 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation
Sep 18, 2024



Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging Multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated through deployment on a large e-commerce platform, demonstrates comparable quality to human annotations, significantly reduces time and cost, facilitates rapid problem discovery, and provides an effective solution for production-level quality control at scale.
Grid Partitioned Attention: Efficient TransformerApproximation with Inductive Bias for High Resolution Detail Generation
Jul 08, 2021


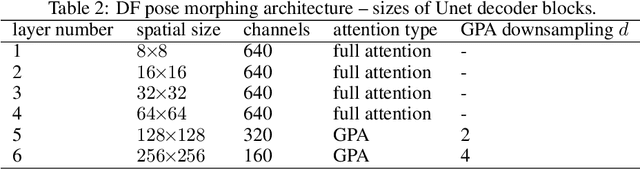
Attention is a general reasoning mechanism than can flexibly deal with image information, but its memory requirements had made it so far impractical for high resolution image generation. We present Grid Partitioned Attention (GPA), a new approximate attention algorithm that leverages a sparse inductive bias for higher computational and memory efficiency in image domains: queries attend only to few keys, spatially close queries attend to close keys due to correlations. Our paper introduces the new attention layer, analyzes its complexity and how the trade-off between memory usage and model power can be tuned by the hyper-parameters.We will show how such attention enables novel deep learning architectures with copying modules that are especially useful for conditional image generation tasks like pose morphing. Our contributions are (i) algorithm and code1of the novel GPA layer, (ii) a novel deep attention-copying architecture, and (iii) new state-of-the art experimental results in human pose morphing generation benchmarks.
Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting
Feb 02, 2021
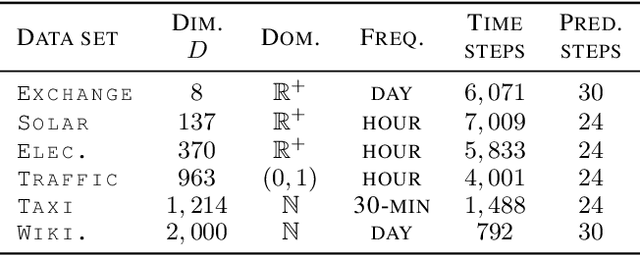


In this work, we propose \texttt{TimeGrad}, an autoregressive model for multivariate probabilistic time series forecasting which samples from the data distribution at each time step by estimating its gradient. To this end, we use diffusion probabilistic models, a class of latent variable models closely connected to score matching and energy-based methods. Our model learns gradients by optimizing a variational bound on the data likelihood and at inference time converts white noise into a sample of the distribution of interest through a Markov chain using Langevin sampling. We demonstrate experimentally that the proposed autoregressive denoising diffusion model is the new state-of-the-art multivariate probabilistic forecasting method on real-world data sets with thousands of correlated dimensions. We hope that this method is a useful tool for practitioners and lays the foundation for future research in this area.
CRISP: A Probabilistic Model for Individual-Level COVID-19 Infection Risk Estimation Based on Contact Data
Jun 09, 2020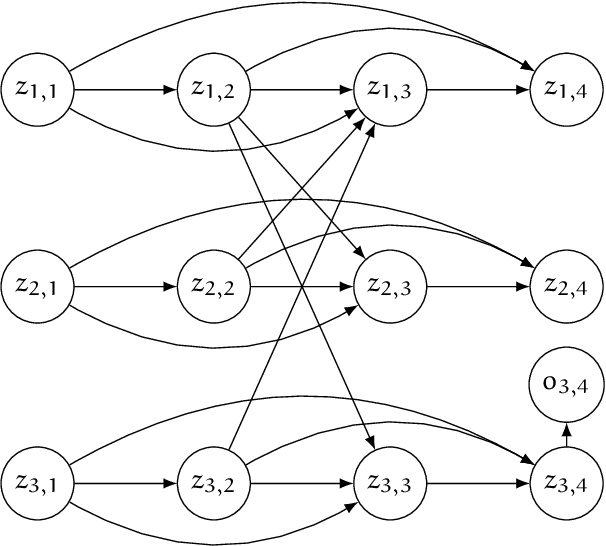

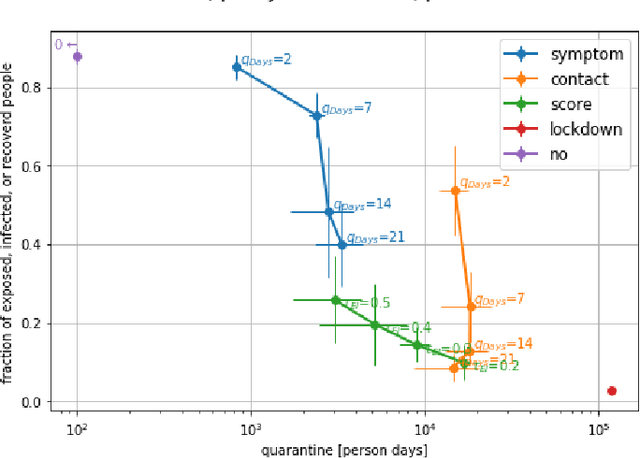
We present CRISP (COVID-19 Risk Score Prediction), a probabilistic graphical model for COVID-19 infection spread through a population based on the SEIR model where we assume access to (1) mutual contacts between pairs of individuals across time across various channels (e.g., Bluetooth contact traces), as well as (2) test outcomes at given times for infection, exposure and immunity tests. Our micro-level model keeps track of the infection state for each individual at every point in time, ranging from susceptible, exposed, infectious to recovered. We develop a Monte Carlo EM algorithm to infer contact-channel specific infection transmission probabilities. Our algorithm uses Gibbs sampling to draw samples of the latent infection status of each individual over the entire time period of analysis, given the latent infection status of all contacts and test outcome data. Experimental results with simulated data demonstrate our CRISP model can be parametrized by the reproduction factor $R_0$ and exhibits population-level infectiousness and recovery time series similar to those of the classical SEIR model. However, due to the individual contact data, this model allows fine grained control and inference for a wide range of COVID-19 mitigation and suppression policy measures. Moreover, the algorithm is able to support efficient testing in a test-trace-isolate approach to contain COVID-19 infection spread. To the best of our knowledge, this is the first model with efficient inference for COVID-19 infection spread based on individual-level contact data; most epidemic models are macro-level models that reason over entire populations. The implementation of CRISP is available in Python and C++ at https://github.com/zalandoresearch/CRISP.
Multi-variate Probabilistic Time Series Forecasting via Conditioned Normalizing Flows
Feb 14, 2020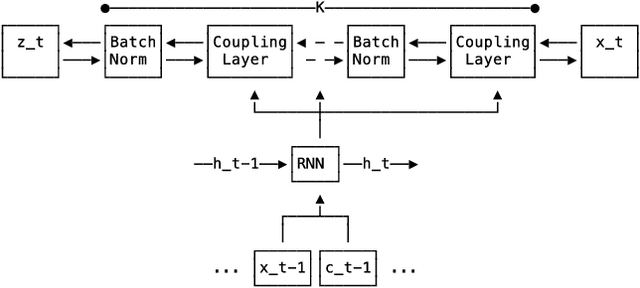

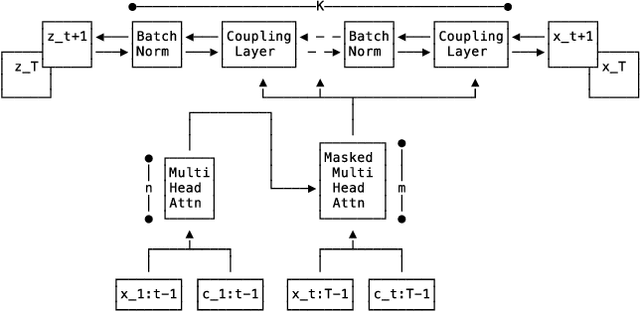
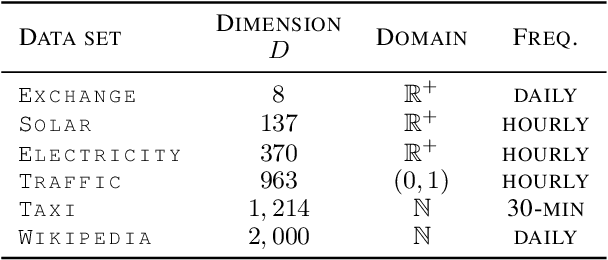
Time series forecasting is often fundamental to scientific and engineering problems and enables decision making. With ever increasing data set sizes, a trivial solution to scale up predictions is to assume independence between interacting time series. However, modeling statistical dependencies can improve accuracy and enable analysis of interaction effects. Deep learning methods are well suited for this problem, but multi-variate models often assume a simple parametric distribution and do not scale to high dimensions. In this work we model the multi-variate temporal dynamics of time series via an autoregressive deep learning model, where the data distribution is represented by a conditioned normalizing flow. This combination retains the power of autoregressive models, such as good performance in extrapolation into the future, with the flexibility of flows as a general purpose high-dimensional distribution model, while remaining computationally tractable. We show that it improves over the state-of-the-art for standard metrics on many real-world data sets with several thousand interacting time-series.
Set Flow: A Permutation Invariant Normalizing Flow
Sep 06, 2019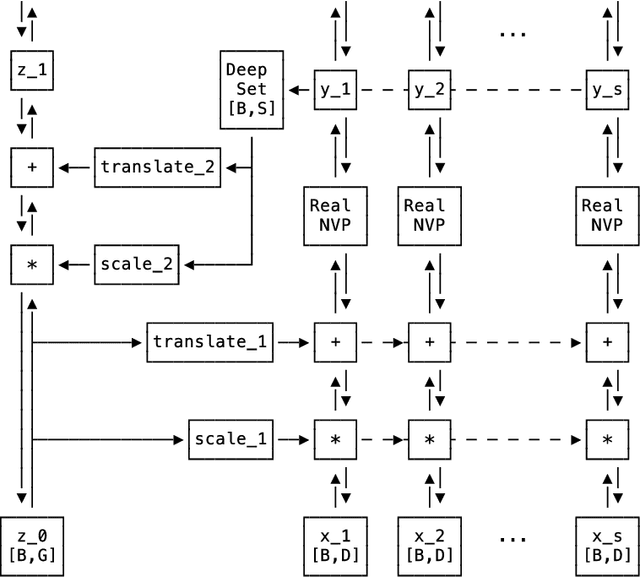
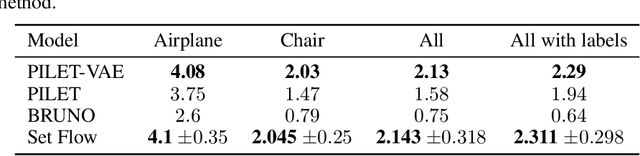
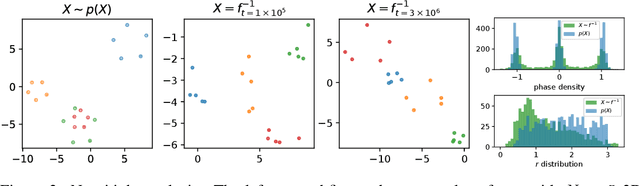
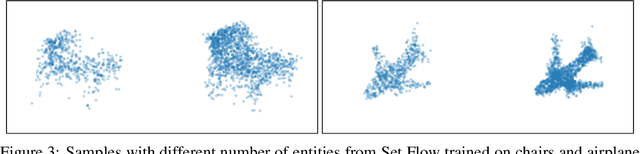
We present a generative model that is defined on finite sets of exchangeable, potentially high dimensional, data. As the architecture is an extension of RealNVPs, it inherits all its favorable properties, such as being invertible and allowing for exact log-likelihood evaluation. We show that this architecture is able to learn finite non-i.i.d. set data distributions, learn statistical dependencies between entities of the set and is able to train and sample with variable set sizes in a computationally efficient manner. Experiments on 3D point clouds show state-of-the art likelihoods.
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
Aug 23, 2019

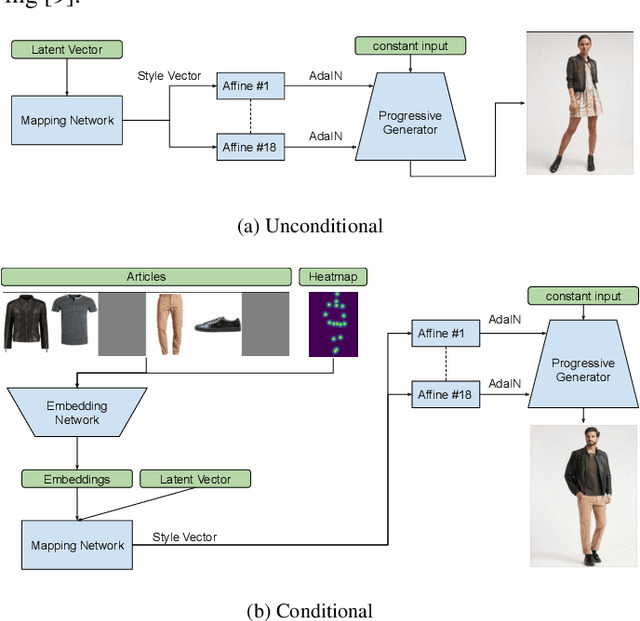

Visualizing an outfit is an essential part of shopping for clothes. Due to the combinatorial aspect of combining fashion articles, the available images are limited to a pre-determined set of outfits. In this paper, we broaden these visualizations by generating high-resolution images of fashion models wearing a custom outfit under an input body pose. We show that our approach can not only transfer the style and the pose of one generated outfit to another, but also create realistic images of human bodies and garments.
A Deep Learning System for Predicting Size and Fit in Fashion E-Commerce
Jul 23, 2019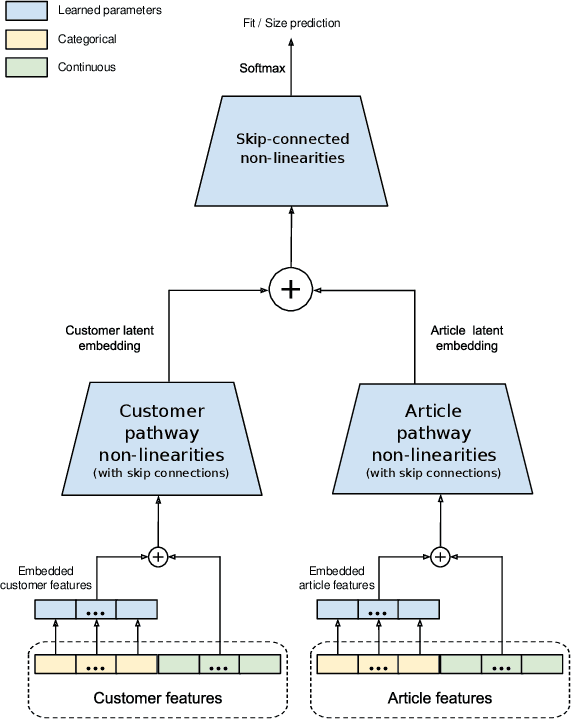
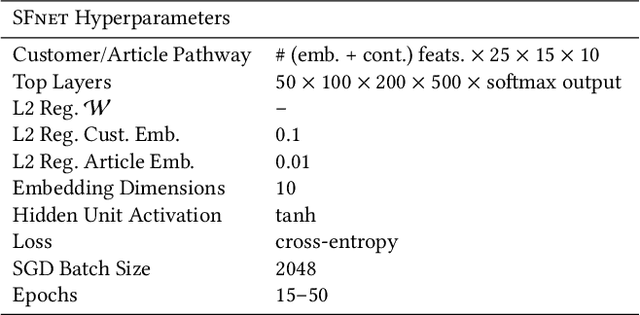
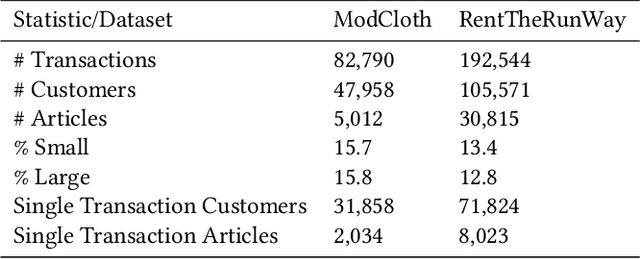
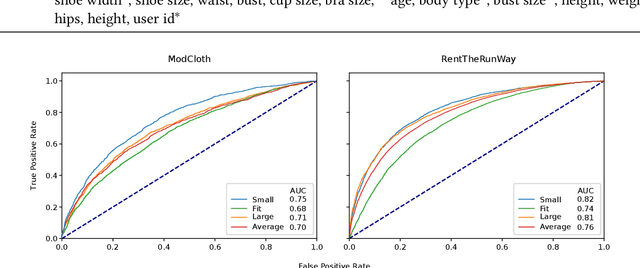
Personalized size and fit recommendations bear crucial significance for any fashion e-commerce platform. Predicting the correct fit drives customer satisfaction and benefits the business by reducing costs incurred due to size-related returns. Traditional collaborative filtering algorithms seek to model customer preferences based on their previous orders. A typical challenge for such methods stems from extreme sparsity of customer-article orders. To alleviate this problem, we propose a deep learning based content-collaborative methodology for personalized size and fit recommendation. Our proposed method can ingest arbitrary customer and article data and can model multiple individuals or intents behind a single account. The method optimizes a global set of parameters to learn population-level abstractions of size and fit relevant information from observed customer-article interactions. It further employs customer and article specific embedding variables to learn their properties. Together with learned entity embeddings, the method maps additional customer and article attributes into a latent space to derive personalized recommendations. Application of our method to two publicly available datasets demonstrate an improvement over the state-of-the-art published results. On two proprietary datasets, one containing fit feedback from fashion experts and the other involving customer purchases, we further outperform comparable methodologies, including a recent Bayesian approach for size recommendation.
Learning Set-equivariant Functions with SWARM Mappings
Jun 22, 2019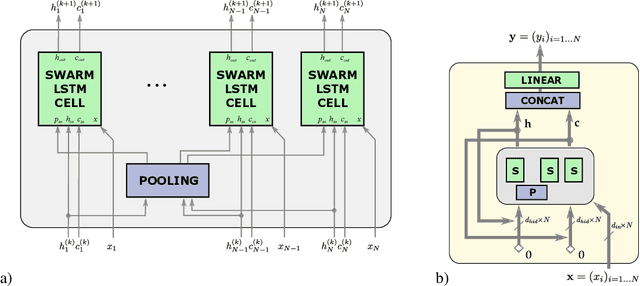
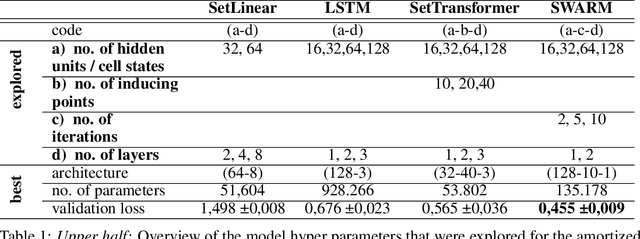


In this work we propose a new neural network architecture that efficiently implements and learns general purpose set-equivariant functions. Such a function $f$ maps a set of entities $x=\left\{ x_{1},\ldots,x_{n}\right\} $ from one domain to a set of same cardinality $y=f\left(x\right)=\left\{ y_{1},\ldots,y_{n}\right\} $ in another domain regardless of the ordering of the entities. The architecture is based on a gated recurrent network which is iteratively applied to all entities individually and at the same time syncs with the progression of the whole population. In reminiscence to this pattern, which can be frequently observable in nature, we call our approach SWARM mapping. Set-equivariant and generally permutation invariant functions are important building blocks for many state of the art machine learning approaches. Even in application where the permutation invariance is not of primary interest, as to be seen in the recent success of attention based transformer models (Vaswani et. al. 2017). Accordingly, we demonstrate the power and usefulness of SWARM mappings in different applications. We compare the performance of our approach with another recently proposed set-equivariant function, the SetTransformer (Lee et.al. 2018) and we demonstrate that transformer solely based on SWARM layers gives state of the art results.
A Bandit Framework for Optimal Selection of Reinforcement Learning Agents
Feb 10, 2019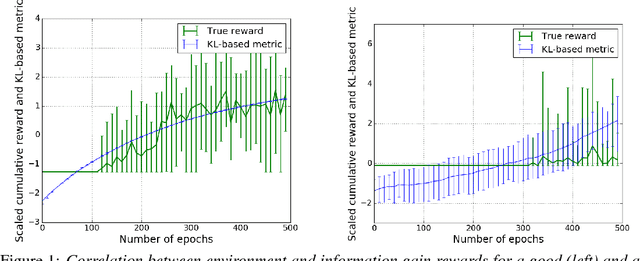
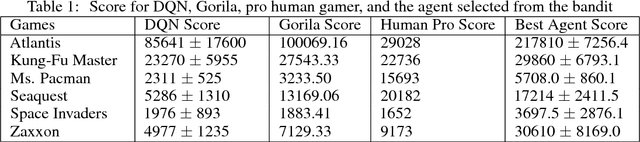
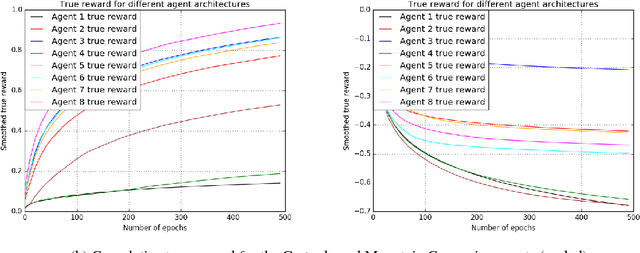
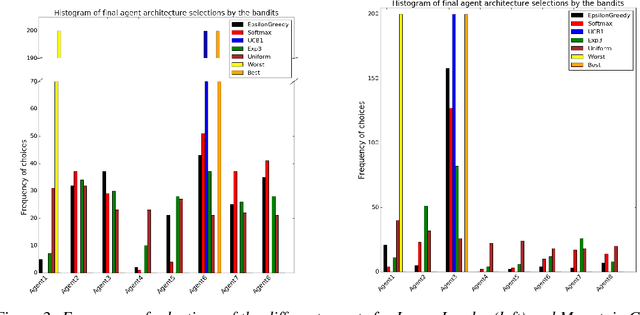
Deep Reinforcement Learning has been shown to be very successful in complex games, e.g. Atari or Go. These games have clearly defined rules, and hence allow simulation. In many practical applications, however, interactions with the environment are costly and a good simulator of the environment is not available. Further, as environments differ by application, the optimal inductive bias (architecture, hyperparameters, etc.) of a reinforcement agent depends on the application. In this work, we propose a multi-arm bandit framework that selects from a set of different reinforcement learning agents to choose the one with the best inductive bias. To alleviate the problem of sparse rewards, the reinforcement learning agents are augmented with surrogate rewards. This helps the bandit framework to select the best agents early, since these rewards are smoother and less sparse than the environment reward. The bandit has the double objective of maximizing the reward while the agents are learning and selecting the best agent after a finite number of learning steps. Our experimental results on standard environments show that the proposed framework is able to consistently select the optimal agent after a finite number of steps, while collecting more cumulative reward compared to selecting a sub-optimal architecture or uniformly alternating between different agents.