 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonRL: Reinforcement Learning with Intermediate Rewards for Interpretable Fine-Grained Visual Reasoning
Mar 04, 2026Traditional vision-language models struggle with contrastive fine-grained taxonomic reasoning, particularly when distinguishing between visually similar species within the same genus or family. We introduce TaxonRL, a reinforcement learning approach using Group Relative Policy Optimization with intermediate rewards that decomposes the reasoning process into hierarchical taxonomic predictions. Our method incentivizes models to explicitly reason about species-level, genus-level, and family-level features before making final classifications. This structured approach is designed not only to boost accuracy but also to yield a transparent, verifiable decision-making process. On the challenging Birds-to-Words dataset, TaxonRL achieves 91.7\% average accuracy, exceeding human performance (77.3\%) while generating interpretable reasoning traces. We demonstrate strong cross-domain generalization, showing substantial gains in primate and marine species verification. Our results establish that enforcing structured, hierarchical reasoning provides a powerful and transferable framework for fine-grained visual discrimination.
GorillaWatch: An Automated System for In-the-Wild Gorilla Re-Identification and Population Monitoring
Dec 08, 2025
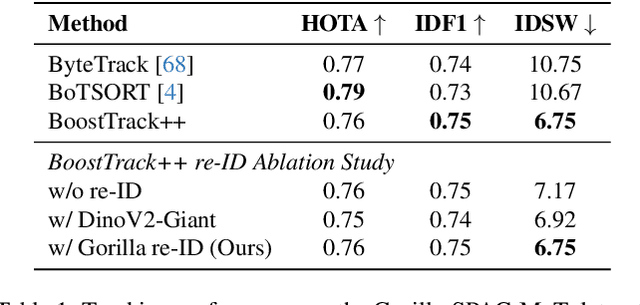

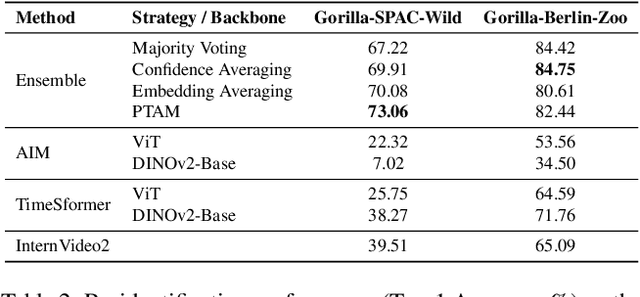
Monitoring critically endangered western lowland gorillas is currently hampered by the immense manual effort required to re-identify individuals from vast archives of camera trap footage. The primary obstacle to automating this process has been the lack of large-scale, "in-the-wild" video datasets suitable for training robust deep learning models. To address this gap, we introduce a comprehensive benchmark with three novel datasets: Gorilla-SPAC-Wild, the largest video dataset for wild primate re-identification to date; Gorilla-Berlin-Zoo, for assessing cross-domain re-identification generalization; and Gorilla-SPAC-MoT, for evaluating multi-object tracking in camera trap footage. Building on these datasets, we present GorillaWatch, an end-to-end pipeline integrating detection, tracking, and re-identification. To exploit temporal information, we introduce a multi-frame self-supervised pretraining strategy that leverages consistency in tracklets to learn domain-specific features without manual labels. To ensure scientific validity, a differentiable adaptation of AttnLRP verifies that our model relies on discriminative biometric traits rather than background correlations. Extensive benchmarking subsequently demonstrates that aggregating features from large-scale image backbones outperforms specialized video architectures. Finally, we address unsupervised population counting by integrating spatiotemporal constraints into standard clustering to mitigate over-segmentation. We publicly release all code and datasets to facilitate scalable, non-invasive monitoring of endangered species
CommitBench: A Benchmark for Commit Message Generation
Mar 08, 2024Writing commit messages is a tedious daily task for many software developers, and often remains neglected. Automating this task has the potential to save time while ensuring that messages are informative. A high-quality dataset and an objective benchmark are vital preconditions for solid research and evaluation towards this goal. We show that existing datasets exhibit various problems, such as the quality of the commit selection, small sample sizes, duplicates, privacy issues, and missing licenses for redistribution. This can lead to unusable models and skewed evaluations, where inferior models achieve higher evaluation scores due to biases in the data. We compile a new large-scale dataset, CommitBench, adopting best practices for dataset creation. We sample commits from diverse projects with licenses that permit redistribution and apply our filtering and dataset enhancements to improve the quality of generated commit messages. We use CommitBench to compare existing models and show that other approaches are outperformed by a Transformer model pretrained on source code. We hope to accelerate future research by publishing the source code( https://github.com/Maxscha/commitbench ).
NextLevelBERT: Investigating Masked Language Modeling with Higher-Level Representations for Long Documents
Feb 27, 2024While (large) language models have significantly improved over the last years, they still struggle to sensibly process long sequences found, e.g., in books, due to the quadratic scaling of the underlying attention mechanism. To address this, we propose NextLevelBERT, a Masked Language Model operating not on tokens, but on higher-level semantic representations in the form of text embeddings. We pretrain NextLevelBERT to predict the vector representation of entire masked text chunks and evaluate the effectiveness of the resulting document vectors on three task types: 1) Semantic Textual Similarity via zero-shot document embeddings, 2) Long document classification, 3) Multiple-choice question answering. We find that next level Masked Language Modeling is an effective technique to tackle long-document use cases and can outperform much larger embedding models as long as the required level of detail is not too high. We make model and code available.
Efficient Parallelization Layouts for Large-Scale Distributed Model Training
Nov 09, 2023



Efficiently training large language models requires parallelizing across hundreds of hardware accelerators and invoking various compute and memory optimizations. When combined, many of these strategies have complex interactions regarding the final training efficiency. Prior work tackling this problem did not have access to the latest set of optimizations, such as FlashAttention or sequence parallelism. In this work, we conduct a comprehensive ablation study of possible training configurations for large language models. We distill this large study into several key recommendations for the most efficient training. For instance, we find that using a micro-batch size of 1 usually enables the most efficient training layouts. Larger micro-batch sizes necessitate activation checkpointing or higher degrees of model parallelism and also lead to larger pipeline bubbles. Our most efficient configurations enable us to achieve state-of-the-art training efficiency results over a range of model sizes, most notably a Model FLOPs utilization of 70.5% when training a 13B model.