 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation
Sep 18, 2024



Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging Multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated through deployment on a large e-commerce platform, demonstrates comparable quality to human annotations, significantly reduces time and cost, facilitates rapid problem discovery, and provides an effective solution for production-level quality control at scale.
Faking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022
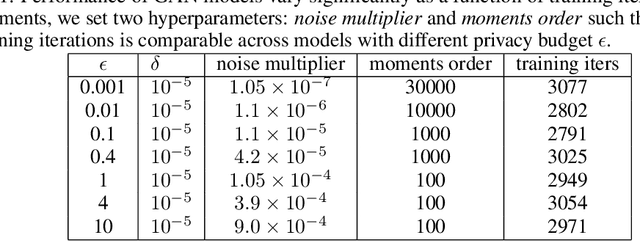

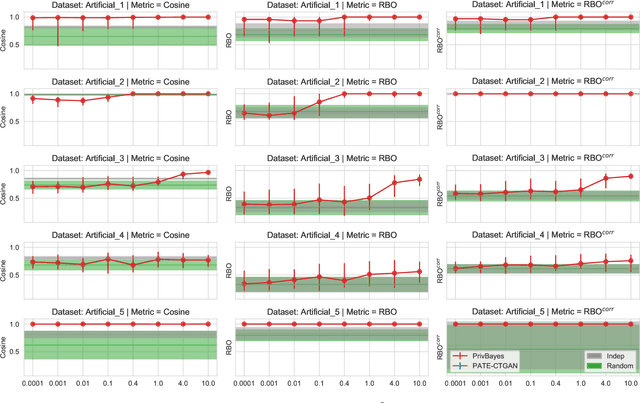
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
MapReader: A Computer Vision Pipeline for the Semantic Exploration of Maps at Scale
Nov 30, 2021



We present MapReader, a free, open-source software library written in Python for analyzing large map collections (scanned or born-digital). This library transforms the way historians can use maps by turning extensive, homogeneous map sets into searchable primary sources. MapReader allows users with little or no computer vision expertise to i) retrieve maps via web-servers; ii) preprocess and divide them into patches; iii) annotate patches; iv) train, fine-tune, and evaluate deep neural network models; and v) create structured data about map content. We demonstrate how MapReader enables historians to interpret a collection of $\approx$16K nineteenth-century Ordnance Survey map sheets ($\approx$30.5M patches), foregrounding the challenge of translating visual markers into machine-readable data. We present a case study focusing on British rail infrastructure and buildings as depicted on these maps. We also show how the outputs from the MapReader pipeline can be linked to other, external datasets, which we use to evaluate as well as enrich and interpret the results. We release $\approx$62K manually annotated patches used here for training and evaluating the models.
Neural Language Models for Nineteenth-Century English
May 24, 2021
We present four types of neural language models trained on a large historical dataset of books in English, published between 1760-1900 and comprised of ~5.1 billion tokens. The language model architectures include static (word2vec and fastText) and contextualized models (BERT and Flair). For each architecture, we trained a model instance using the whole dataset. Additionally, we trained separate instances on text published before 1850 for the two static models, and four instances considering different time slices for BERT. Our models have already been used in various downstream tasks where they consistently improved performance. In this paper, we describe how the models have been created and outline their reuse potential.
A Deep Learning Approach to Geographical Candidate Selection through Toponym Matching
Sep 22, 2020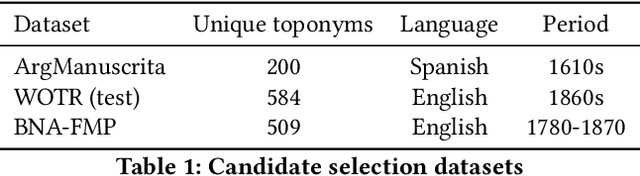
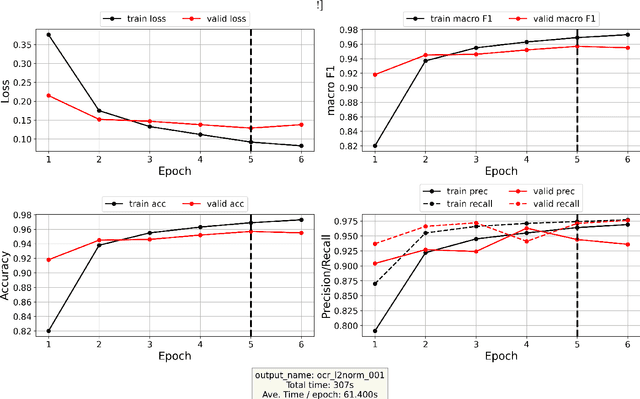
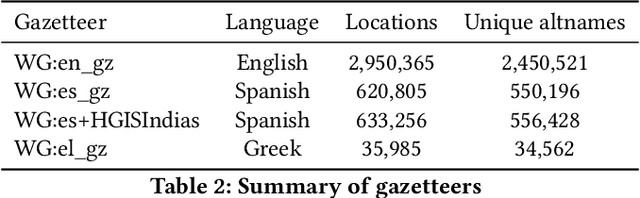
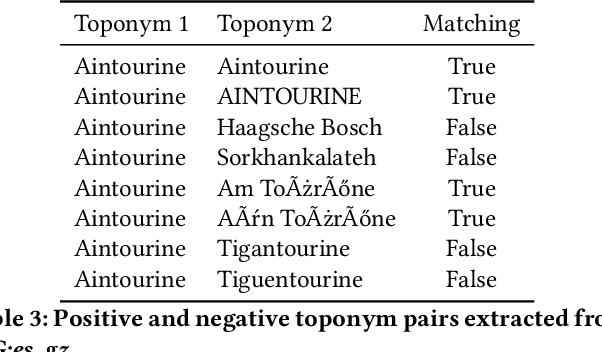
Recognizing toponyms and resolving them to their real-world referents is required for providing advanced semantic access to textual data. This process is often hindered by the high degree of variation in toponyms. Candidate selection is the task of identifying the potential entities that can be referred to by a toponym previously recognized. While it has traditionally received little attention in the research community, it has been shown that candidate selection has a significant impact on downstream tasks (i.e. entity resolution), especially in noisy or non-standard text. In this paper, we introduce a flexible deep learning method for candidate selection through toponym matching, using state-of-the-art neural network architectures. We perform an intrinsic toponym matching evaluation based on several new realistic datasets, which cover various challenging scenarios (cross-lingual and regional variations, as well as OCR errors). We report its performance on candidate selection in the context of the downstream task of toponym resolution, both on existing datasets and on a new manually-annotated resource of nineteenth-century English OCR'd text.
Living Machines: A study of atypical animacy
May 22, 2020


This paper proposes a new approach to animacy detection, the task of determining whether an entity is represented as animate in a text. In particular, this work is focused on atypical animacy and examines the scenario in which typically inanimate objects, specifically machines, are given animate attributes. To address it, we have created the first dataset for atypical animacy detection, based on nineteenth-century sentences in English, with machines represented as either animate or inanimate. Our method builds upon recent innovations in language modeling, specifically BERT contextualized word embeddings, to better capture fine-grained contextual properties of words. We present a fully unsupervised pipeline, which can be easily adapted to different contexts, and report its performance on an established animacy dataset and our newly introduced resource. We show that our method provides a substantially more accurate characterization of atypical animacy, especially when applied to highly complex forms of language use.