 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Message Passing for Bayesian Neural Networks
Jan 26, 2025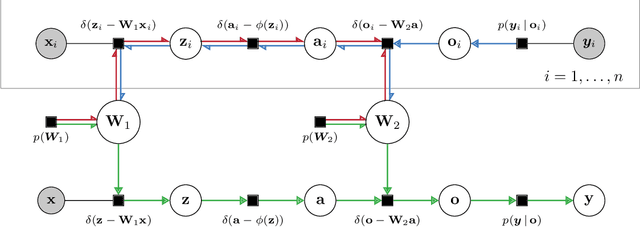
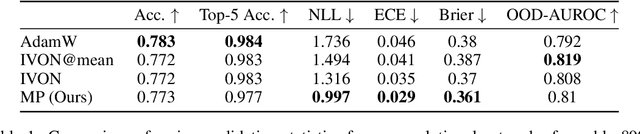
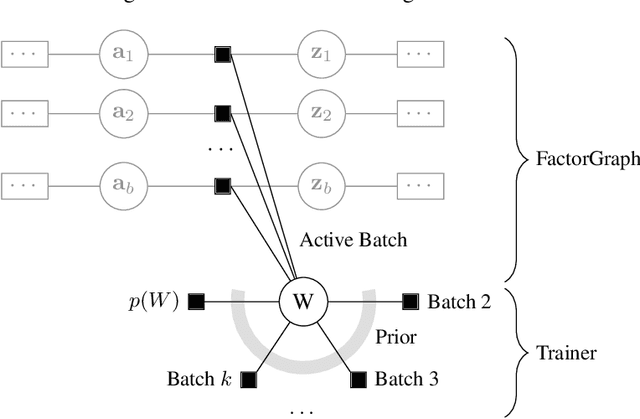
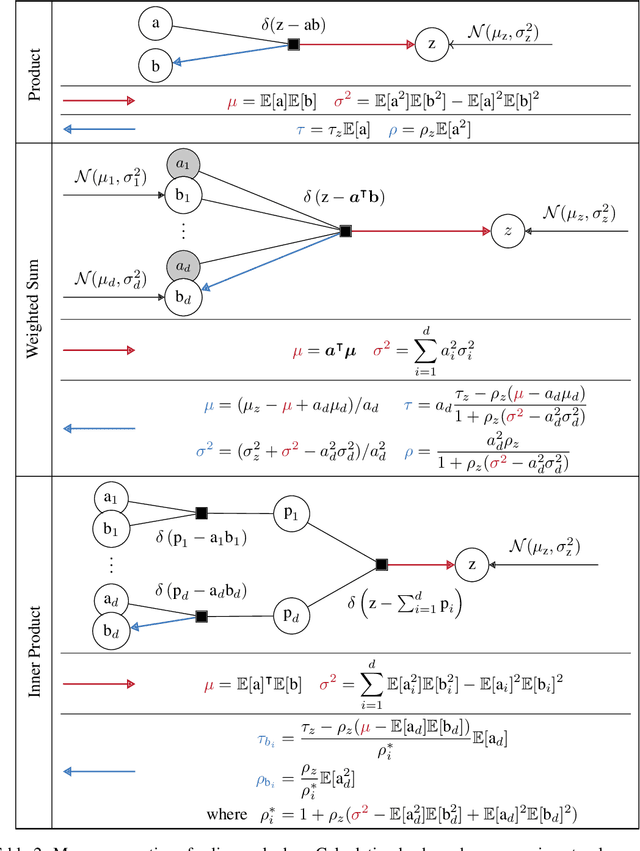
Bayesian neural networks (BNNs) offer the potential for reliable uncertainty quantification and interpretability, which are critical for trustworthy AI in high-stakes domains. However, existing methods often struggle with issues such as overconfidence, hyperparameter sensitivity, and posterior collapse, leaving room for alternative approaches. In this work, we advance message passing (MP) for BNNs and present a novel framework that models the predictive posterior as a factor graph. To the best of our knowledge, our framework is the first MP method that handles convolutional neural networks and avoids double-counting training data, a limitation of previous MP methods that causes overconfidence. We evaluate our approach on CIFAR-10 with a convolutional neural network of roughly 890k parameters and find that it can compete with the SOTA baselines AdamW and IVON, even having an edge in terms of calibration. On synthetic data, we validate the uncertainty estimates and observe a strong correlation (0.9) between posterior credible intervals and its probability of covering the true data-generating function outside the training range. While our method scales to an MLP with 5.6 million parameters, further improvements are necessary to match the scale and performance of state-of-the-art variational inference methods.
BALI: Learning Neural Networks via Bayesian Layerwise Inference
Nov 18, 2024We introduce a new method for learning Bayesian neural networks, treating them as a stack of multivariate Bayesian linear regression models. The main idea is to infer the layerwise posterior exactly if we know the target outputs of each layer. We define these pseudo-targets as the layer outputs from the forward pass, updated by the backpropagated gradients of the objective function. The resulting layerwise posterior is a matrix-normal distribution with a Kronecker-factorized covariance matrix, which can be efficiently inverted. Our method extends to the stochastic mini-batch setting using an exponential moving average over natural-parameter terms, thus gradually forgetting older data. The method converges in few iterations and performs as well as or better than leading Bayesian neural network methods on various regression, classification, and out-of-distribution detection benchmarks.
Learning to Predict Usage Options of Product Reviews with LLM-Generated Labels
Oct 16, 2024

Annotating large datasets can be challenging. However, crowd-sourcing is often expensive and can lack quality, especially for non-trivial tasks. We propose a method of using LLMs as few-shot learners for annotating data in a complex natural language task where we learn a standalone model to predict usage options for products from customer reviews. We also propose a new evaluation metric for this scenario, HAMS4, that can be used to compare a set of strings with multiple reference sets. Learning a custom model offers individual control over energy efficiency and privacy measures compared to using the LLM directly for the sequence-to-sequence task. We compare this data annotation approach with other traditional methods and demonstrate how LLMs can enable considerable cost savings. We find that the quality of the resulting data exceeds the level attained by third-party vendor services and that GPT-4-generated labels even reach the level of domain experts. We make the code and generated labels publicly available.
AI, Climate, and Regulation: From Data Centers to the AI Act
Oct 09, 2024

We live in a world that is experiencing an unprecedented boom of AI applications that increasingly penetrate and enhance all sectors of private and public life, from education, media, medicine, and mobility to the industrial and professional workspace, and -- potentially particularly consequentially -- robotics. As this world is simultaneously grappling with climate change, the climate and environmental implications of the development and use of AI have become an important subject of public and academic debate. In this paper, we aim to provide guidance on the climate-related regulation for data centers and AI specifically, and discuss how to operationalize these requirements. We also highlight challenges and room for improvement, and make a number of policy proposals to this end. In particular, we propose a specific interpretation of the AI Act to bring reporting on the previously unadressed energy consumption from AI inferences back into the scope. We also find that the AI Act fails to address indirect greenhouse gas emissions from AI applications. Furthermore, for the purpose of energy consumption reporting, we compare levels of measurement within data centers and recommend measurement at the cumulative server level. We also argue for an interpretation of the AI Act that includes environmental concerns in the mandatory risk assessment (sustainability risk assessment, SIA), and provide guidance on its operationalization. The EU data center regulation proves to be a good first step but requires further development by including binding renewable energy and efficiency targets for data centers. Overall, we make twelve concrete policy proposals, in four main areas: Energy and Environmental Reporting Obligations; Legal and Regulatory Clarifications; Transparency and Accountability Mechanisms; and Future Far-Reaching Measures beyond Transparency.
Hieros: Hierarchical Imagination on Structured State Space Sequence World Models
Oct 10, 2023One of the biggest challenges to modern deep reinforcement learning (DRL) algorithms is sample efficiency. Many approaches learn a world model in order to train an agent entirely in imagination, eliminating the need for direct environment interaction during training. However, these methods often suffer from either a lack of imagination accuracy, exploration capabilities, or runtime efficiency. We propose Hieros, a hierarchical policy that learns time abstracted world representations and imagines trajectories at multiple time scales in latent space. Hieros uses an S5 layer-based world model, which predicts next world states in parallel during training and iteratively during environment interaction. Due to the special properties of S5 layers, our method can train in parallel and predict next world states iteratively during imagination. This allows for more efficient training than RNN-based world models and more efficient imagination than Transformer-based world models. We show that our approach outperforms the state of the art in terms of mean and median normalized human score on the Atari 100k benchmark, and that our proposed world model is able to predict complex dynamics very accurately. We also show that Hieros displays superior exploration capabilities compared to existing approaches.
On the detrimental effect of invariances in the likelihood for variational inference
Sep 15, 2022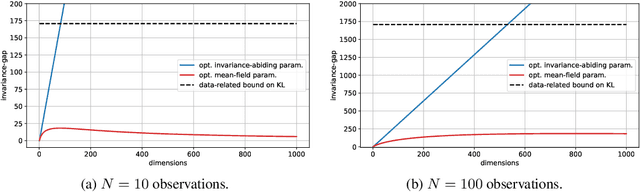
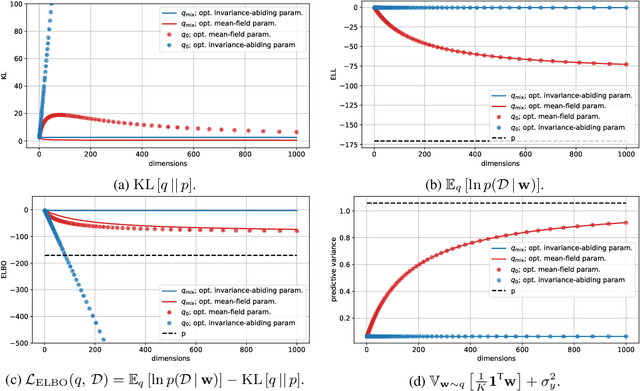
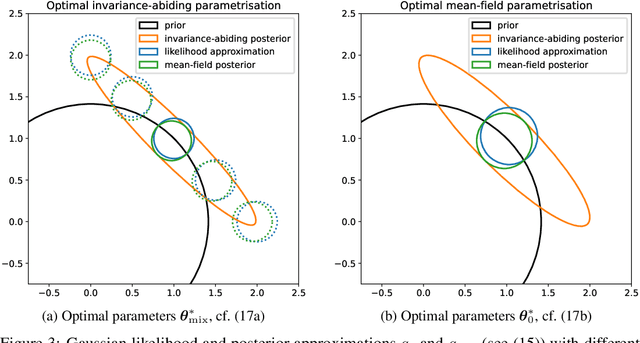
Variational Bayesian posterior inference often requires simplifying approximations such as mean-field parametrisation to ensure tractability. However, prior work has associated the variational mean-field approximation for Bayesian neural networks with underfitting in the case of small datasets or large model sizes. In this work, we show that invariances in the likelihood function of over-parametrised models contribute to this phenomenon because these invariances complicate the structure of the posterior by introducing discrete and/or continuous modes which cannot be well approximated by Gaussian mean-field distributions. In particular, we show that the mean-field approximation has an additional gap in the evidence lower bound compared to a purpose-built posterior that takes into account the known invariances. Importantly, this invariance gap is not constant; it vanishes as the approximation reverts to the prior. We proceed by first considering translation invariances in a linear model with a single data point in detail. We show that, while the true posterior can be constructed from a mean-field parametrisation, this is achieved only if the objective function takes into account the invariance gap. Then, we transfer our analysis of the linear model to neural networks. Our analysis provides a framework for future work to explore solutions to the invariance problem.
A PAC-Bayesian Analysis of Distance-Based Classifiers: Why Nearest-Neighbour works!
Sep 28, 2021


Abstract We present PAC-Bayesian bounds for the generalisation error of the K-nearest-neighbour classifier (K-NN). This is achieved by casting the K-NN classifier into a kernel space framework in the limit of vanishing kernel bandwidth. We establish a relation between prior measures over the coefficients in the kernel expansion and the induced measure on the weight vectors in kernel space. Defining a sparse prior over the coefficients allows the application of a PAC-Bayesian folk theorem that leads to a generalisation bound that is a function of the number of redundant training examples: those that can be left out without changing the solution. The presented bound requires to quantify a prior belief in the sparseness of the solution and is evaluated after learning when the actual redundancy level is known. Even for small sample size (m ~ 100) the bound gives non-trivial results when both the expected sparseness and the actual redundancy are high.
CRISP: A Probabilistic Model for Individual-Level COVID-19 Infection Risk Estimation Based on Contact Data
Jun 09, 2020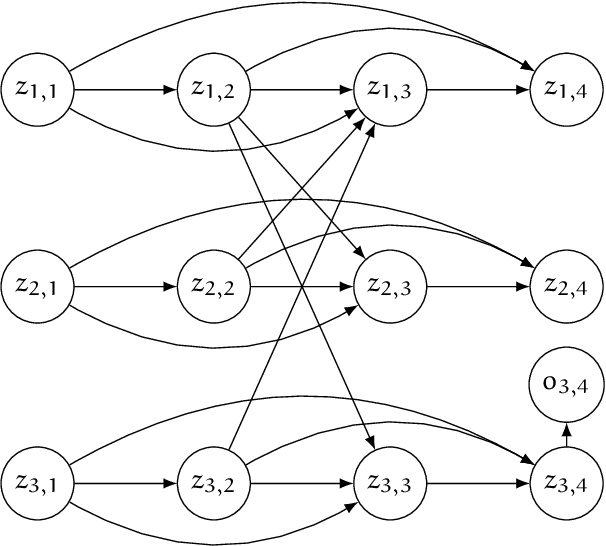

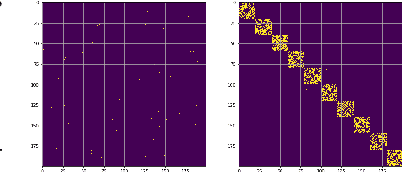
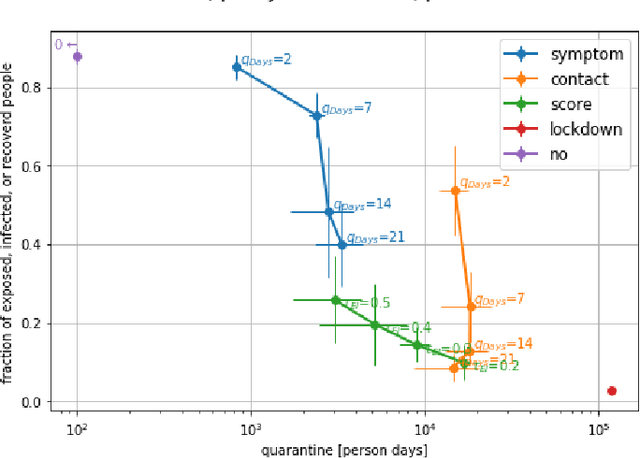
We present CRISP (COVID-19 Risk Score Prediction), a probabilistic graphical model for COVID-19 infection spread through a population based on the SEIR model where we assume access to (1) mutual contacts between pairs of individuals across time across various channels (e.g., Bluetooth contact traces), as well as (2) test outcomes at given times for infection, exposure and immunity tests. Our micro-level model keeps track of the infection state for each individual at every point in time, ranging from susceptible, exposed, infectious to recovered. We develop a Monte Carlo EM algorithm to infer contact-channel specific infection transmission probabilities. Our algorithm uses Gibbs sampling to draw samples of the latent infection status of each individual over the entire time period of analysis, given the latent infection status of all contacts and test outcome data. Experimental results with simulated data demonstrate our CRISP model can be parametrized by the reproduction factor $R_0$ and exhibits population-level infectiousness and recovery time series similar to those of the classical SEIR model. However, due to the individual contact data, this model allows fine grained control and inference for a wide range of COVID-19 mitigation and suppression policy measures. Moreover, the algorithm is able to support efficient testing in a test-trace-isolate approach to contain COVID-19 infection spread. To the best of our knowledge, this is the first model with efficient inference for COVID-19 infection spread based on individual-level contact data; most epidemic models are macro-level models that reason over entire populations. The implementation of CRISP is available in Python and C++ at https://github.com/zalandoresearch/CRISP.
Kernel Topic Models
Oct 21, 2011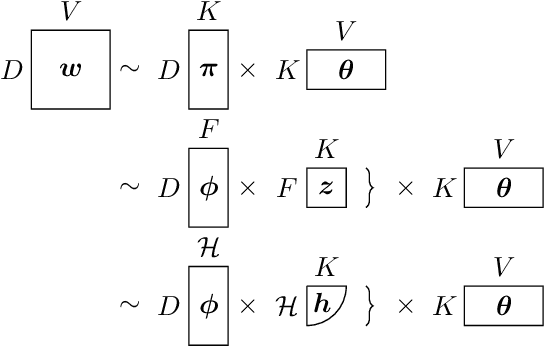
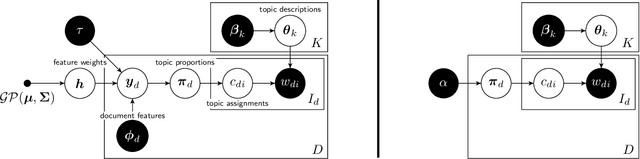
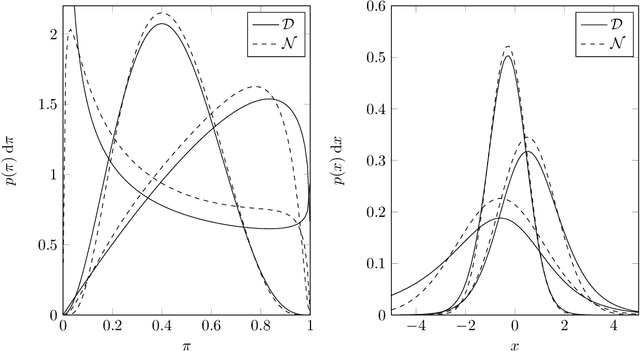
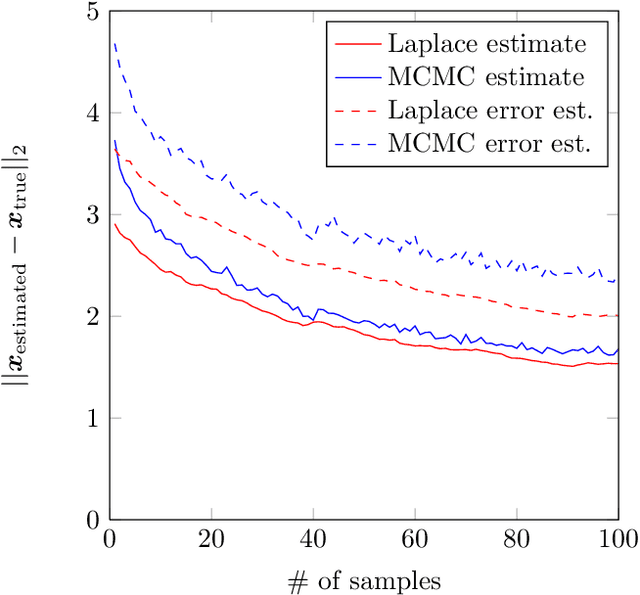
Latent Dirichlet Allocation models discrete data as a mixture of discrete distributions, using Dirichlet beliefs over the mixture weights. We study a variation of this concept, in which the documents' mixture weight beliefs are replaced with squashed Gaussian distributions. This allows documents to be associated with elements of a Hilbert space, admitting kernel topic models (KTM), modelling temporal, spatial, hierarchical, social and other structure between documents. The main challenge is efficient approximate inference on the latent Gaussian. We present an approximate algorithm cast around a Laplace approximation in a transformed basis. The KTM can also be interpreted as a type of Gaussian process latent variable model, or as a topic model conditional on document features, uncovering links between earlier work in these areas.