 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
AweDist: Attention-aware Embedding Distillation for New Input Token Embeddings
May 26, 2025Current language models rely on static vocabularies determined at pretraining time, which can lead to decreased performance and increased computational cost for domains underrepresented in the original vocabulary. New tokens can be added to solve this problem, when coupled with a good initialization for their new embeddings. However, existing embedding initialization methods either require expensive further training or pretraining of additional modules. In this paper, we propose AweDist and show that by distilling representations obtained using the original tokenization, we can quickly learn high-quality input embeddings for new tokens. Experimental results with a wide range of open-weight models show that AweDist is able to outperform even strong baselines.
I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token
Dec 09, 2024![Figure 1 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F6-Table2-1.png&w=640&q=75)
![Figure 4 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F6-Figure2-1.png&w=640&q=75)
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we propose a novel calibration method that can be used to combat hallucinations. We add a special [IDK] ("I don't know") token to the model's vocabulary and introduce an objective function that shifts probability mass to the [IDK] token for incorrect predictions. This approach allows the model to express uncertainty in its output explicitly. We evaluate our proposed method across multiple model architectures and factual downstream tasks. We find that models trained with our method are able to express uncertainty in places where they would previously make mistakes while suffering only a small loss of encoded knowledge. We further perform extensive ablation studies of multiple variations of our approach and provide a detailed analysis of the precision-recall tradeoff of our method.
Language Adaptation on a Tight Academic Compute Budget: Tokenizer Swapping Works and Pure bfloat16 Is Enough
Aug 28, 2024We investigate continued pretraining of LLMs for language adaptation on a tight academic budget: a setting in which only a few GPUs can be used in parallel, for a heavily constrained duration. We focus on adapting Mistral-7B to German or Arabic and evaluate several techniques to improve efficiency and effectiveness in this setting. Our German models adapted on this tight compute budget underperform compared to the base Mistral-7B, while our Arabic models outperform several baselines, showing that for sufficiently well-represented languages, continued pretraining for specialization is not always helpful. Our main findings focus on training precision and tokenizer swapping. Our results show that pure bfloat16 training is a viable alternative to mixed-precision training, while being much faster when only using a few GPUs. Swapping the tokenizer for a specialized one yields more efficient tokenization and is competitive with the original tokenizer, which already contains some German tokens, but did not significantly increase performance for German. Code and model weights are available at on GitHub.
Efficient Parallelization Layouts for Large-Scale Distributed Model Training
Nov 09, 2023Efficiently training large language models requires parallelizing across hundreds of hardware accelerators and invoking various compute and memory optimizations. When combined, many of these strategies have complex interactions regarding the final training efficiency. Prior work tackling this problem did not have access to the latest set of optimizations, such as FlashAttention or sequence parallelism. In this work, we conduct a comprehensive ablation study of possible training configurations for large language models. We distill this large study into several key recommendations for the most efficient training. For instance, we find that using a micro-batch size of 1 usually enables the most efficient training layouts. Larger micro-batch sizes necessitate activation checkpointing or higher degrees of model parallelism and also lead to larger pipeline bubbles. Our most efficient configurations enable us to achieve state-of-the-art training efficiency results over a range of model sizes, most notably a Model FLOPs utilization of 70.5% when training a 13B model.
FOCUS: Effective Embedding Initialization for Specializing Pretrained Multilingual Models on a Single Language
May 23, 2023Using model weights pretrained on a high-resource language as a warm start can reduce the need for data and compute to obtain high-quality language models in low-resource languages. To accommodate the new language, the pretrained vocabulary and embeddings need to be adapted. Previous work on embedding initialization for such adapted vocabularies has mostly focused on monolingual source models. In this paper, we investigate the multilingual source model setting and propose FOCUS - Fast Overlapping Token Combinations Using Sparsemax, a novel embedding initialization method that outperforms previous work when adapting XLM-R. FOCUS represents newly added tokens as combinations of tokens in the overlap of the pretrained and new vocabularies. The overlapping tokens are selected based on semantic similarity in an auxiliary token embedding space. Our implementation of FOCUS is publicly available on GitHub.
Art Creation with Multi-Conditional StyleGANs
Feb 23, 2022
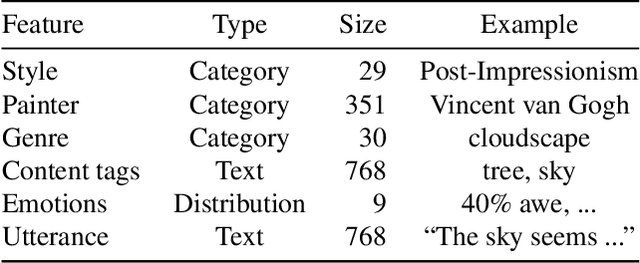
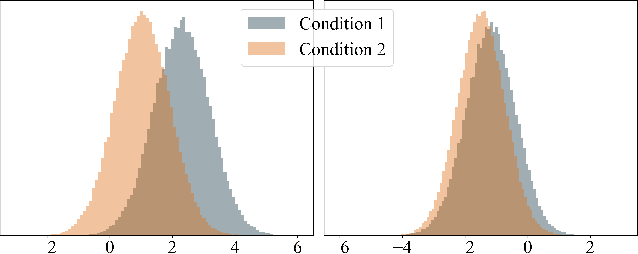
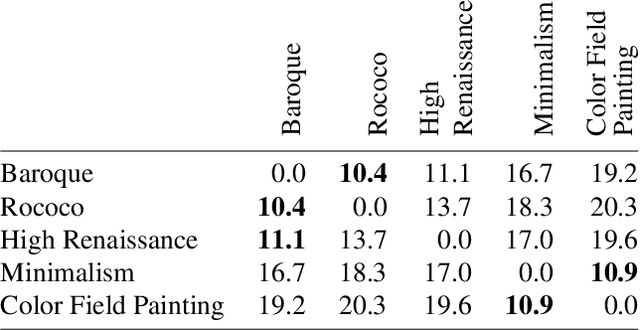
Creating meaningful art is often viewed as a uniquely human endeavor. A human artist needs a combination of unique skills, understanding, and genuine intention to create artworks that evoke deep feelings and emotions. In this paper, we introduce a multi-conditional Generative Adversarial Network (GAN) approach trained on large amounts of human paintings to synthesize realistic-looking paintings that emulate human art. Our approach is based on the StyleGAN neural network architecture, but incorporates a custom multi-conditional control mechanism that provides fine-granular control over characteristics of the generated paintings, e.g., with regard to the perceived emotion evoked in a spectator. For better control, we introduce the conditional truncation trick, which adapts the standard truncation trick for the conditional setting and diverse datasets. Finally, we develop a diverse set of evaluation techniques tailored to multi-conditional generation.