 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Persona, Many Cues, Different Results: How Sociodemographic Cues Impact LLM Personalization
Jan 26, 2026Personalization of LLMs by sociodemographic subgroup often improves user experience, but can also introduce or amplify biases and unfair outcomes across groups. Prior work has employed so-called personas, sociodemographic user attributes conveyed to a model, to study bias in LLMs by relying on a single cue to prompt a persona, such as user names or explicit attribute mentions. This disregards LLM sensitivity to prompt variations (robustness) and the rarity of some cues in real interactions (external validity). We compare six commonly used persona cues across seven open and proprietary LLMs on four writing and advice tasks. While cues are overall highly correlated, they produce substantial variance in responses across personas. We therefore caution against claims from a single persona cue and recommend future personalization research to evaluate multiple externally valid cues.
Beyond Marginal Distributions: A Framework to Evaluate the Representativeness of Demographic-Aligned LLMs
Jan 22, 2026Large language models are increasingly used to represent human opinions, values, or beliefs, and their steerability towards these ideals is an active area of research. Existing work focuses predominantly on aligning marginal response distributions, treating each survey item independently. While essential, this may overlook deeper latent structures that characterise real populations and underpin cultural values theories. We propose a framework for evaluating the representativeness of aligned models through multivariate correlation patterns in addition to marginal distributions. We show the value of our evaluation scheme by comparing two model steering techniques (persona prompting and demographic fine-tuning) and evaluating them against human responses from the World Values Survey. While the demographically fine-tuned model better approximates marginal response distributions than persona prompting, both techniques fail to fully capture the gold standard correlation patterns. We conclude that representativeness is a distinct aspect of value alignment and an evaluation focused on marginals can mask structural failures, leading to overly optimistic conclusions about model capabilities.
PRSM: A Measure to Evaluate CLIP's Robustness Against Paraphrases
Nov 14, 2025Contrastive Language-Image Pre-training (CLIP) is a widely used multimodal model that aligns text and image representations through large-scale training. While it performs strongly on zero-shot and few-shot tasks, its robustness to linguistic variation, particularly paraphrasing, remains underexplored. Paraphrase robustness is essential for reliable deployment, especially in socially sensitive contexts where inconsistent representations can amplify demographic biases. In this paper, we introduce the Paraphrase Ranking Stability Metric (PRSM), a novel measure for quantifying CLIP's sensitivity to paraphrased queries. Using the Social Counterfactuals dataset, a benchmark designed to reveal social and demographic biases, we empirically assess CLIP's stability under paraphrastic variation, examine the interaction between paraphrase robustness and gender, and discuss implications for fairness and equitable deployment of multimodal systems. Our analysis reveals that robustness varies across paraphrasing strategies, with subtle yet consistent differences observed between male- and female-associated queries.
Do Political Opinions Transfer Between Western Languages? An Analysis of Unaligned and Aligned Multilingual LLMs
Aug 07, 2025Public opinion surveys show cross-cultural differences in political opinions between socio-cultural contexts. However, there is no clear evidence whether these differences translate to cross-lingual differences in multilingual large language models (MLLMs). We analyze whether opinions transfer between languages or whether there are separate opinions for each language in MLLMs of various sizes across five Western languages. We evaluate MLLMs' opinions by prompting them to report their (dis)agreement with political statements from voting advice applications. To better understand the interaction between languages in the models, we evaluate them both before and after aligning them with more left or right views using direct preference optimization and English alignment data only. Our findings reveal that unaligned models show only very few significant cross-lingual differences in the political opinions they reflect. The political alignment shifts opinions almost uniformly across all five languages. We conclude that in Western language contexts, political opinions transfer between languages, demonstrating the challenges in achieving explicit socio-linguistic, cultural, and political alignment of MLLMs.
Assisted Text Annotation Using Active Learning to Achieve High Quality with Little Effort
Dec 15, 2021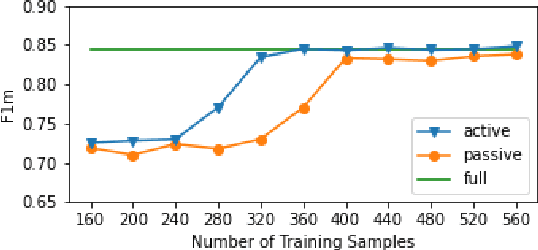
Large amounts of annotated data have become more important than ever, especially since the rise of deep learning techniques. However, manual annotations are costly. We propose a tool that enables researchers to create large, high-quality, annotated datasets with only a few manual annotations, thus strongly reducing annotation cost and effort. For this purpose, we combine an active learning (AL) approach with a pre-trained language model to semi-automatically identify annotation categories in the given text documents. To highlight our research direction's potential, we evaluate the approach on the task of identifying frames in news articles. Our preliminary results show that employing AL strongly reduces the number of annotations for correct classification of even these complex and subtle frames. On the framing dataset, the AL approach needs only 16.3\% of the annotations to reach the same performance as a model trained on the full dataset.