the impact of language evolution on model training and has proposed several solutions for it, its impact on model benchmarking remains under-explored. Yet, hate speech benchmarks play a crucial role to ensure model safety. In this paper, we empirically evaluate the robustness of 20 language models across two evolving hate speech experiments, and we show the temporal misalignment between static and time-sensitive evaluations. Our findings call for time-sensitive linguistic benchmarks in order to correctly and reliably evaluate language models in the hate speech domain.
Computational valency lexica and Homeric formularity
Aug 23, 2022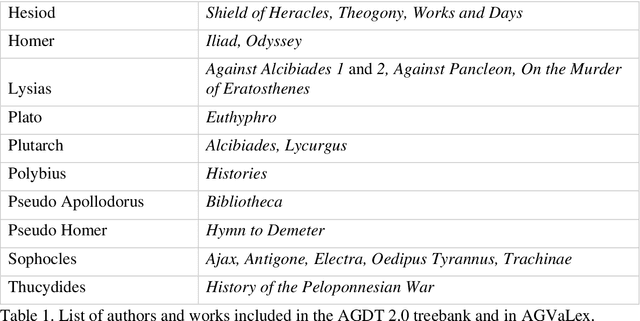


Distributional semantics, the quantitative study of meaning variation and change through corpus collocations, is currently one of the most productive research areas in computational linguistics. The wider availability of big data and of reproducible algorithms for analysis has boosted its application to living languages in recent years. But can we use distributional semantics to study a language with such a limited corpus as ancient Greek? And can this approach tell us something about such vexed questions in classical studies as the language and composition of the Homeric poems? Our paper will compare the semantic flexibility of formulae involving transitive verbs in archaic Greek epic to similar verb phrases in a non-formulaic corpus, in order to detect unique patterns of variation in formulae. To address this, we present AGVaLex, a computational valency lexicon for ancient Greek automatically extracted from the Ancient Greek Dependency Treebank. The lexicon contains quantitative corpus-driven morphological, syntactic and lexical information about verbs and their arguments, such as objects, subjects, and prepositional phrases, and has a wide range of applications for the study of the language of ancient Greek authors.
DUKweb: Diachronic word representations from the UK Web Archive corpus
Jul 02, 2021



Lexical semantic change (detecting shifts in the meaning and usage of words) is an important task for social and cultural studies as well as for Natural Language Processing applications. Diachronic word embeddings (time-sensitive vector representations of words that preserve their meaning) have become the standard resource for this task. However, given the significant computational resources needed for their generation, very few resources exist that make diachronic word embeddings available to the scientific community. In this paper we present DUKweb, a set of large-scale resources designed for the diachronic analysis of contemporary English. DUKweb was created from the JISC UK Web Domain Dataset (1996-2013), a very large archive which collects resources from the Internet Archive that were hosted on domains ending in `.uk'. DUKweb consists of a series word co-occurrence matrices and two types of word embeddings for each year in the JISC UK Web Domain dataset. We show the reuse potential of DUKweb and its quality standards via a case study on word meaning change detection.
Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
May 04, 2021



The semantics of emoji has, to date, been considered from a static perspective. We offer the first longitudinal study of how emoji semantics changes over time, applying techniques from computational linguistics to six years of Twitter data. We identify five patterns in emoji semantic development and find evidence that the less abstract an emoji is, the more likely it is to undergo semantic change. In addition, we analyse select emoji in more detail, examining the effect of seasonality and world events on emoji semantics. To aid future work on emoji and semantics, we make our data publicly available along with a web-based interface that anyone can use to explore semantic change in emoji.
DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages
Apr 17, 2021


Word meaning is notoriously difficult to capture, both synchronically and diachronically. In this paper, we describe the creation of the largest resource of graded contextualized, diachronic word meaning annotation in four different languages, based on 100,000 human semantic proximity judgments. We thoroughly describe the multi-round incremental annotation process, the choice for a clustering algorithm to group usages into senses, and possible - diachronic and synchronic - uses for this dataset.
Lexical semantic change for Ancient Greek and Latin
Jan 22, 2021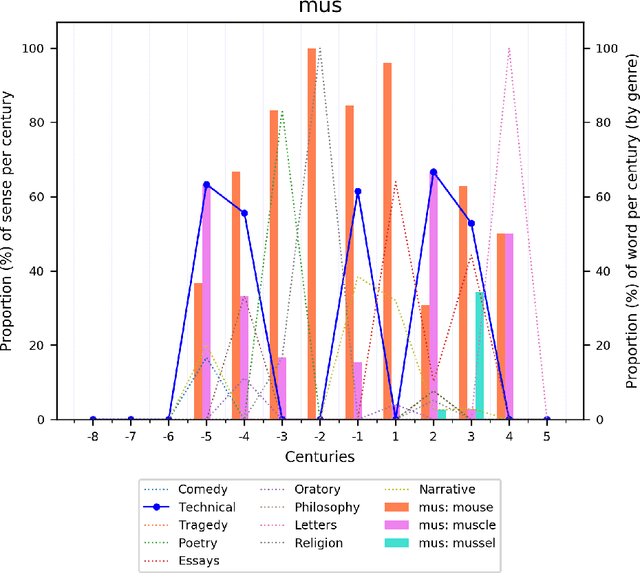
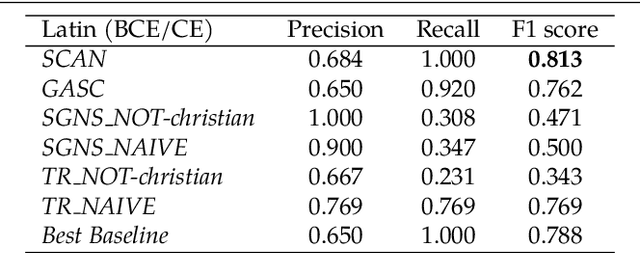
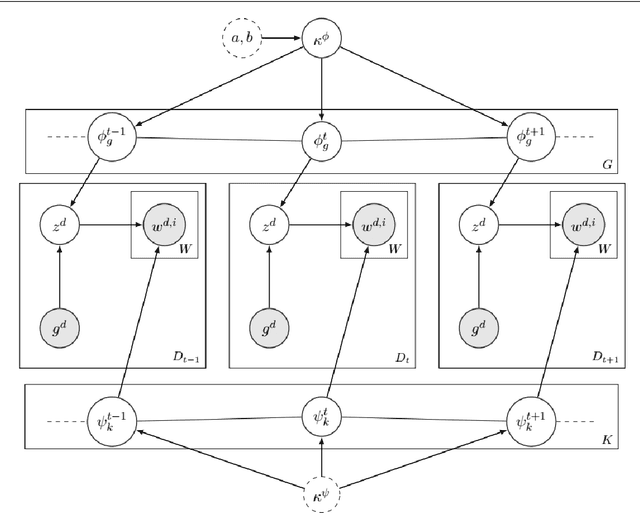
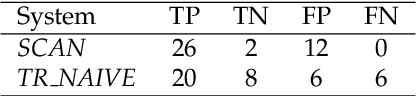
Change and its precondition, variation, are inherent in languages. Over time, new words enter the lexicon, others become obsolete, and existing words acquire new senses. Associating a word's correct meaning in its historical context is a central challenge in diachronic research. Historical corpora of classical languages, such as Ancient Greek and Latin, typically come with rich metadata, and existing models are limited by their inability to exploit contextual information beyond the document timestamp. While embedding-based methods feature among the current state of the art systems, they are lacking in the interpretative power. In contrast, Bayesian models provide explicit and interpretable representations of semantic change phenomena. In this chapter we build on GASC, a recent computational approach to semantic change based on a dynamic Bayesian mixture model. In this model, the evolution of word senses over time is based not only on distributional information of lexical nature, but also on text genres. We provide a systematic comparison of dynamic Bayesian mixture models for semantic change with state-of-the-art embedding-based models. On top of providing a full description of meaning change over time, we show that Bayesian mixture models are highly competitive approaches to detect binary semantic change in both Ancient Greek and Latin.
SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection
Aug 28, 2020
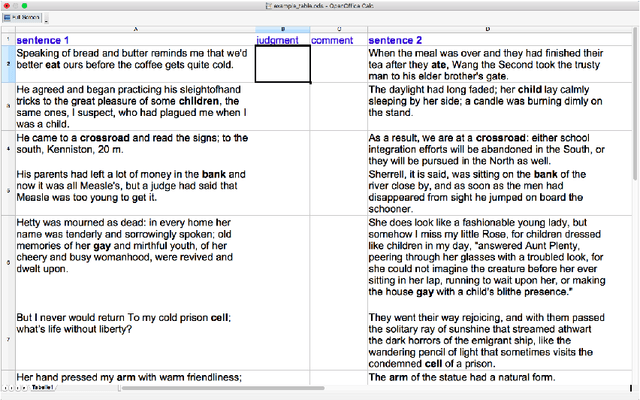
Lexical Semantic Change detection, i.e., the task of identifying words that change meaning over time, is a very active research area, with applications in NLP, lexicography, and linguistics. Evaluation is currently the most pressing problem in Lexical Semantic Change detection, as no gold standards are available to the community, which hinders progress. We present the results of the first shared task that addresses this gap by providing researchers with an evaluation framework and manually annotated, high-quality datasets for English, German, Latin, and Swedish. 33 teams submitted 186 systems, which were evaluated on two subtasks.
Living Machines: A study of atypical animacy
May 22, 2020
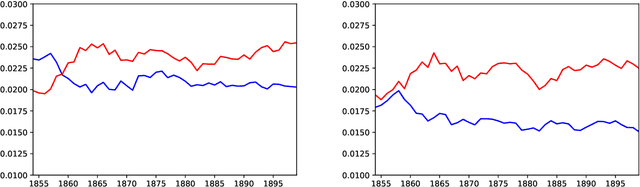


This paper proposes a new approach to animacy detection, the task of determining whether an entity is represented as animate in a text. In particular, this work is focused on atypical animacy and examines the scenario in which typically inanimate objects, specifically machines, are given animate attributes. To address it, we have created the first dataset for atypical animacy detection, based on nineteenth-century sentences in English, with machines represented as either animate or inanimate. Our method builds upon recent innovations in language modeling, specifically BERT contextualized word embeddings, to better capture fine-grained contextual properties of words. We present a fully unsupervised pipeline, which can be easily adapted to different contexts, and report its performance on an established animacy dataset and our newly introduced resource. We show that our method provides a substantially more accurate characterization of atypical animacy, especially when applied to highly complex forms of language use.
Analyzing Temporal Relationships between Trending Terms on Twitter and Urban Dictionary Activity
May 18, 2020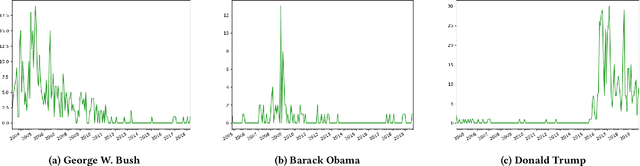
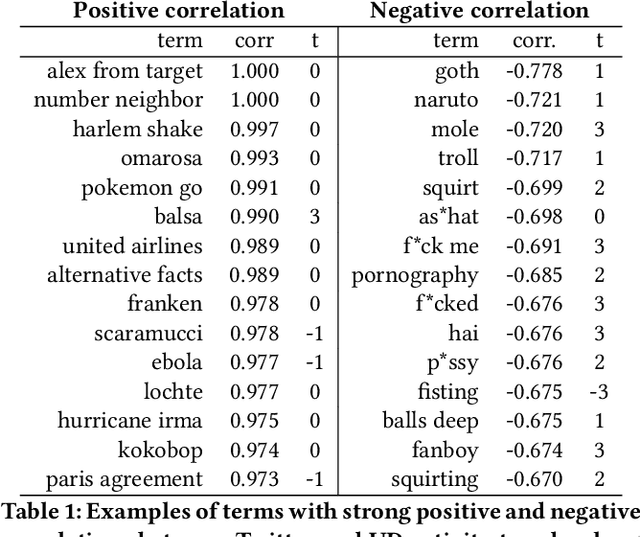

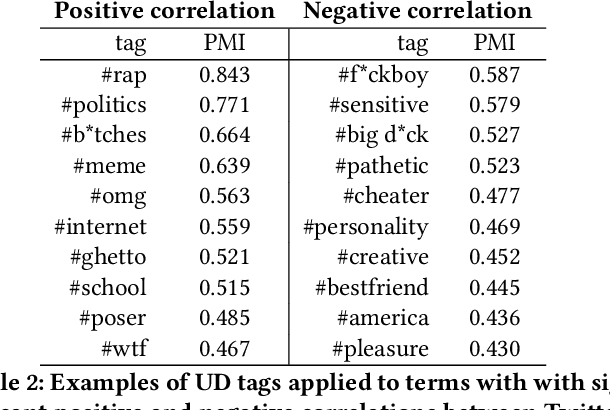
As an online, crowd-sourced, open English-language slang dictionary, the Urban Dictionary platform contains a wealth of opinions, jokes, and definitions of terms, phrases, acronyms, and more. However, it is unclear exactly how activity on this platform relates to larger conversations happening elsewhere on the web, such as discussions on larger, more popular social media platforms. In this research, we study the temporal activity trends on Urban Dictionary and provide the first analysis of how this activity relates to content being discussed on a major social network: Twitter. By collecting the whole of Urban Dictionary, as well as a large sample of tweets over seven years, we explore the connections between the words and phrases that are defined and searched for on Urban Dictionary and the content that is talked about on Twitter. Through a series of cross-correlation calculations, we identify cases in which Urban Dictionary activity closely reflects the larger conversation happening on Twitter. Then, we analyze the types of terms that have a stronger connection to discussions on Twitter, finding that Urban Dictionary activity that is positively correlated with Twitter is centered around terms related to memes, popular public figures, and offline events. Finally, We explore the relationship between periods of time when terms are trending on Twitter and the corresponding activity on Urban Dictionary, revealing that new definitions are more likely to be added to Urban Dictionary for terms that are currently trending on Twitter.
GASC: Genre-Aware Semantic Change for Ancient Greek
Mar 13, 2019

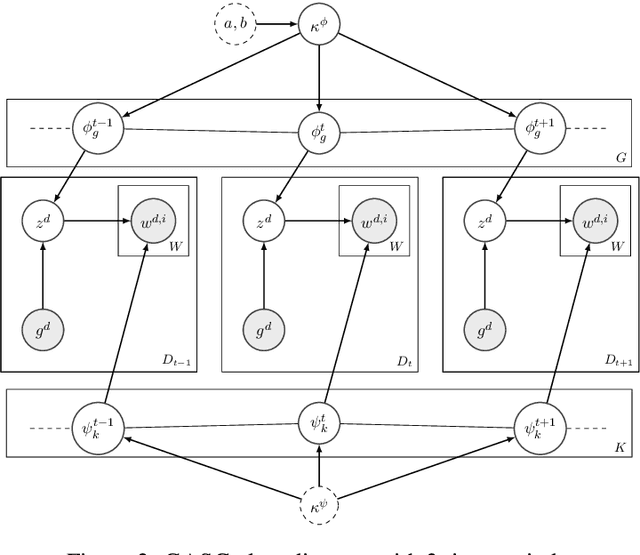

Word meaning changes over time, depending on linguistic and extra-linguistic factors. Associating a word's correct meaning in its historical context is a critical challenge in diachronic research, and is relevant to a range of NLP tasks, including information retrieval and semantic search in historical texts. Bayesian models for semantic change have emerged as a powerful tool to address this challenge, providing explicit and interpretable representations of semantic change phenomena. However, while corpora typically come with rich metadata, existing models are limited by their inability to exploit contextual information (such as text genre) beyond the document time-stamp. This is particularly critical in the case of ancient languages, where lack of data and long diachronic span make it harder to draw a clear distinction between polysemy and semantic change, and current systems perform poorly on these languages. We develop GASC, a dynamic semantic change model that leverages categorical metadata about the texts' genre information to boost inference and uncover the evolution of meanings in Ancient Greek corpora. In a new evaluation framework, we show that our model achieves improved predictive performance compared to the state of the art.