 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Predict Usage Options of Product Reviews with LLM-Generated Labels
Oct 16, 2024

Annotating large datasets can be challenging. However, crowd-sourcing is often expensive and can lack quality, especially for non-trivial tasks. We propose a method of using LLMs as few-shot learners for annotating data in a complex natural language task where we learn a standalone model to predict usage options for products from customer reviews. We also propose a new evaluation metric for this scenario, HAMS4, that can be used to compare a set of strings with multiple reference sets. Learning a custom model offers individual control over energy efficiency and privacy measures compared to using the LLM directly for the sequence-to-sequence task. We compare this data annotation approach with other traditional methods and demonstrate how LLMs can enable considerable cost savings. We find that the quality of the resulting data exceeds the level attained by third-party vendor services and that GPT-4-generated labels even reach the level of domain experts. We make the code and generated labels publicly available.
CommitBench: A Benchmark for Commit Message Generation
Mar 08, 2024Writing commit messages is a tedious daily task for many software developers, and often remains neglected. Automating this task has the potential to save time while ensuring that messages are informative. A high-quality dataset and an objective benchmark are vital preconditions for solid research and evaluation towards this goal. We show that existing datasets exhibit various problems, such as the quality of the commit selection, small sample sizes, duplicates, privacy issues, and missing licenses for redistribution. This can lead to unusable models and skewed evaluations, where inferior models achieve higher evaluation scores due to biases in the data. We compile a new large-scale dataset, CommitBench, adopting best practices for dataset creation. We sample commits from diverse projects with licenses that permit redistribution and apply our filtering and dataset enhancements to improve the quality of generated commit messages. We use CommitBench to compare existing models and show that other approaches are outperformed by a Transformer model pretrained on source code. We hope to accelerate future research by publishing the source code( https://github.com/Maxscha/commitbench ).
NextLevelBERT: Investigating Masked Language Modeling with Higher-Level Representations for Long Documents
Feb 27, 2024While (large) language models have significantly improved over the last years, they still struggle to sensibly process long sequences found, e.g., in books, due to the quadratic scaling of the underlying attention mechanism. To address this, we propose NextLevelBERT, a Masked Language Model operating not on tokens, but on higher-level semantic representations in the form of text embeddings. We pretrain NextLevelBERT to predict the vector representation of entire masked text chunks and evaluate the effectiveness of the resulting document vectors on three task types: 1) Semantic Textual Similarity via zero-shot document embeddings, 2) Long document classification, 3) Multiple-choice question answering. We find that next level Masked Language Modeling is an effective technique to tackle long-document use cases and can outperform much larger embedding models as long as the required level of detail is not too high. We make model and code available.
Scientific and Creative Analogies in Pretrained Language Models
Nov 28, 2022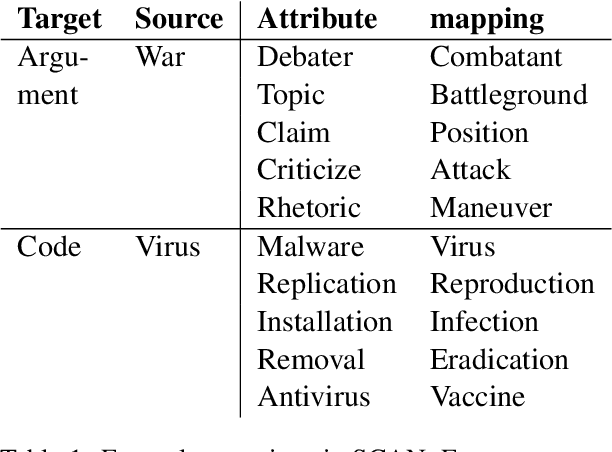
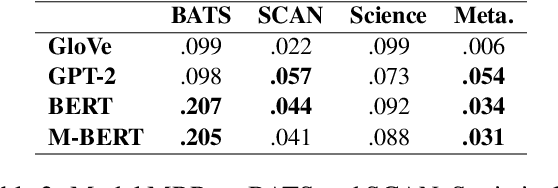
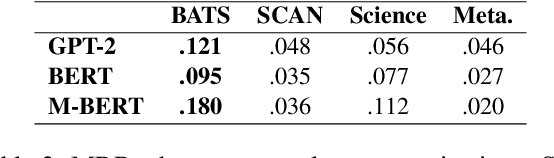
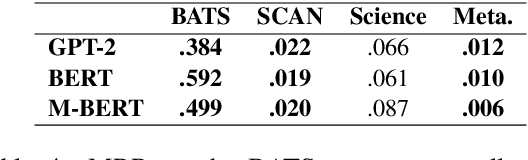
This paper examines the encoding of analogy in large-scale pretrained language models, such as BERT and GPT-2. Existing analogy datasets typically focus on a limited set of analogical relations, with a high similarity of the two domains between which the analogy holds. As a more realistic setup, we introduce the Scientific and Creative Analogy dataset (SCAN), a novel analogy dataset containing systematic mappings of multiple attributes and relational structures across dissimilar domains. Using this dataset, we test the analogical reasoning capabilities of several widely-used pretrained language models (LMs). We find that state-of-the-art LMs achieve low performance on these complex analogy tasks, highlighting the challenges still posed by analogy understanding.