 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArt Creation with Multi-Conditional StyleGANs
Feb 23, 2022
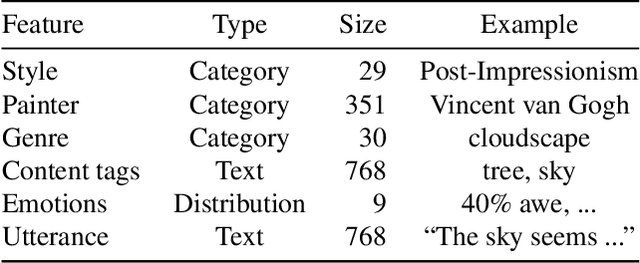
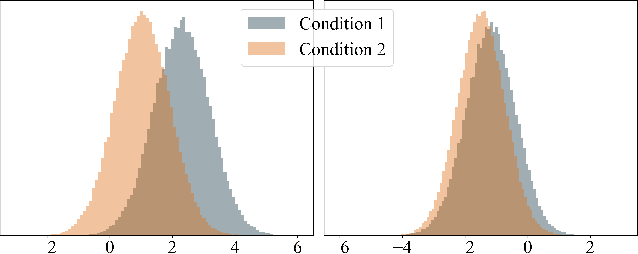
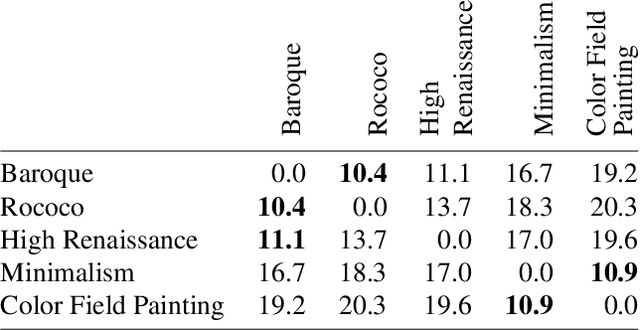
Creating meaningful art is often viewed as a uniquely human endeavor. A human artist needs a combination of unique skills, understanding, and genuine intention to create artworks that evoke deep feelings and emotions. In this paper, we introduce a multi-conditional Generative Adversarial Network (GAN) approach trained on large amounts of human paintings to synthesize realistic-looking paintings that emulate human art. Our approach is based on the StyleGAN neural network architecture, but incorporates a custom multi-conditional control mechanism that provides fine-granular control over characteristics of the generated paintings, e.g., with regard to the perceived emotion evoked in a spectator. For better control, we introduce the conditional truncation trick, which adapts the standard truncation trick for the conditional setting and diverse datasets. Finally, we develop a diverse set of evaluation techniques tailored to multi-conditional generation.
Discovering Fine-Grained Semantics in Knowledge Graph Relations
Feb 17, 2022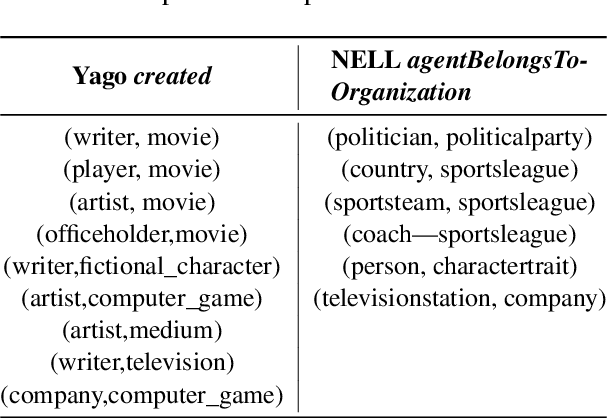
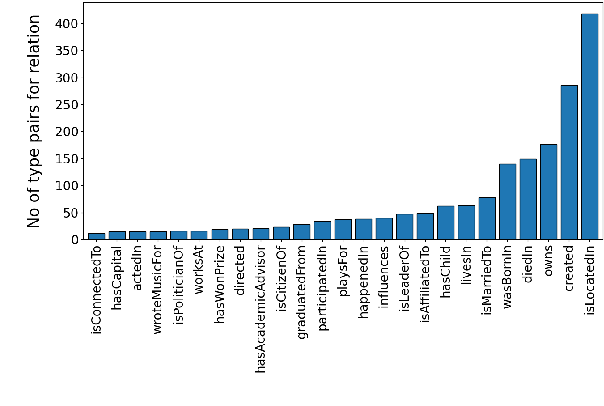
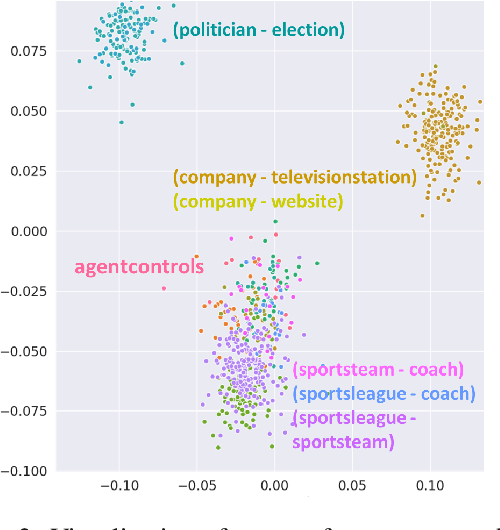
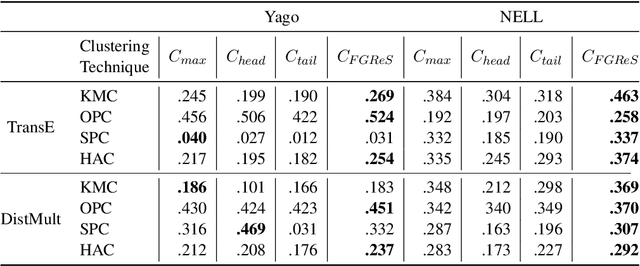
When it comes to comprehending and analyzing multi-relational data, the semantics of relations are crucial. Polysemous relations between different types of entities, that represent multiple semantics, are common in real-world relational datasets represented by knowledge graphs. For numerous use cases, such as entity type classification, question answering and knowledge graph completion, the correct semantic interpretation of these relations is necessary. In this work, we provide a strategy for discovering the different semantics associated with abstract relations and deriving many sub-relations with fine-grained meaning. To do this, we leverage the types of the entities associated with the relations and cluster the vector representations of entities and relations. The suggested method is able to automatically discover the best number of sub-relations for a polysemous relation and determine their semantic interpretation, according to our empirical evaluation.
PatentMatch: A Dataset for Matching Patent Claims & Prior Art
Dec 27, 2020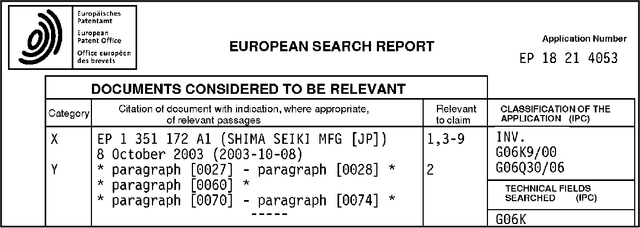
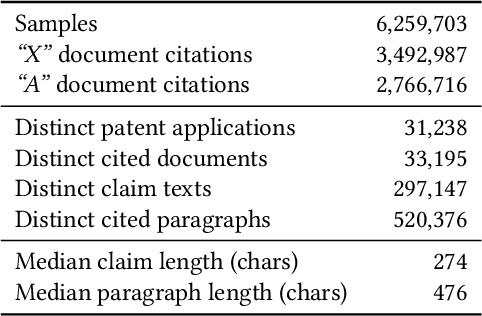
Patent examiners need to solve a complex information retrieval task when they assess the novelty and inventive step of claims made in a patent application. Given a claim, they search for prior art, which comprises all relevant publicly available information. This time-consuming task requires a deep understanding of the respective technical domain and the patent-domain-specific language. For these reasons, we address the computer-assisted search for prior art by creating a training dataset for supervised machine learning called PatentMatch. It contains pairs of claims from patent applications and semantically corresponding text passages of different degrees from cited patent documents. Each pair has been labeled by technically-skilled patent examiners from the European Patent Office. Accordingly, the label indicates the degree of semantic correspondence (matching), i.e., whether the text passage is prejudicial to the novelty of the claimed invention or not. Preliminary experiments using a baseline system show that PatentMatch can indeed be used for training a binary text pair classifier on this challenging information retrieval task. The dataset is available online: https://hpi.de/naumann/s/patentmatch.
Challenges for Toxic Comment Classification: An In-Depth Error Analysis
Sep 20, 2018



Toxic comment classification has become an active research field with many recently proposed approaches. However, while these approaches address some of the task's challenges others still remain unsolved and directions for further research are needed. To this end, we compare different deep learning and shallow approaches on a new, large comment dataset and propose an ensemble that outperforms all individual models. Further, we validate our findings on a second dataset. The results of the ensemble enable us to perform an extensive error analysis, which reveals open challenges for state-of-the-art methods and directions towards pending future research. These challenges include missing paradigmatic context and inconsistent dataset labels.