 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Persona, Many Cues, Different Results: How Sociodemographic Cues Impact LLM Personalization
Jan 26, 2026Personalization of LLMs by sociodemographic subgroup often improves user experience, but can also introduce or amplify biases and unfair outcomes across groups. Prior work has employed so-called personas, sociodemographic user attributes conveyed to a model, to study bias in LLMs by relying on a single cue to prompt a persona, such as user names or explicit attribute mentions. This disregards LLM sensitivity to prompt variations (robustness) and the rarity of some cues in real interactions (external validity). We compare six commonly used persona cues across seven open and proprietary LLMs on four writing and advice tasks. While cues are overall highly correlated, they produce substantial variance in responses across personas. We therefore caution against claims from a single persona cue and recommend future personalization research to evaluate multiple externally valid cues.
Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization
May 22, 2025Generative Large Language Models (LLMs) infer user's demographic information from subtle cues in the conversation -- a phenomenon called implicit personalization. Prior work has shown that such inferences can lead to lower quality responses for users assumed to be from minority groups, even when no demographic information is explicitly provided. In this work, we systematically explore how LLMs respond to stereotypical cues using controlled synthetic conversations, by analyzing the models' latent user representations through both model internals and generated answers to targeted user questions. Our findings reveal that LLMs do infer demographic attributes based on these stereotypical signals, which for a number of groups even persists when the user explicitly identifies with a different demographic group. Finally, we show that this form of stereotype-driven implicit personalization can be effectively mitigated by intervening on the model's internal representations using a trained linear probe to steer them toward the explicitly stated identity. Our results highlight the need for greater transparency and control in how LLMs represent user identity.
Cross-Lingual Transfer of Debiasing and Detoxification in Multilingual LLMs: An Extensive Investigation
Dec 18, 2024
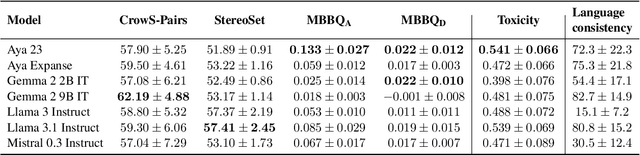
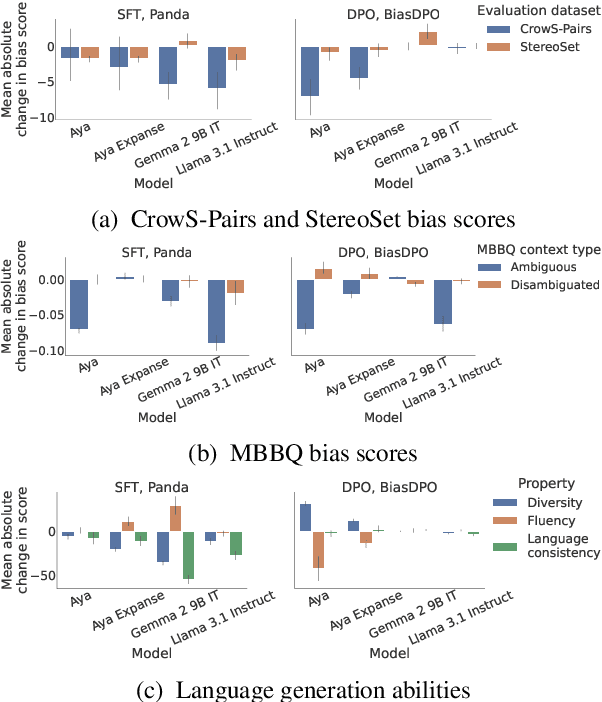

Recent generative large language models (LLMs) show remarkable performance in non-English languages, but when prompted in those languages they tend to express higher harmful social biases and toxicity levels. Prior work has shown that finetuning on specialized datasets can mitigate this behavior, and doing so in English can transfer to other languages. In this work, we investigate the impact of different finetuning methods on the model's bias and toxicity, but also on its ability to produce fluent and diverse text. Our results show that finetuning on curated non-harmful text is more effective for mitigating bias, and finetuning on direct preference optimization (DPO) datasets is more effective for mitigating toxicity. The mitigation caused by applying these methods in English also transfers to non-English languages. We find evidence that the extent to which transfer takes place can be predicted by the amount of data in a given language present in the model's pretraining data. However, this transfer of bias and toxicity mitigation often comes at the expense of decreased language generation ability in non-English languages, highlighting the importance of developing language-specific bias and toxicity mitigation methods.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024
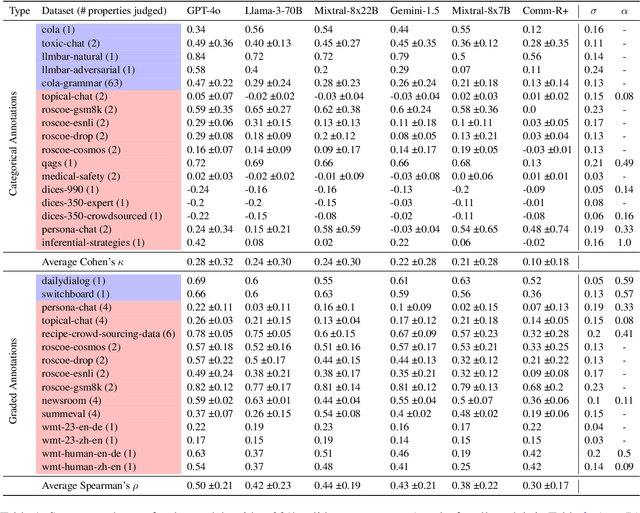
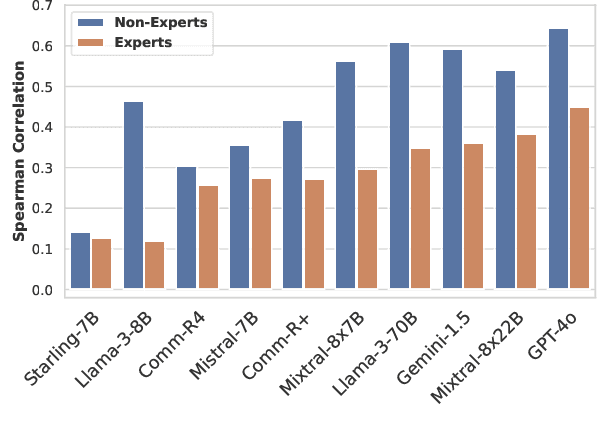
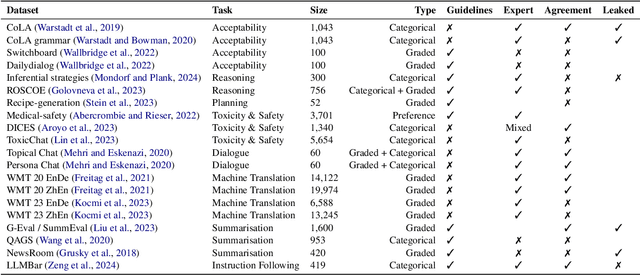
There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
MBBQ: A Dataset for Cross-Lingual Comparison of Stereotypes in Generative LLMs
Jun 11, 2024



Generative large language models (LLMs) have been shown to exhibit harmful biases and stereotypes. While safety fine-tuning typically takes place in English, if at all, these models are being used by speakers of many different languages. There is existing evidence that the performance of these models is inconsistent across languages and that they discriminate based on demographic factors of the user. Motivated by this, we investigate whether the social stereotypes exhibited by LLMs differ as a function of the language used to prompt them, while controlling for cultural differences and task accuracy. To this end, we present MBBQ (Multilingual Bias Benchmark for Question-answering), a carefully curated version of the English BBQ dataset extended to Dutch, Spanish, and Turkish, which measures stereotypes commonly held across these languages. We further complement MBBQ with a parallel control dataset to measure task performance on the question-answering task independently of bias. Our results based on several open-source and proprietary LLMs confirm that some non-English languages suffer from bias more than English, even when controlling for cultural shifts. Moreover, we observe significant cross-lingual differences in bias behaviour for all except the most accurate models. With the release of MBBQ, we hope to encourage further research on bias in multilingual settings. The dataset and code are available at https://github.com/Veranep/MBBQ.