 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Meaning, Different Scores: Lexical and Syntactic Sensitivity in LLM Evaluation
Feb 19, 2026The rapid advancement of Large Language Models (LLMs) has established standardized evaluation benchmarks as the primary instrument for model comparison. Yet, their reliability is increasingly questioned due to sensitivity to shallow variations in input prompts. This paper examines how controlled, truth-conditionally equivalent lexical and syntactic perturbations affect the absolute performance and relative ranking of 23 contemporary LLMs across three benchmarks: MMLU, SQuAD, and AMEGA. We employ two linguistically principled pipelines to generate meaning-preserving variations: one performing synonym substitution for lexical changes, and another using dependency parsing to determine applicable syntactic transformations. Results show that lexical perturbations consistently induce substantial, statistically significant performance degradation across nearly all models and tasks, while syntactic perturbations have more heterogeneous effects, occasionally improving results. Both perturbation types destabilize model leaderboards on complex tasks. Furthermore, model robustness did not consistently scale with model size, revealing strong task dependence. Overall, the findings suggest that LLMs rely more on surface-level lexical patterns than on abstract linguistic competence, underscoring the need for robustness testing as a standard component of LLM evaluation.
Fabricator: An Open Source Toolkit for Generating Labeled Training Data with Teacher LLMs
Sep 18, 2023



Most NLP tasks are modeled as supervised learning and thus require labeled training data to train effective models. However, manually producing such data at sufficient quality and quantity is known to be costly and time-intensive. Current research addresses this bottleneck by exploring a novel paradigm called zero-shot learning via dataset generation. Here, a powerful LLM is prompted with a task description to generate labeled data that can be used to train a downstream NLP model. For instance, an LLM might be prompted to "generate 500 movie reviews with positive overall sentiment, and another 500 with negative sentiment." The generated data could then be used to train a binary sentiment classifier, effectively leveraging an LLM as a teacher to a smaller student model. With this demo, we introduce Fabricator, an open-source Python toolkit for dataset generation. Fabricator implements common dataset generation workflows, supports a wide range of downstream NLP tasks (such as text classification, question answering, and entity recognition), and is integrated with well-known libraries to facilitate quick experimentation. With Fabricator, we aim to support researchers in conducting reproducible dataset generation experiments using LLMs and help practitioners apply this approach to train models for downstream tasks.
Pseudo-Labels Are All You Need
Aug 19, 2022



Automatically estimating the complexity of texts for readers has a variety of applications, such as recommending texts with an appropriate complexity level to language learners or supporting the evaluation of text simplification approaches. In this paper, we present our submission to the Text Complexity DE Challenge 2022, a regression task where the goal is to predict the complexity of a German sentence for German learners at level B. Our approach relies on more than 220,000 pseudo-labels created from the German Wikipedia and other corpora to train Transformer-based models, and refrains from any feature engineering or any additional, labeled data. We find that the pseudo-label-based approach gives impressive results yet requires little to no adjustment to the specific task and therefore could be easily adapted to other domains and tasks.
Semantic Answer Similarity for Evaluating Question Answering Models
Aug 13, 2021



The evaluation of question answering models compares ground-truth annotations with model predictions. However, as of today, this comparison is mostly lexical-based and therefore misses out on answers that have no lexical overlap but are still semantically similar, thus treating correct answers as false. This underestimation of the true performance of models hinders user acceptance in applications and complicates a fair comparison of different models. Therefore, there is a need for an evaluation metric that is based on semantics instead of pure string similarity. In this short paper, we present SAS, a cross-encoder-based metric for the estimation of semantic answer similarity, and compare it to seven existing metrics. To this end, we create an English and a German three-way annotated evaluation dataset containing pairs of answers along with human judgment of their semantic similarity, which we release along with an implementation of the SAS metric and the experiments. We find that semantic similarity metrics based on recent transformer models correlate much better with human judgment than traditional lexical similarity metrics on our two newly created datasets and one dataset from related work.
Multi-modal Retrieval of Tables and Texts Using Tri-encoder Models
Aug 09, 2021



Open-domain extractive question answering works well on textual data by first retrieving candidate texts and then extracting the answer from those candidates. However, some questions cannot be answered by text alone but require information stored in tables. In this paper, we present an approach for retrieving both texts and tables relevant to a question by jointly encoding texts, tables and questions into a single vector space. To this end, we create a new multi-modal dataset based on text and table datasets from related work and compare the retrieval performance of different encoding schemata. We find that dense vector embeddings of transformer models outperform sparse embeddings on four out of six evaluation datasets. Comparing different dense embedding models, tri-encoders, with one encoder for each question, text and table, increase retrieval performance compared to bi-encoders with one encoder for the question and one for both text and tables. We release the newly created multi-modal dataset to the community so that it can be used for training and evaluation.
GermanQuAD and GermanDPR: Improving Non-English Question Answering and Passage Retrieval
Apr 26, 2021



A major challenge of research on non-English machine reading for question answering (QA) is the lack of annotated datasets. In this paper, we present GermanQuAD, a dataset of 13,722 extractive question/answer pairs. To improve the reproducibility of the dataset creation approach and foster QA research on other languages, we summarize lessons learned and evaluate reformulation of question/answer pairs as a way to speed up the annotation process. An extractive QA model trained on GermanQuAD significantly outperforms multilingual models and also shows that machine-translated training data cannot fully substitute hand-annotated training data in the target language. Finally, we demonstrate the wide range of applications of GermanQuAD by adapting it to GermanDPR, a training dataset for dense passage retrieval (DPR), and train and evaluate the first non-English DPR model.
PatentMatch: A Dataset for Matching Patent Claims & Prior Art
Dec 27, 2020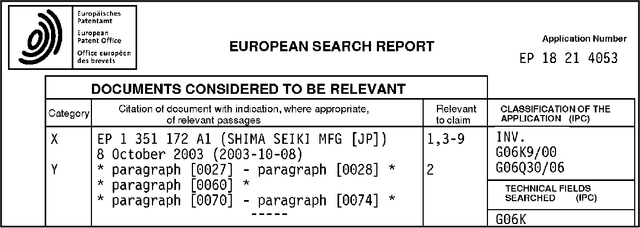
Patent examiners need to solve a complex information retrieval task when they assess the novelty and inventive step of claims made in a patent application. Given a claim, they search for prior art, which comprises all relevant publicly available information. This time-consuming task requires a deep understanding of the respective technical domain and the patent-domain-specific language. For these reasons, we address the computer-assisted search for prior art by creating a training dataset for supervised machine learning called PatentMatch. It contains pairs of claims from patent applications and semantically corresponding text passages of different degrees from cited patent documents. Each pair has been labeled by technically-skilled patent examiners from the European Patent Office. Accordingly, the label indicates the degree of semantic correspondence (matching), i.e., whether the text passage is prejudicial to the novelty of the claimed invention or not. Preliminary experiments using a baseline system show that PatentMatch can indeed be used for training a binary text pair classifier on this challenging information retrieval task. The dataset is available online: https://hpi.de/naumann/s/patentmatch.
Challenges for Toxic Comment Classification: An In-Depth Error Analysis
Sep 20, 2018



Toxic comment classification has become an active research field with many recently proposed approaches. However, while these approaches address some of the task's challenges others still remain unsolved and directions for further research are needed. To this end, we compare different deep learning and shallow approaches on a new, large comment dataset and propose an ensemble that outperforms all individual models. Further, we validate our findings on a second dataset. The results of the ensemble enable us to perform an extensive error analysis, which reveals open challenges for state-of-the-art methods and directions towards pending future research. These challenges include missing paradigmatic context and inconsistent dataset labels.