 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Word Choices, Same Reference: Annotating Lexically-Rich Cross-Document Coreference
Feb 19, 2026Cross-document coreference resolution (CDCR) identifies and links mentions of the same entities and events across related documents, enabling content analysis that aggregates information at the level of discourse participants. However, existing datasets primarily focus on event resolution and employ a narrow definition of coreference, which limits their effectiveness in analyzing diverse and polarized news coverage where wording varies widely. This paper proposes a revised CDCR annotation scheme of the NewsWCL50 dataset, treating coreference chains as discourse elements (DEs) and conceptual units of analysis. The approach accommodates both identity and near-identity relations, e.g., by linking "the caravan" - "asylum seekers" - "those contemplating illegal entry", allowing models to capture lexical diversity and framing variation in media discourse, while maintaining the fine-grained annotation of DEs. We reannotate the NewsWCL50 and a subset of ECB+ using a unified codebook and evaluate the new datasets through lexical diversity metrics and a same-head-lemma baseline. The results show that the reannotated datasets align closely, falling between the original ECB+ and NewsWCL50, thereby supporting balanced and discourse-aware CDCR research in the news domain.
Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning
Oct 19, 2024Intermediate task transfer learning can greatly improve model performance. If, for example, one has little training data for emotion detection, first fine-tuning a language model on a sentiment classification dataset may improve performance strongly. But which task to choose for transfer learning? Prior methods producing useful task rankings are infeasible for large source pools, as they require forward passes through all source language models. We overcome this by introducing Embedding Space Maps (ESMs), light-weight neural networks that approximate the effect of fine-tuning a language model. We conduct the largest study on NLP task transferability and task selection with 12k source-target pairs. We find that applying ESMs on a prior method reduces execution time and disk space usage by factors of 10 and 278, respectively, while retaining high selection performance (avg. regret@5 score of 2.95).
Large-Scale Label Interpretation Learning for Few-Shot Named Entity Recognition
Mar 21, 2024



Few-shot named entity recognition (NER) detects named entities within text using only a few annotated examples. One promising line of research is to leverage natural language descriptions of each entity type: the common label PER might, for example, be verbalized as ''person entity.'' In an initial label interpretation learning phase, the model learns to interpret such verbalized descriptions of entity types. In a subsequent few-shot tagset extension phase, this model is then given a description of a previously unseen entity type (such as ''music album'') and optionally a few training examples to perform few-shot NER for this type. In this paper, we systematically explore the impact of a strong semantic prior to interpret verbalizations of new entity types by massively scaling up the number and granularity of entity types used for label interpretation learning. To this end, we leverage an entity linking benchmark to create a dataset with orders of magnitude of more distinct entity types and descriptions as currently used datasets. We find that this increased signal yields strong results in zero- and few-shot NER in in-domain, cross-domain, and even cross-lingual settings. Our findings indicate significant potential for improving few-shot NER through heuristical data-based optimization.
Fabricator: An Open Source Toolkit for Generating Labeled Training Data with Teacher LLMs
Sep 18, 2023



Most NLP tasks are modeled as supervised learning and thus require labeled training data to train effective models. However, manually producing such data at sufficient quality and quantity is known to be costly and time-intensive. Current research addresses this bottleneck by exploring a novel paradigm called zero-shot learning via dataset generation. Here, a powerful LLM is prompted with a task description to generate labeled data that can be used to train a downstream NLP model. For instance, an LLM might be prompted to "generate 500 movie reviews with positive overall sentiment, and another 500 with negative sentiment." The generated data could then be used to train a binary sentiment classifier, effectively leveraging an LLM as a teacher to a smaller student model. With this demo, we introduce Fabricator, an open-source Python toolkit for dataset generation. Fabricator implements common dataset generation workflows, supports a wide range of downstream NLP tasks (such as text classification, question answering, and entity recognition), and is integrated with well-known libraries to facilitate quick experimentation. With Fabricator, we aim to support researchers in conducting reproducible dataset generation experiments using LLMs and help practitioners apply this approach to train models for downstream tasks.
Do You Think It's Biased? How To Ask For The Perception Of Media Bias
Dec 16, 2021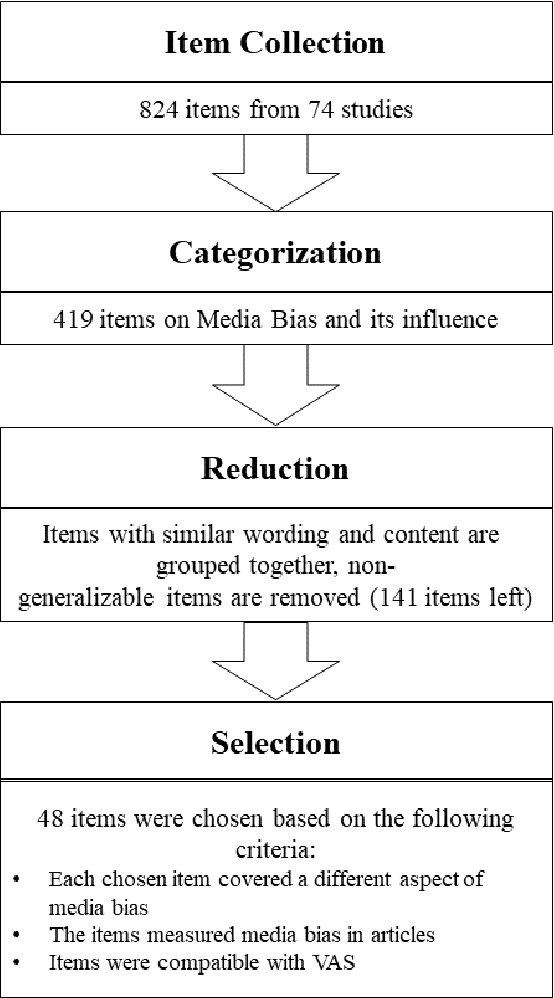
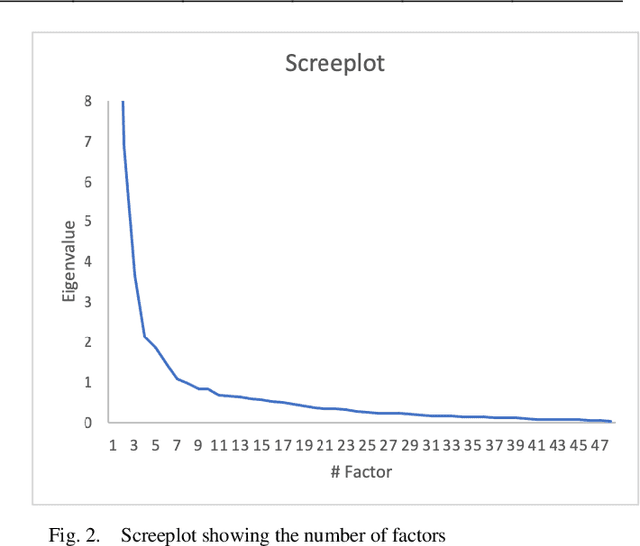

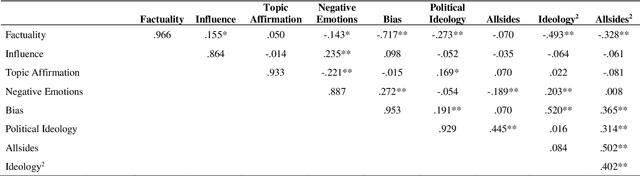
Media coverage possesses a substantial effect on the public perception of events. The way media frames events can significantly alter the beliefs and perceptions of our society. Nevertheless, nearly all media outlets are known to report news in a biased way. While such bias can be introduced by altering the word choice or omitting information, the perception of bias also varies largely depending on a reader's personal background. Therefore, media bias is a very complex construct to identify and analyze. Even though media bias has been the subject of many studies, previous assessment strategies are oversimplified, lack overlap and empirical evaluation. Thus, this study aims to develop a scale that can be used as a reliable standard to evaluate article bias. To name an example: Intending to measure bias in a news article, should we ask, "How biased is the article?" or should we instead ask, "How did the article treat the American president?". We conducted a literature search to find 824 relevant questions about text perception in previous research on the topic. In a multi-iterative process, we summarized and condensed these questions semantically to conclude a complete and representative set of possible question types about bias. The final set consisted of 25 questions with varying answering formats, 17 questions using semantic differentials, and six ratings of feelings. We tested each of the questions on 190 articles with overall 663 participants to identify how well the questions measure an article's perceived bias. Our results show that 21 final items are suitable and reliable for measuring the perception of media bias. We publish the final set of questions on http://bias-question-tree.gipplab.org/.
Assisted Text Annotation Using Active Learning to Achieve High Quality with Little Effort
Dec 15, 2021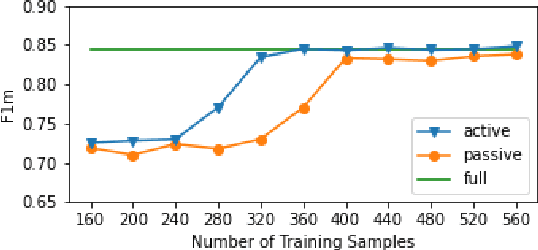
Large amounts of annotated data have become more important than ever, especially since the rise of deep learning techniques. However, manual annotations are costly. We propose a tool that enables researchers to create large, high-quality, annotated datasets with only a few manual annotations, thus strongly reducing annotation cost and effort. For this purpose, we combine an active learning (AL) approach with a pre-trained language model to semi-automatically identify annotation categories in the given text documents. To highlight our research direction's potential, we evaluate the approach on the task of identifying frames in news articles. Our preliminary results show that employing AL strongly reduces the number of annotations for correct classification of even these complex and subtle frames. On the framing dataset, the AL approach needs only 16.3\% of the annotations to reach the same performance as a model trained on the full dataset.
Identification of Biased Terms in News Articles by Comparison of Outlet-specific Word Embeddings
Dec 14, 2021
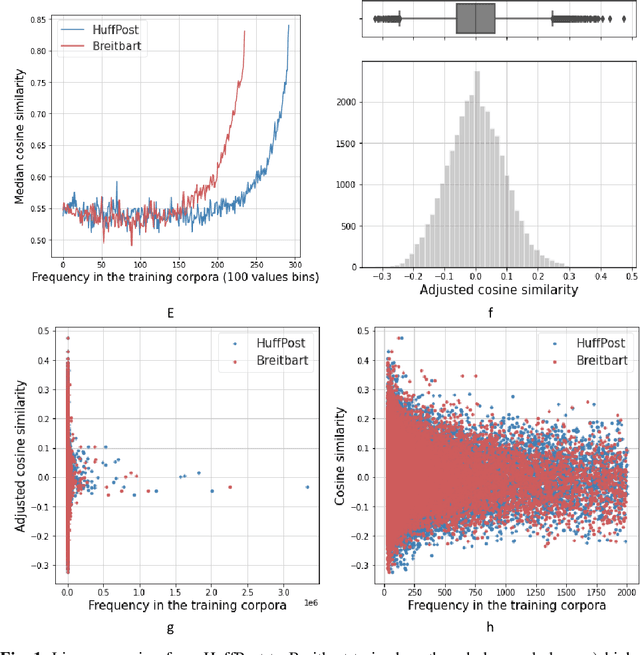

Slanted news coverage, also called media bias, can heavily influence how news consumers interpret and react to the news. To automatically identify biased language, we present an exploratory approach that compares the context of related words. We train two word embedding models, one on texts of left-wing, the other on right-wing news outlets. Our hypothesis is that a word's representations in both word embedding spaces are more similar for non-biased words than biased words. The underlying idea is that the context of biased words in different news outlets varies more strongly than the one of non-biased words, since the perception of a word as being biased differs depending on its context. While we do not find statistical significance to accept the hypothesis, the results show the effectiveness of the approach. For example, after a linear mapping of both word embeddings spaces, 31% of the words with the largest distances potentially induce bias. To improve the results, we find that the dataset needs to be significantly larger, and we derive further methodology as future research direction. To our knowledge, this paper presents the first in-depth look at the context of bias words measured by word embeddings.
ANEA: Automated (Named) Entity Annotation for German Domain-Specific Texts
Dec 13, 2021


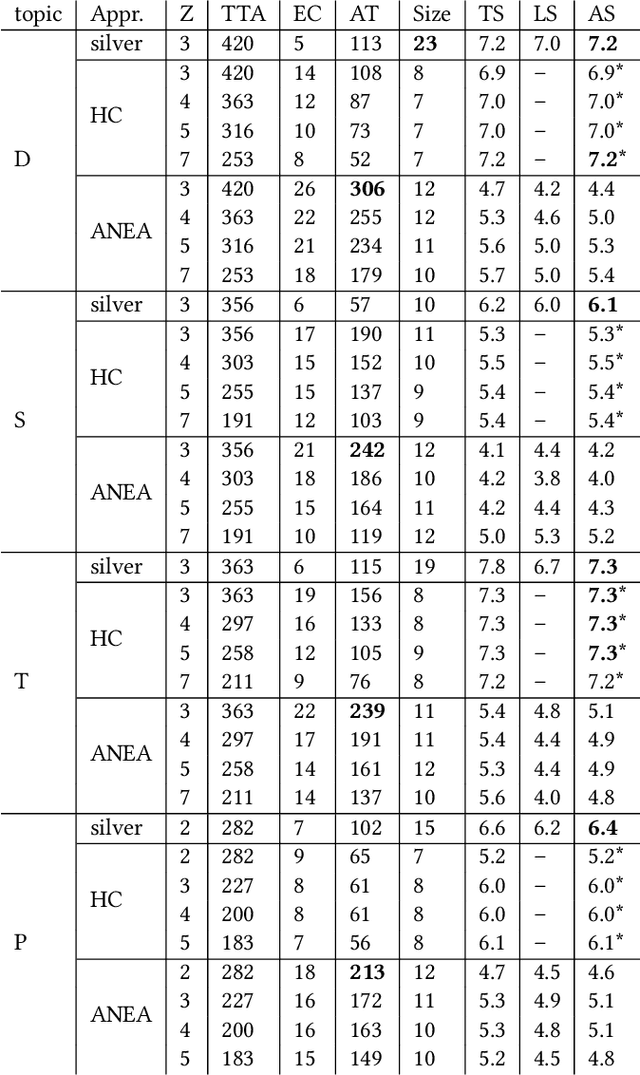
Named entity recognition (NER) is an important task that aims to resolve universal categories of named entities, e.g., persons, locations, organizations, and times. Despite its common and viable use in many use cases, NER is barely applicable in domains where general categories are suboptimal, such as engineering or medicine. To facilitate NER of domain-specific types, we propose ANEA, an automated (named) entity annotator to assist human annotators in creating domain-specific NER corpora for German text collections when given a set of domain-specific texts. In our evaluation, we find that ANEA automatically identifies terms that best represent the texts' content, identifies groups of coherent terms, and extracts and assigns descriptive labels to these groups, i.e., annotates text datasets into the domain (named) entities.
Newsalyze: Effective Communication of Person-Targeting Biases in News Articles
Oct 18, 2021



Media bias and its extreme form, fake news, can decisively affect public opinion. Especially when reporting on policy issues, slanted news coverage may strongly influence societal decisions, e.g., in democratic elections. Our paper makes three contributions to address this issue. First, we present a system for bias identification, which combines state-of-the-art methods from natural language understanding. Second, we devise bias-sensitive visualizations to communicate bias in news articles to non-expert news consumers. Third, our main contribution is a large-scale user study that measures bias-awareness in a setting that approximates daily news consumption, e.g., we present respondents with a news overview and individual articles. We not only measure the visualizations' effect on respondents' bias-awareness, but we can also pinpoint the effects on individual components of the visualizations by employing a conjoint design. Our bias-sensitive overviews strongly and significantly increase bias-awareness in respondents. Our study further suggests that our content-driven identification method detects groups of similarly slanted news articles due to substantial biases present in individual news articles. In contrast, the reviewed prior work rather only facilitates the visibility of biases, e.g., by distinguishing left- and right-wing outlets.
How to Effectively Identify and Communicate Person-Targeting Media Bias in Daily News Consumption?
Oct 18, 2021

Slanted news coverage strongly affects public opinion. This is especially true for coverage on politics and related issues, where studies have shown that bias in the news may influence elections and other collective decisions. Due to its viable importance, news coverage has long been studied in the social sciences, resulting in comprehensive models to describe it and effective yet costly methods to analyze it, such as content analysis. We present an in-progress system for news recommendation that is the first to automate the manual procedure of content analysis to reveal person-targeting biases in news articles reporting on policy issues. In a large-scale user study, we find very promising results regarding this interdisciplinary research direction. Our recommender detects and reveals substantial frames that are actually present in individual news articles. In contrast, prior work rather only facilitates the visibility of biases, e.g., by distinguishing left- and right-wing outlets. Further, our study shows that recommending news articles that differently frame an event significantly improves respondents' awareness of bias.